@rob_farley uw recente stackoverflow-oplossing om eerst op een waarde te bestellen en daarna een veld genie! Wilde je persoonlijk bedanken.
— Joel Sacco (@Jsac90) 11 augustus 2016
Ik zag deze tweet aankomen...
En het deed me kijken waar het naar verwees, omdat ik 'recent' niets op StackOverflow had geschreven over het bestellen van gegevens. Het bleek dit antwoord te zijn dat ik had geschreven , wat niet het geaccepteerde antwoord was, maar meer dan honderd stemmen heeft verzameld.
De persoon die de vraag stelde, had een heel eenvoudig probleem:hij wilde bepaalde rijen als eerste laten verschijnen. En mijn oplossing was simpel:
ORDER BY CASE WHEN city = 'New York' THEN 1 ELSE 2 END, City;
Het lijkt een populair antwoord te zijn geweest, ook voor Joel Sacco (volgens die tweet hierboven).
Het idee is om een uitdrukking te vormen, en daardoor te ordenen. ORDER BY maakt het niet uit of het een echte kolom is of niet. U had hetzelfde kunnen doen met APPLY, als u echt de voorkeur geeft aan een 'kolom' in uw ORDER BY-clausule.
SELECT Users.* FROM Users CROSS APPLY ( SELECT CASE WHEN City = 'New York' THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, City;
Als ik een aantal zoekopdrachten tegen WideWorldImporters gebruik, kan ik je laten zien waarom deze twee zoekopdrachten echt precies hetzelfde zijn. Ik ga de tabel Sales.Orders doorzoeken en vraag of de Orders voor Verkoper 7 als eerste verschijnen. Ik ga ook een geschikte dekkingsindex maken:
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID) INCLUDE (OrderDate);
De plannen voor deze twee zoekopdrachten zien er identiek uit. Ze presteren identiek - dezelfde reads, dezelfde expressies, ze zijn echt dezelfde query. Als er een klein verschil is in de werkelijke CPU of duur, dan is dat een toevalstreffer vanwege andere factoren.
SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders ORDER BY CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END, SalespersonPersonID; SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders CROSS APPLY ( SELECT CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, SalespersonPersonID;
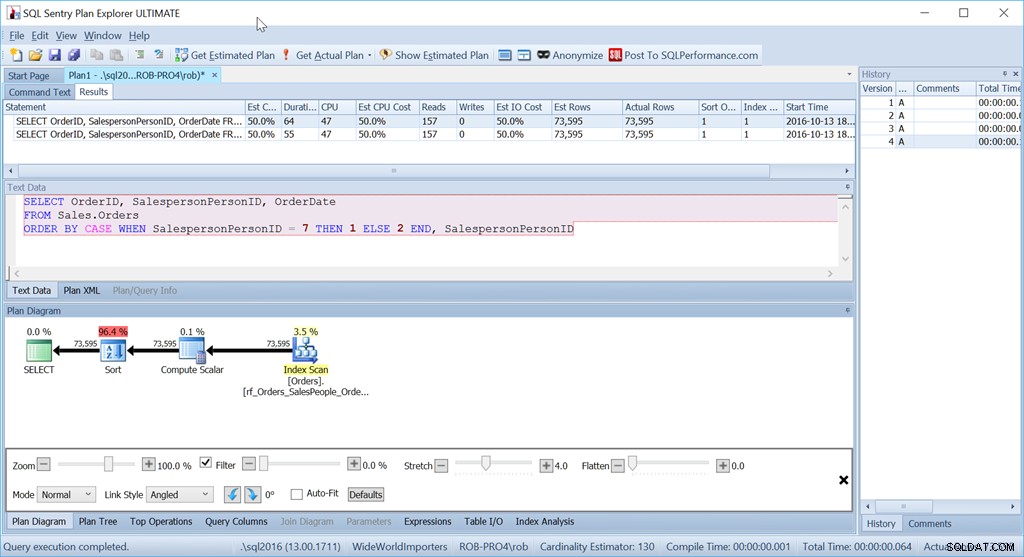
En toch is dit niet de query die ik in deze situatie zou gebruiken. Niet als prestaties belangrijk voor me waren. (Dat is meestal zo, maar het is niet altijd de moeite waard om een lange zoekopdracht te schrijven als de hoeveelheid gegevens klein is.)
