 Toen ik opgroeide, hield ik van games die het geheugen en patroonherkenning op de proef stelden. Verschillende van mijn vrienden hadden Simon, terwijl ik een knock-off had die Einstein heette. Anderen hadden een Atari Touch Me, waarvan ik zelfs toen al wist dat het een twijfelachtige naamgevingsbeslissing was. Tegenwoordig betekent patroonherkenning iets heel anders voor mij en kan het een duur onderdeel zijn van alledaagse databasequery's.
Toen ik opgroeide, hield ik van games die het geheugen en patroonherkenning op de proef stelden. Verschillende van mijn vrienden hadden Simon, terwijl ik een knock-off had die Einstein heette. Anderen hadden een Atari Touch Me, waarvan ik zelfs toen al wist dat het een twijfelachtige naamgevingsbeslissing was. Tegenwoordig betekent patroonherkenning iets heel anders voor mij en kan het een duur onderdeel zijn van alledaagse databasequery's.
Ik kwam onlangs een paar opmerkingen tegen over Stack Overflow waar een gebruiker beweerde, alsof het een feit was, dat CHARINDEX presteert beter dan LEFT of LIKE . In één geval citeerde de persoon een artikel van David Lozinski, "SQL:LIKE vs SUBSTRING vs LEFT/RIGHT vs CHARINDEX." Ja, het artikel laat zien dat, in het gekunstelde voorbeeld, CHARINDEX het beste gepresteerd. Omdat ik echter altijd sceptisch ben over dit soort algemene uitspraken, en geen logische reden kon bedenken waarom één tekenreeksfunctie altijd zou zijn beter presteren dan een ander, waarbij al het andere gelijk is , Ik deed zijn tests. En ja hoor, ik had herhaaldelijk verschillende resultaten op mijn machine (klik om te vergroten):
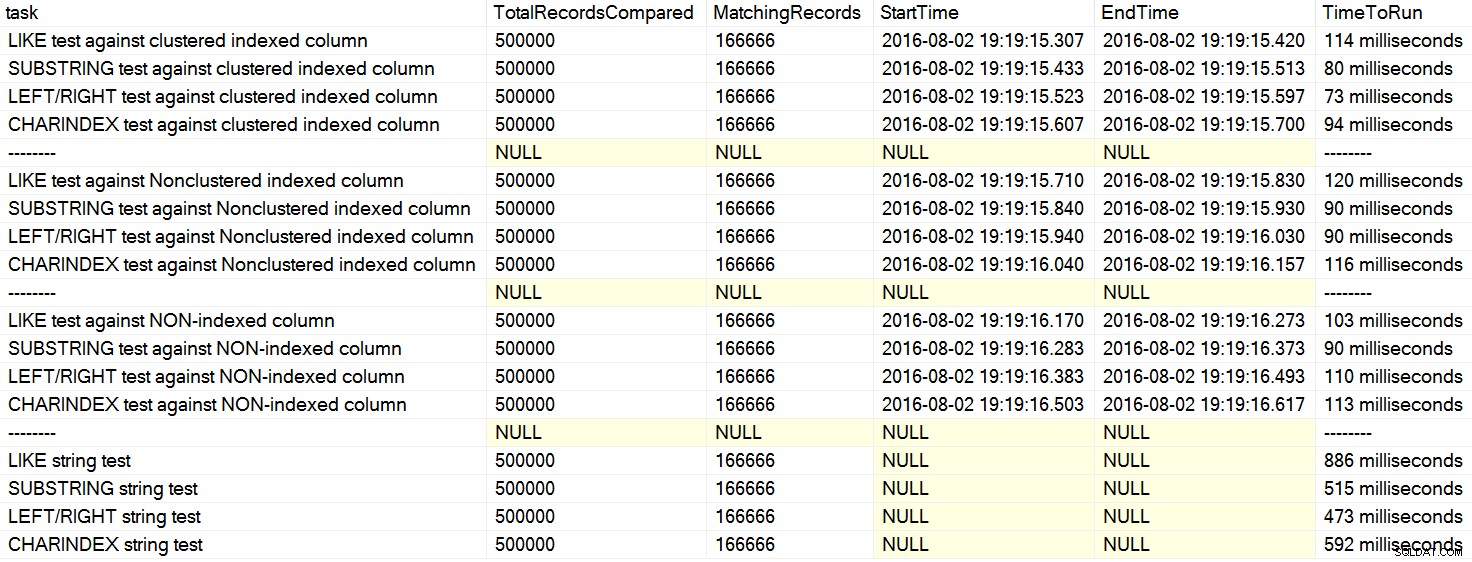 Op mijn computer was CHARINDEX langzamer dan LINKS/RECHTS/SUBSTRING.
