Over het algemeen is de beste soort Sortering er een die volledig wordt vermeden. Met zorgvuldige indexering en soms wat creatief schrijven van query's, kunnen we vaak de noodzaak voor een sorteeroperator uit uitvoeringsplannen verwijderen. Als de te sorteren gegevens groot zijn, kan het vermijden van dit soort sorteren zeer significante prestatieverbeteringen opleveren.
De op één na beste soort Sorteren is degene die we niet kunnen vermijden, maar die een geschikte hoeveelheid geheugen reserveert en alles of het grootste deel ervan gebruikt om iets waardevols te doen. de moeite waard zijn kan vele vormen aannemen. Soms kan een Sort zichzelf meer dan terugbetalen door een latere bewerking mogelijk te maken die veel efficiënter werkt op gesorteerde invoer. Andere keren is het sorteren gewoon noodzakelijk, en we moeten het gewoon zo efficiënt mogelijk maken.
Dan komen de soorten die we gewoonlijk willen vermijden:degenen die veel meer geheugen reserveren dan ze nodig hebben, en degenen die te weinig reserveren. Het laatste geval is degene waar de meeste mensen zich op concentreren. Als er onvoldoende geheugen is gereserveerd (of beschikbaar) om de vereiste sorteerbewerking in het geheugen te voltooien, zal een sorteeroperator, op enkele uitzonderingen na, gegevensrijen overslaan naar tempdb . In werkelijkheid betekent dit bijna altijd het schrijven van sorteerpagina's naar fysieke opslag (en ze later teruglezen natuurlijk).
In moderne versies van SQL Server resulteert een gemorste sortering in een waarschuwingspictogram in plannen na de uitvoering, die details kunnen bevatten over hoeveel gegevens zijn gemorst, hoeveel threads erbij betrokken waren en het niveau van lekkage.
Achtergrond:morsingsniveaus
Overweeg de taak om 4000 MB aan gegevens te sorteren, terwijl we slechts 500 MB geheugen beschikbaar hebben. Het is duidelijk dat we niet de hele set in één keer in het geheugen kunnen sorteren, maar we kunnen de taak wel opsplitsen:
We lezen eerst 500 MB aan gegevens, sorteren die set in het geheugen en schrijven het resultaat vervolgens naar schijf. Als u dit in totaal 8 keer uitvoert, wordt de volledige invoer van 4000 MB verbruikt, wat resulteert in 8 sets gesorteerde gegevens van 500 MB. De tweede stap is het uitvoeren van een 8-wegs samenvoeging van de gesorteerde datasets. Merk op dat een samenvoegen is vereist, geen eenvoudige aaneenschakeling van de sets, aangezien de gegevens alleen gegarandeerd worden gesorteerd zoals vereist binnen een bepaalde 500 MB die in de tussenfase is ingesteld.
In principe zouden we rij voor rij kunnen lezen en samenvoegen van elk van de acht sorteerruns, maar dit zou niet erg efficiënt zijn. In plaats daarvan lezen we dat het eerste deel van elke soort terugkomt in het geheugen, zeg 60 MB. Dit verbruikt 8 x 60 MB =480 MB van de 500 MB die we beschikbaar hebben. We kunnen dan de 8-wegs samenvoeging in het geheugen een tijdje efficiënt uitvoeren, waarbij de uiteindelijke gesorteerde uitvoer wordt gebufferd met het nog beschikbare 20 MB geheugen. Terwijl elk van de geheugenbuffers van de soort wordt leeggemaakt, lezen we een nieuwe sectie van die soort die in het geheugen loopt. Zodra alle sorteerruns zijn verbruikt, is de sortering voltooid.
Er zijn enkele aanvullende details en optimalisaties die we kunnen opnemen, maar dat is de basisstructuur van een lekkage van niveau 1, ook wel een single-pass lekkage genoemd. Een enkele extra passage over de gegevens is nodig om de uiteindelijke gesorteerde uitvoer te produceren.