Wat me stoort is die sorteeroperator. Het is 96,4% van de kosten!
Overweeg of we gewoon willen bestellen via SalespersonPersonID:
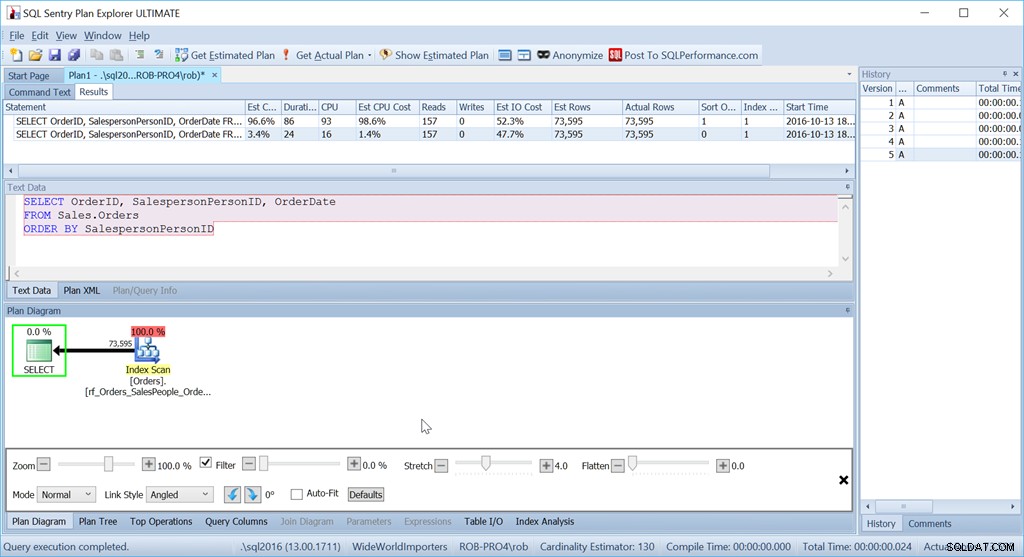
We zien dat de geschatte CPU-kosten van deze eenvoudigere query 1,4% van de batch zijn, terwijl de op maat gesorteerde versie 98,6% is. Dat is ZEVENTIG KEER erger. Lezingen zijn echter hetzelfde - dat is goed. De duur is veel slechter, en dat geldt ook voor de CPU.
Ik ben niet dol op Sorts. Ze kunnen gemeen zijn.
Een optie die ik hier heb, is om een berekende kolom aan mijn tabel toe te voegen en die te indexeren, maar dat heeft invloed op alles dat naar alle kolommen in de tabel zoekt, zoals ORM's, Power BI of iets dat SELECT * . Dus dat is niet zo geweldig (hoewel als we ooit verborgen berekende kolommen kunnen toevoegen, dat hier een hele leuke optie zou zijn).
Een andere optie, die meer langdradig is (sommigen zouden kunnen suggereren dat dat bij mij zou passen – en als je dat dacht:Oi! Wees niet zo onbeleefd!), en meer leest, is om te overwegen wat we in het echte leven zouden doen als we moesten dit doen.
Als ik een stapel van 73.595 bestellingen had, gesorteerd op bestelling van verkoper, en ik zou ze eerst met een bepaalde verkoper moeten retourneren, zou ik de volgorde waarin ze zich bevonden niet negeren en ze gewoon allemaal sorteren, ik zou beginnen met erin te duiken en die voor verkoper 7 vinden - ze in de volgorde houden waarin ze zich bevonden. Dan zou ik degenen vinden die niet degenen waren die niet van verkoper 7 waren - ze als volgende plaatsen en ze opnieuw in de volgorde houden waarin ze al waren in.