Op mijn computer was CHARINDEX langzamer dan LINKS/RECHTS/SUBSTRING.
De tests van David waren in feite het vergelijken van deze zoekstructuren - op zoek naar een tekenreekspatroon aan het begin of einde van een kolomwaarde - in termen van onbewerkte duur:
WHERE Column LIKE @pattern + '%' OR Column LIKE '%' + @pattern; WHERE SUBSTRING(Column, 1, LEN(@pattern)) = @pattern OR SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)) = @pattern; WHERE LEFT(Column, LEN(@pattern)) = @pattern OR RIGHT(Column, LEN(@pattern)) = @pattern; WHERE CHARINDEX(@pattern, SUBSTRING(Column, 1, LEN(@pattern)), 0) > 0 OR CHARINDEX(@pattern, SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)), 0) > 0;
Als je alleen maar naar deze clausules kijkt, kun je zien waarom CHARINDEX is misschien minder efficiënt - het maakt meerdere aanvullende functionele oproepen die de andere benaderingen niet hoeven uit te voeren. Waarom deze aanpak het beste presteerde op de machine van David, weet ik niet zeker; misschien heeft hij de code precies uitgevoerd zoals gepost, en heeft hij niet echt buffers tussen tests laten vallen, zodat de laatste tests baat hadden bij gegevens in de cache.
In theorie, CHARINDEX had eenvoudiger kunnen worden uitgedrukt, bijvoorbeeld:
WHERE CHARINDEX(@pattern, Column) = 1 OR CHARINDEX(@pattern, Column) = LEN(Column) - LEN(@pattern) + 1;
(Maar dit presteerde zelfs nog slechter in mijn informele tests.)
En waarom deze zelfs OR . zijn voorwaarden, ik weet het niet zeker. Realistisch gezien voert u meestal een van de twee soorten patroonzoekopdrachten uit:begint met of bevat (het is veel minder gebruikelijk om te zoeken naar eindigt met ). En in de meeste van die gevallen heeft de gebruiker de neiging om vooraf aan te geven of ze willen dat begint met of bevat , althans bij elke sollicitatie waar ik in mijn carrière bij betrokken ben geweest.
Het is logisch om deze te scheiden als afzonderlijke typen zoekopdrachten, in plaats van een OF . te gebruiken voorwaardelijk, aangezien begint met kan gebruik maken van een index (als er een bestaat die geschikt genoeg is om te zoeken, of dunner is dan de geclusterde index), terwijl eindigt met kan niet (en OF omstandigheden hebben de neiging om sleutels naar de optimizer in het algemeen te gooien). Als ik LIKE kan vertrouwen om een index te gebruiken wanneer dat kan, en om in de meeste of alle gevallen zo goed of beter te presteren dan de andere oplossingen hierboven, dan kan ik deze logica heel gemakkelijk maken. Een opgeslagen procedure kan twee parameters hebben:het patroon waarnaar wordt gezocht en het type zoekopdracht dat moet worden uitgevoerd (in het algemeen zijn er vier soorten tekenreeksovereenkomsten:begint met, eindigt met, bevat of exacte overeenkomst).
CREATE PROCEDURE dbo.Search
@pattern nvarchar(100),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
-- latter two are supported but won't be tested here
AS
BEGIN
SET NOCOUNT ON;
SELECT ...
WHERE Column LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
Dit behandelt elk potentieel geval zonder dynamische SQL te gebruiken; de OPTION (RECOMPILE) is er omdat je niet wilt dat een plan dat is geoptimaliseerd voor "eindigt met" (dat vrijwel zeker moet worden gescand) opnieuw wordt gebruikt voor een "begint met"-query, of omgekeerd; het zorgt er ook voor dat schattingen correct zijn ("begint met S" heeft waarschijnlijk een heel andere kardinaliteit dan "begint met QX"). Zelfs als je een scenario hebt waarin gebruikers 99% van de tijd één type zoekopdracht kiezen, zou je hier dynamische SQL kunnen gebruiken in plaats van opnieuw te compileren, maar in dat geval zou je nog steeds kwetsbaar zijn voor het snuiven van parameters. In veel voorwaardelijke logische query's zijn hercompileren en/of volledige dynamische SQL vaak de meest verstandige benadering (zie mijn bericht over "the Kitchen Sink").