Nu zou een n-way merge theoretisch een soort van elke grootte, in elke hoeveelheid geheugen kunnen accommoderen, simpelweg door het aantal tussenliggende lokaal gesorteerde sets te vergroten. Het probleem is dat naarmate 'n' toeneemt, we uiteindelijk kleinere hoeveelheden gegevens lezen en schrijven. Als u bijvoorbeeld 400 GB aan gegevens in 500 MB geheugen sorteert, betekent dit zoiets als een samenvoeging in 800 richtingen, waarbij slechts ongeveer 0,6 MB van elke tussenliggende gesorteerde set tegelijk in het geheugen wordt opgeslagen (800 x 0,6 MB =480 MB, waardoor er wat ruimte overblijft voor een uitvoerbuffer).
Er kunnen meerdere samenvoegingspassen worden gebruikt om dit te omzeilen. Het algemene idee is om geleidelijk kleine brokken samen te voegen tot grotere, totdat we de uiteindelijke gesorteerde uitvoerstroom efficiënt kunnen produceren. In het voorbeeld zou dit kunnen betekenen dat 40 van de 800 first-pass gesorteerde sets tegelijk worden samengevoegd, wat resulteert in 20 grotere brokken, die vervolgens opnieuw kunnen worden samengevoegd om de uitvoer te vormen. Met in totaal twee extra passages over de gegevens, zou dit een lekkage van niveau 2 zijn, enzovoort. Gelukkig maakt een lineaire toename van het morsniveau een exponentiële toename van de sorteergrootte mogelijk, dus diepe sorteringsniveaus zijn zelden nodig.
De lekkage "Level 15.000"
Op dit punt vraag je je misschien af welke combinatie van kleine geheugentoekenning en enorme gegevensomvang mogelijk zou kunnen resulteren in een sortering van niveau 15.000. Probeert u het hele internet in 1 MB geheugen te sorteren? Mogelijk, maar dat is veel te moeilijk om te demonstreren. Om eerlijk te zijn, heb ik geen idee of zo'n echt hoog lekniveau zelfs mogelijk is in SQL Server. Het doel hier (zeker een cheat) is om SQL Server te laten rapporteren een lekkage van niveau 15.000.
Het belangrijkste ingrediënt is partitionering. Sinds SQL Server 2012 mogen we een (handig) maximum van 15.000 partities per object (ondersteuning voor 15.000 partities is ook beschikbaar op 2008 SP2 en 2008 R2 SP1, maar je moet dit handmatig per database inschakelen, en op de hoogte zijn van alle de kanttekeningen).
Het eerste dat we nodig hebben, is een partitiefunctie van 15.000 elementen en een bijbehorend partitieschema. Om een werkelijk enorm inline codeblok te vermijden, gebruikt het volgende script dynamische SQL om de vereiste instructies te genereren:
DECLARE
@sql nvarchar(max) =
N'
CREATE PARTITION FUNCTION PF (integer)
AS RANGE LEFT
FOR VALUES
(1';
DECLARE @i integer = 2;
WHILE @i < 15000
BEGIN
SET @sql += N',' + CONVERT(nvarchar(5), @i);
SET @i += 1;
END;
SET @sql = @sql + N');';
EXECUTE (@sql);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]); Het script is eenvoudig genoeg om aan te passen naar een lager aantal voor het geval je setup worstelt met 15.000 partities (vooral vanuit geheugenoogpunt, zoals we binnenkort zullen zien). De volgende stappen zijn om een normale (niet gepartitioneerde) heaptabel te maken met een enkele integerkolom, en deze vervolgens te vullen met de gehele getallen van 1 tot en met 15.000:
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test1 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Dat zou in ongeveer 100 ms moeten zijn voltooid. Als je een getallentabel beschikbaar hebt, kun je die in plaats daarvan gebruiken voor een meer set-gebaseerde ervaring. De manier waarop de basistabel wordt gevuld, is niet belangrijk. Om onze 15.000 level spill te krijgen, hoeven we nu alleen maar een gepartitioneerde geclusterde index op de tafel te maken:
CREATE UNIQUE CLUSTERED INDEX CUQ ON dbo.Test1 (c1) WITH (MAXDOP = 1) ON PS (c1);
De uitvoeringstijd hangt sterk af van het gebruikte opslagsysteem. Op mijn laptop, met een vrij typische consumenten-SSD van een paar jaar geleden, duurt het ongeveer 20 seconden, wat behoorlijk belangrijk is als je bedenkt dat we in totaal maar 15.000 rijen hebben. Op een redelijk low-spec Azure VM met behoorlijk slechte I/O-prestaties, duurde dezelfde test bijna 20 minuten.