In T-SQL gaat dat als volgt:
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID; Hiermee worden twee sets gegevens opgehaald en samengevoegd. Maar de Query Optimizer kan zien dat het de SalespersonPersonID-volgorde moet behouden, zodra de twee sets aaneengeschakeld zijn, dus het doet een speciaal soort aaneenschakeling die die volgorde handhaaft. Het is een Merge Join (Concatenation) join, en het plan ziet er als volgt uit:
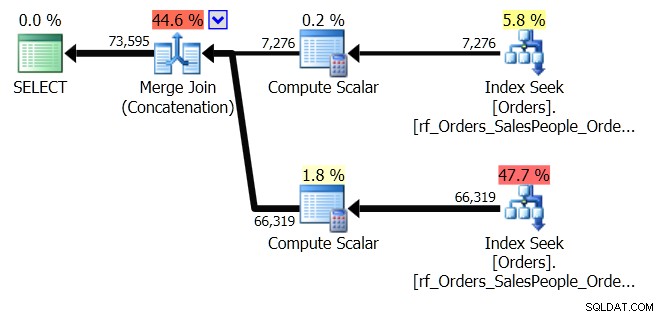
Je ziet dat het een stuk ingewikkelder is. Maar hopelijk merk je ook dat er geen sorteeroperator is. De Merge Join (Concatenation) haalt de gegevens uit elke vertakking en produceert een gegevensset die in de juiste volgorde staat. In dit geval worden eerst alle 7.276 rijen voor verkoper 7 opgehaald en vervolgens de andere 66.319, omdat dat de vereiste volgorde is. Binnen elke set bevinden de gegevens zich in de SalespersonPersonID-volgorde, die wordt bijgehouden terwijl de gegevens erdoorheen stromen.
Ik zei eerder dat het meer reads gebruikt, en dat doet het ook. Als ik de SET STATISTICS IO-uitvoer laat zien en de twee query's vergelijk, zie ik dit:
Tafel 'Werktafel'. Scan count 0, logische leest 0, fysieke leest 0, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.Tabel 'Orders'. Scan count 1, logische leest 157, fysieke leest 0, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
Tabel 'Orders '. Scan count 3, logische leest 163, fysieke leest 0, read-ahead leest 0, lob logische leest 0, lob fysieke leest 0, lob read-ahead leest 0.
Bij gebruik van de versie "Aangepaste sortering" is het slechts één scan van de index, met 157 uitlezingen. Bij gebruik van de "Union All"-methode zijn het drie scans:één voor SalespersonPersonID =7, één voor SalespersonPersonID <7 en één voor SalespersonPersonID> 7. We kunnen die laatste twee zien door naar de eigenschappen van de tweede Index Seek te kijken:
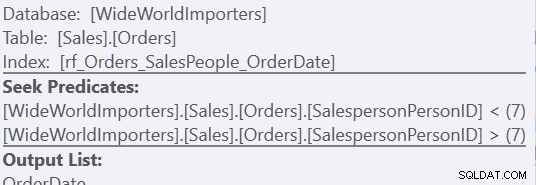
Voor mij komt het voordeel echter tot uiting in het ontbreken van een werktafel.
Kijk naar de geschatte CPU-kosten:

Het is niet zo klein als onze 1,4% wanneer we de sortering volledig vermijden, maar het is nog steeds een enorme verbetering ten opzichte van onze aangepaste sorteermethode.
Maar een woord van waarschuwing...
Stel dat ik die index anders had gemaakt en OrderDate als sleutelkolom had in plaats van als opgenomen kolom.
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID, OrderDate);
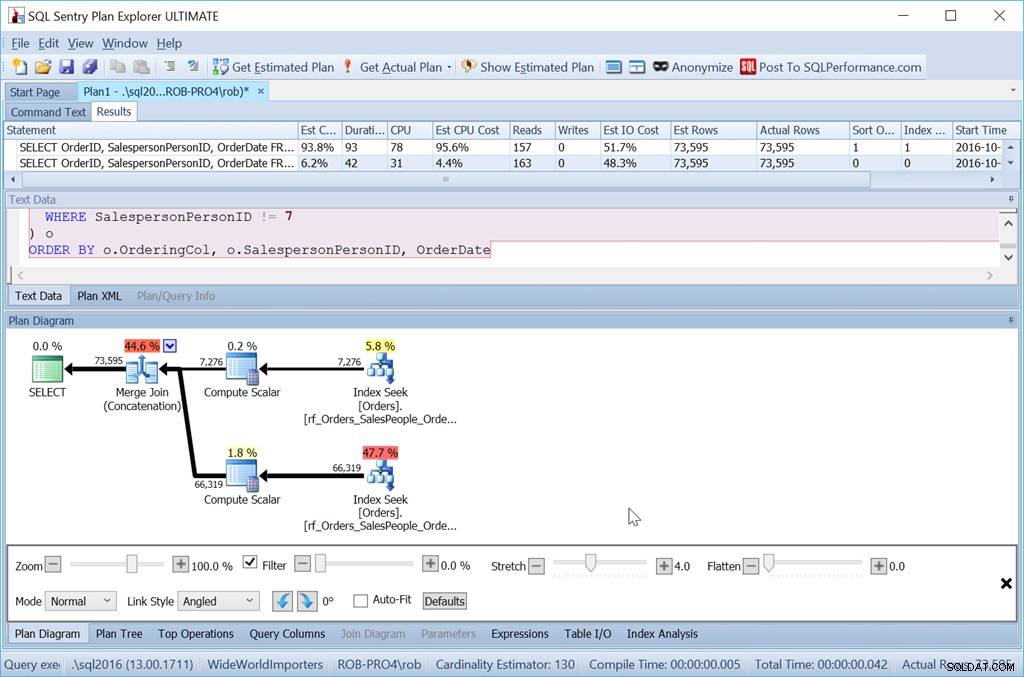
Nu werkt mijn "Union All"-methode helemaal niet zoals bedoeld.