De testen
Omdat ik onlangs ben gaan kijken naar de nieuwe voorbeelddatabase van WideWorldImporters, besloot ik daar mijn eigen tests uit te voeren. Het was moeilijk om een tabel van behoorlijke omvang te vinden zonder een ColumnStore-index of een tijdelijke geschiedenistabel, maar Sales.Invoices , die 70.510 rijen heeft, heeft een eenvoudige nvarchar(20) kolom genaamd CustomerPurchaseOrderNumber die ik besloot te gebruiken voor de tests. (Waarom is het nvarchar(20) wanneer elke afzonderlijke waarde een getal van 5 cijfers is, heb ik geen idee, maar het maakt niet echt uit of de bytes eronder getallen of tekenreeksen vertegenwoordigen.)
| Sales.Invoices CustomerPurchaseOrderNumber | ||
|---|---|---|
| Patroon | # rijen | % van tabel |
| Begint met "1" | 70.505 | 99,993% |
| Begint met "2" | 5 | 0,007% |
| Eindigt met "5" | 6.897 | 9,782% |
| Eindigt met "30" | 749 | 1,062% |
Ik snuffelde rond in de waarden in de tabel om met meerdere zoekcriteria te komen die enorm verschillende aantallen rijen zouden opleveren, hopelijk om elk omslagpuntgedrag met een bepaalde benadering te onthullen. Rechts staan de zoekopdrachten waarop ik terechtkwam.
Ik wilde mezelf bewijzen dat de bovenstaande procedure onmiskenbaar beter was voor alle mogelijke zoekopdrachten dan alle zoekopdrachten die OR gebruiken conditionals, ongeacht of ze LIKE . gebruiken , LEFT/RIGHT , SUBSTRING , of CHARINDEX . Ik nam de basisquerystructuren van David en plaatste ze in opgeslagen procedures (met het voorbehoud dat ik "bevat" niet echt kan testen zonder zijn input, en dat ik zijn OR moest maken logica een beetje flexibeler om hetzelfde aantal rijen te krijgen), samen met een versie van mijn logica. Ik was ook van plan om de procedures te testen met en zonder een index die ik zou maken in de zoekkolom, en onder zowel een warme als een koude cache.
De procedures:
CREATE PROCEDURE dbo.David_LIKE
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CustomerPurchaseOrderNumber LIKE @pattern + N'%')
OR (@option = 'EndsWith'
AND CustomerPurchaseOrderNumber LIKE N'%' + @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0)
OR (@option = 'EndsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Aaron_Conditional
@pattern nvarchar(10),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
Ik heb ook versies van de procedures van David gemaakt die trouw zijn aan zijn oorspronkelijke bedoeling, ervan uitgaande dat de vereiste echt is om rijen te vinden waar het zoekpatroon aan het begin *of* het einde van de string staat. Ik deed dit eenvoudig zodat ik de prestaties van de verschillende benaderingen kon vergelijken, precies zoals hij ze schreef, om te zien of op deze dataset mijn resultaten overeenkwamen met mijn tests van zijn originele script op mijn systeem. In dit geval was er geen reden om een eigen versie te introduceren, omdat deze gewoon overeen zou komen met zijn LIKE % + @pattern OR LIKE @pattern + % variatie.