Analyse
Het uitvoeringsplan voor de indexopbouw is:
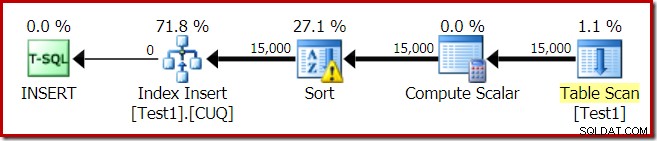
De Table Scan leest de 15.000 rijen uit onze heaptabel. De Compute Scalar berekent het bestemmingsindexpartitienummer voor elke rij met behulp van de interne functie RangePartitionNew() . De Sortering is het meest interessante deel van het plan, dus we zullen er meer in detail naar kijken.
Eerst de sorteerwaarschuwing, zoals weergegeven in Plan Explorer:

Een soortgelijke waarschuwing van SSMS (overgenomen uit een andere uitvoering van het script):
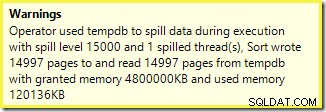
Het eerste dat opvalt, is het rapport van een lekkageniveau van 15.000 soorten, zoals beloofd. Dit is niet helemaal juist, maar de details zijn best interessant. De sortering in dit abonnement heeft een Partition ID eigenschap, die normaal niet aanwezig is:
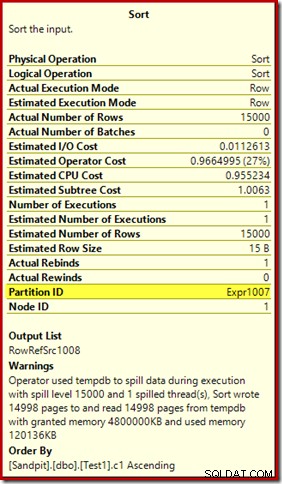
Deze eigenschap is gelijk aan de definitie van de interne partitiefunctie in de Compute Scalar.
Dit is een niet-uitgelijnde indexopbouw , omdat de bron en het doel verschillende indelingen hebben. In dit geval ontstaat dat verschil omdat de bronheaptabel niet is gepartitioneerd, maar de doelindex wel. Als gevolg hiervan worden tijdens runtime 15.000 afzonderlijke sorteringen gemaakt:één per niet-lege doelpartitie. Elk van deze soorten wordt gemorst tot niveau 1, en SQL Server somt al deze verspillingen op om het uiteindelijke verspillingsniveau van 15.000 te geven.
De 15.000 afzonderlijke soorten verklaren de grote hoeveelheid geheugen. Elke sorteerinstantie heeft een minimale grootte van 40 pagina's, dat is 40 x 8 KB =320 KB. De 15.000 soorten hebben dus minimaal 15.000 x 320 KB =4.800.000 KB geheugen nodig. Dat is gewoon verlegen van 4,6 GB RAM die exclusief is gereserveerd voor een zoekopdracht die 15.000 rijen sorteert met een enkele integerkolom. En elke soort komt op de schijf terecht, ondanks dat je maar één rij ontvangt! Als parallellisme zou worden gebruikt voor de opbouw van de index, zou de geheugentoelage verder kunnen worden opgeblazen door het aantal threads. Merk ook op dat de enkele rij in een pagina is geschreven, wat het aantal pagina's verklaart dat wordt geschreven naar en gelezen van tempdb. Er lijkt een raceconditie te zijn, wat betekent dat het gerapporteerde aantal pagina's vaak een paar minder dan 15.000 is.