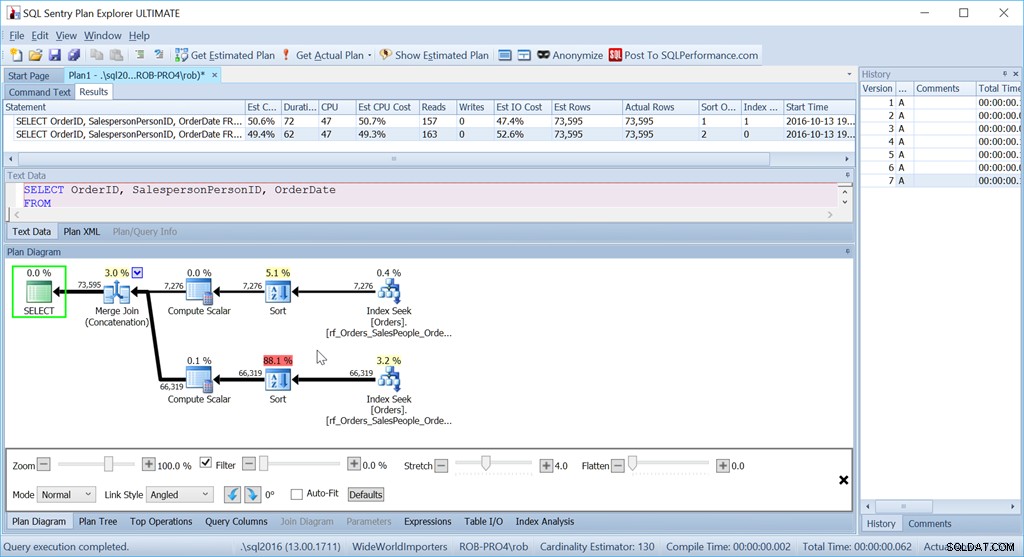
Ondanks het gebruik van exact dezelfde zoekopdrachten als voorheen, heeft mijn mooie plan nu twee sorteeroperatoren, en het presteert bijna net zo slecht als mijn originele Scan + Sort-versie.
De reden hiervoor is een eigenaardigheid van de operator Samenvoegen (aaneenschakeling) en de aanwijzing zit in de operator Sorteren.

Het is bestellen op SalespersonPersonID gevolgd door OrderID - de geclusterde indexsleutel van de tabel. Het kiest dit omdat bekend is dat dit uniek is, en het is een kleinere set kolommen om op te sorteren dan SalespersonPersonID gevolgd door OrderDate gevolgd door OrderID, wat de datasetvolgorde is die wordt geproduceerd door drie indexbereikscans. Een van die momenten waarop de Query Optimizer geen betere optie opmerkt.
Met deze index hebben we onze dataset ook nodig die is geordend op OrderDate om ons voorkeursplan te produceren.
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID, OrderDate;
Het is dus zeker meer moeite. De query is langer voor mij om te schrijven, hij is meer gelezen en ik moet een index hebben zonder extra sleutelkolommen. Maar het is zeker sneller. Met nog meer rijen is de impact nog groter, en ik hoef ook niet het risico te lopen dat een sortering naar tempdb wordt gemorst.
Voor kleine sets is mijn StackOverflow-antwoord nog steeds goed. Maar als die sorteeroperator me in prestaties kost, dan ga ik voor de Union All / Merge Join (Concatenation) -methode.