Dit voorbeeld geeft natuurlijk een randgeval weer, maar het is nog steeds moeilijk te begrijpen waarom elke sortering zijn enkele rij morst in plaats van te sorteren in het geheugen dat hij heeft gekregen. Misschien is dit om de een of andere reden zo ontworpen, of misschien is het gewoon een bug. Hoe het ook zij, het is nog steeds best vermakelijk om te zien dat een paar honderd KB aan gegevens zo lang duurt met een geheugen van 4,6 GB en een niveau van 15.000. Tenzij je het in een productieomgeving tegenkomt misschien. Hoe dan ook, het is iets om rekening mee te houden.
Het misleidende lekkagerapport van 15.000 niveaus komt min of meer neer op weergavebeperkingen in de uitvoer van showplannen. Het fundamentele probleem is iets dat zich op veel plaatsen voordoet waar herhaalde acties plaatsvinden, bijvoorbeeld aan de binnenkant van de geneste lussen. Het zou zeker nuttig zijn om in deze gevallen een preciezere uitsplitsing te zien in plaats van een totaaltotaal. In de loop van de tijd is dit gebied een beetje verbeterd, dus we hebben nu meer planinformatie per thread of per partitie voor sommige bewerkingen. Er is echter nog een lange weg te gaan.
Het is nog steeds minder dan nuttig dat 15.000 afzonderlijke lekkages van niveau 1 hier worden gerapporteerd als een enkele lekkage op 15.000 niveau.
Testvariaties
Dit artikel gaat meer over het benadrukken van de beperkingen van planinformatie en het potentieel voor slechte prestaties wanneer extreme aantallen partities worden gebruikt, dan over het efficiënter maken van de specifieke voorbeeldbewerking, maar er zijn een aantal interessante variaties waar ik ook naar wil kijken .
Online, Sorteer in tempdb
Dezelfde bewerking voor het maken van gepartitioneerde indexen uitvoeren met ONLINE = ON, SORT_IN_TEMPDB = ON lijdt niet aan dezelfde enorme geheugentoelage en -verspilling:
CREATE TABLE dbo.Test2
(
c1 integer NOT NULL
);
-- Copy the sample data
INSERT dbo.Test2 WITH (TABLOCKX)
(c1)
SELECT
T1.c1
FROM dbo.Test1 AS T1
OPTION (MAXDOP 1);
-- Partitioned clustered index build
CREATE CLUSTERED INDEX CUQ
ON dbo.Test2 (c1)
WITH (MAXDOP = 1, ONLINE = ON, SORT_IN_TEMPDB = ON)
ON PS (c1);
Merk op dat het gebruik van ONLINE op zich is niet voldoende. In feite resulteert dat in hetzelfde plan als voorheen met dezelfde problemen, plus een extra overhead voor het online bouwen van elke indexpartitie. Voor mij resulteert dat in een uitvoeringstijd van ruim een minuut. God weet hoe lang het zou duren voor een Azure-instantie met een lage specificatie en vreselijke I/O-prestaties.
Hoe dan ook, het uitvoeringsplan met ONLINE = ON, SORT_IN_TEMPDB = ON is:

De sortering wordt uitgevoerd voordat het bestemmingspartitienummer wordt berekend. Het heeft niet de eigenschap Partitie-ID, dus het is gewoon een normale sortering. De hele operatie duurt ongeveer tien seconden (er moeten nog veel partities worden gemaakt). Het reserveert minder dan 3 MB geheugen en gebruikt maximaal 816 KB. Een hele verbetering ten opzichte van 4,6 GB en 15.000 lekkages.
Eerst indexeren, dan gegevens
Vergelijkbare resultaten kunnen worden verkregen door de gegevens eerst naar een heaptabel te schrijven:
-- Heap source
CREATE TABLE dbo.SourceData
(
c1 integer NOT NULL
);
-- Add data
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.SourceData (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Maak vervolgens een lege gepartitioneerde geclusterde tabel en voeg de gegevens van de heap in:
-- Destination table
CREATE TABLE dbo.Test3
(
c1 integer NOT NULL
)
ON PS (c1); -- Optional
-- Partitioned Clustered Index
CREATE CLUSTERED INDEX CUQ
ON dbo.Test3 (c1)
ON PS (c1);
-- Add data
INSERT dbo.Test3 WITH (TABLOCKX)
(c1)
SELECT
SD.c1
FROM dbo.SourceData AS SD
OPTION (MAXDOP 1);
-- Clean up
DROP TABLE dbo.SourceData; Dit duurt ongeveer tien seconden, met een geheugen van 2 MB en zonder morsen:
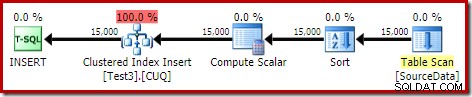
Natuurlijk kan het sorteren ook volledig worden vermeden door de (niet-gepartitioneerde) brontabel te indexeren en de gegevens in indexvolgorde in te voegen (de beste sortering is helemaal geen sortering, onthoud).
Gepartitioneerde heap, dan data, dan index
Voor deze laatste variatie maken we eerst een gepartitioneerde heap en laden de 15.000 testrijen:
CREATE TABLE dbo.Test4
(
c1 integer NOT NULL
)
ON PS (c1);
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test4 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Dat script loopt een seconde of twee, wat best goed is. De laatste stap is het maken van de gepartitioneerde geclusterde index:
CREATE CLUSTERED INDEX CUQ ON dbo.Test4 (c1) WITH (MAXDOP = 1) ON PS (c1);
Dat is een complete ramp, zowel vanuit het oogpunt van prestaties als vanuit het oogpunt van informatie over het showplan. De operatie zelf duurt iets minder dan een minuut, met het volgende uitvoeringsplan:

Dit is een colocated insert plan. De Constant Scan bevat een rij voor elke partitie-ID. De binnenkant van de lus zoekt naar de huidige verdeling van de hoop (ja, een zoektocht op een hoop). De sortering heeft een partitie-id-eigenschap (ondanks dat deze constant is per lus-iteratie), dus er is een sortering per partitie en het ongewenste morsgedrag. De statistiekenwaarschuwing op de heaptabel is vals.
De root van het invoegplan geeft aan dat een geheugentoewijzing van 1 MB was gereserveerd, met een maximum van 144 KB gebruikt:
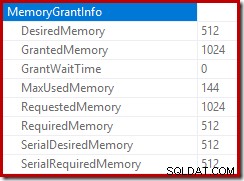
De sorteeroperator rapporteert geen lekkage van niveau 15.000, maar maakt verder een complete warboel van de iteratie-wiskunde per lus:

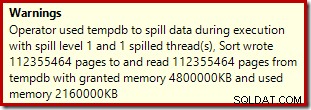
Het monitoren van de geheugentoekenningen DMV tijdens de uitvoering laat zien dat deze query in feite slechts 1 MB reserveert, met een maximum van 144 KB gebruikt voor elke iteratie van de lus. (De geheugenreservering van 4,6 GB in de eerste test daarentegen is absoluut echt.) Dit is natuurlijk verwarrend.
Het probleem (zoals eerder vermeld) is dat SQL Server in de war raakt over hoe het beste kan worden gerapporteerd over wat er gedurende vele iteraties is gebeurd. Het is waarschijnlijk niet praktisch om planprestatie-informatie per partitie per iteratie op te nemen, maar er is geen ontkomen aan het feit dat de huidige regeling soms verwarrende resultaten oplevert. We kunnen alleen maar hopen dat er ooit een betere manier zal worden gevonden om dit soort informatie in een consistenter formaat te rapporteren.