CREATE PROCEDURE dbo.David_LIKE_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE @pattern + N'%'
OR CustomerPurchaseOrderNumber LIKE N'%' + @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern
OR SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OR RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0
OR CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0
OPTION (RECOMPILE);
END
GO Met de bestaande procedures kon ik de testcode genereren - wat vaak net zo leuk is als het oorspronkelijke probleem. Eerst een logtabel:
DROP TABLE IF EXISTS dbo.LoggingTable; GO SET NOCOUNT ON; CREATE TABLE dbo.LoggingTable ( LogID int IDENTITY(1,1), prc sysname, opt varchar(10), pattern nvarchar(10), frame varchar(11), duration int, LogTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME() );
Dan de code die geselecteerde bewerkingen zou uitvoeren met behulp van de verschillende procedures en argumenten:
SET NOCOUNT ON;
;WITH prc(name) AS
(
SELECT name FROM sys.procedures
WHERE LEFT(name,5) IN (N'David', N'Aaron')
),
args(opt,pattern) AS
(
SELECT 'StartsWith', N'1'
UNION ALL SELECT 'StartsWith', N'2'
UNION ALL SELECT 'EndsWith', N'5'
UNION ALL SELECT 'EndsWith', N'30'
),
frame(w) AS
(
SELECT 'BeforeIndex'
UNION ALL SELECT 'AfterIndex'
),
y AS
(
-- comment out lines 2-4 here if we want warm cache
SELECT cmd = 'GO
DBCC FREEPROCCACHE() WITH NO_INFOMSGS;
DBCC DROPCLEANBUFFERS() WITH NO_INFOMSGS;
GO
DECLARE @d datetime2, @delta int;
SET @d = SYSUTCDATETIME();
EXEC dbo.' + prc.name + ' @pattern = N'''
+ args.pattern + '''' + CASE
WHEN prc.name LIKE N'%_Original' THEN ''
ELSE ',@option = ''' + args.opt + '''' END + ';
SET @delta = DATEDIFF(MICROSECOND, @d, SYSUTCDATETIME());
INSERT dbo.LoggingTable(prc,opt,pattern,frame,duration)
SELECT N''' + prc.name + ''',''' + args.opt + ''',N'''
+ args.pattern + ''',''' + frame.w + ''',@delta;
',
*, rn = ROW_NUMBER() OVER
(PARTITION BY frame.w ORDER BY frame.w DESC,
LEN(prc.name), args.opt DESC, args.pattern)
FROM prc CROSS JOIN args CROSS JOIN frame
)
SELECT cmd = cmd + CASE WHEN rn = 36 THEN
CASE WHEN w = 'BeforeIndex'
THEN 'CREATE INDEX testing ON '+
'Sales.Invoices(CustomerPurchaseOrderNumber);
' ELSE 'DROP INDEX Sales.Invoices.testing;' END
ELSE '' END--, name, opt, pattern, w, rn
FROM y
ORDER BY w DESC, rn; Resultaten
Ik heb deze tests uitgevoerd op een virtuele machine met Windows 10 (1511/10586.545), SQL Server 2016 (13.0.2149), met 4 CPU's en 32 GB RAM. Ik heb elke reeks tests 11 keer uitgevoerd; voor de warme cache-tests gooide ik de eerste reeks resultaten weg omdat sommige daarvan echt koude cache-tests waren.
Ik worstelde met hoe ik de resultaten in een grafiek moest zetten om patronen te laten zien, vooral omdat er gewoon geen patronen waren. Bijna elke methode was de beste in het ene scenario en het slechtste in het andere. In de volgende tabellen heb ik de best en slechtst presterende procedure voor elke kolom gemarkeerd, en je kunt zien dat de resultaten verre van overtuigend zijn:
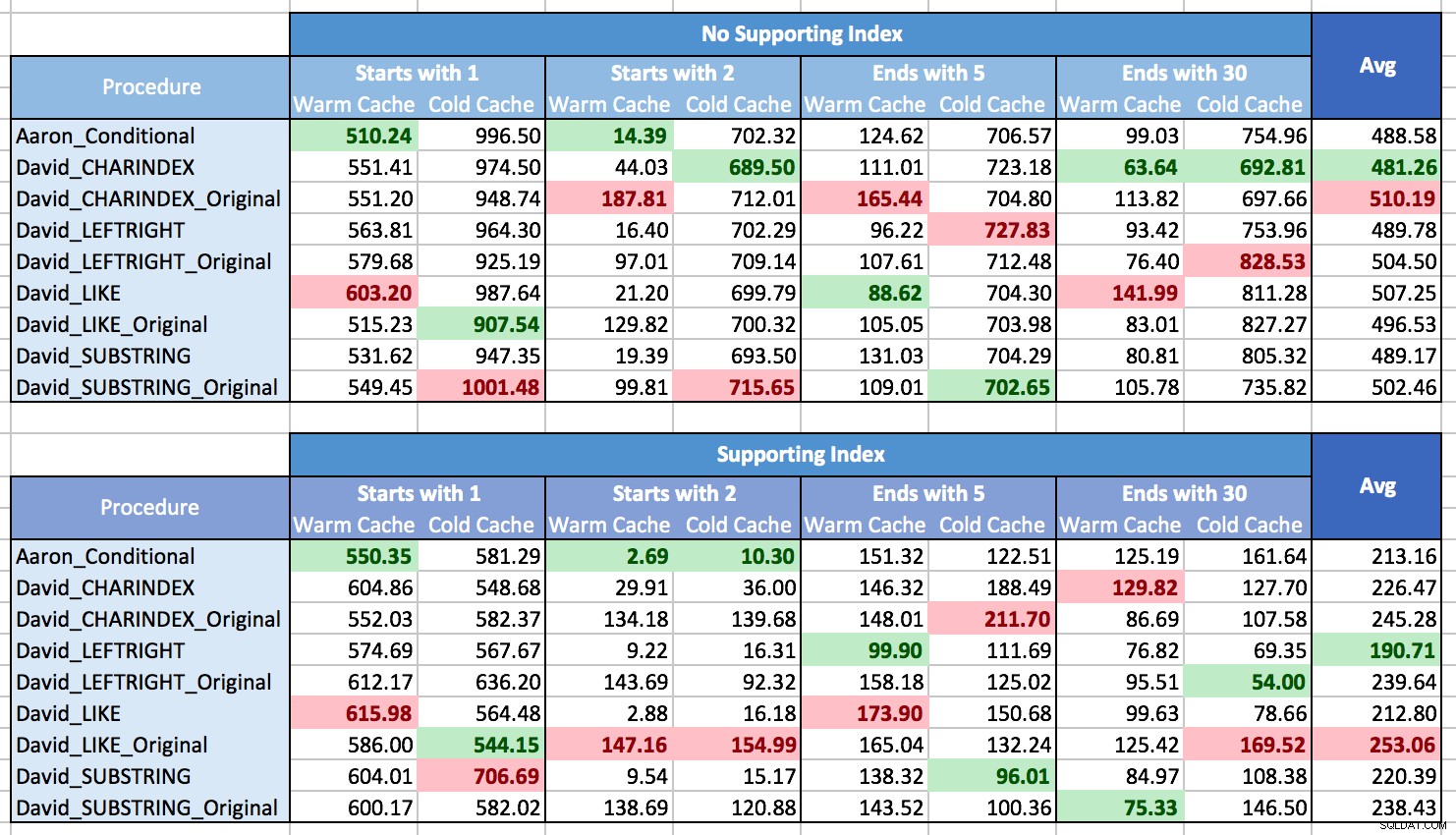 Bij deze tests won CHARINDEX soms en soms niet.
Bij deze tests won CHARINDEX soms en soms niet.
Wat ik heb geleerd, is dat als je met veel verschillende situaties te maken krijgt (verschillende soorten patroonovereenkomst, met een ondersteunende index of niet, gegevens niet altijd in het geheugen kunnen staan), er echt geen duidelijke winnaar, en het prestatiebereik is gemiddeld vrij klein (in feite, aangezien een warme cache niet altijd hielp, zou ik vermoeden dat de resultaten meer werden beïnvloed door de kosten van het weergeven van de resultaten dan door ze op te halen). Vertrouw voor individuele scenario's niet op mijn tests; voer zelf een aantal benchmarks uit, rekening houdend met uw hardware, configuratie, gegevens en gebruikspatronen.
Voorbehoud
Sommige dingen heb ik niet overwogen voor deze tests:
- Geclusterd versus niet-geclusterd . Aangezien het onwaarschijnlijk is dat uw geclusterde index zich in een kolom bevindt waar u zoekt naar patroonovereenkomsten tegen het begin of het einde van de tekenreeks, en aangezien een zoekopdracht in beide gevallen grotendeels hetzelfde zal zijn (en de verschillen tussen scans grotendeels functie zijn van indexbreedte versus tabelbreedte), heb ik de prestaties alleen getest met een niet-geclusterde index. Als je specifieke scenario's hebt waarin alleen dit verschil een groot verschil maakt bij het matchen van patronen, laat het me dan weten.
- MAX-typen . Als u zoekt naar strings binnen
varchar(max)/nvarchar(max), die kunnen niet worden geïndexeerd, dus tenzij u berekende kolommen gebruikt om delen van de waarde weer te geven, is een scan vereist - of u nu zoekt naar begint met, eindigt met of bevat. Of de prestatieoverhead correleert met de grootte van de string, of dat er extra overhead wordt geïntroduceerd, simpelweg vanwege het type, heb ik niet getest.
- Zoeken in volledige tekst . Ik heb hier en daar met deze functie gespeeld, en ik kan het spellen, maar als ik het goed begrijp, kan dit alleen nuttig zijn als je zoekt naar hele non-stop woorden, en je je geen zorgen maakt over waar in de tekenreeks ze waren gevonden. Het zou niet handig zijn als u alinea's met tekst opslaat en alle alinea's wilt vinden die beginnen met "Y", het woord "de" bevatten of eindigen met een vraagteken.
Samenvatting
De enige algemene verklaring die ik kan maken als ik deze test verlaat, is dat er geen algemene verklaringen zijn over wat de meest efficiënte manier is om stringpatroonovereenkomst uit te voeren. Hoewel ik bevooroordeeld ben in de richting van mijn voorwaardelijke benadering voor flexibiliteit en onderhoudbaarheid, was het niet in alle scenario's de winnaar van de prestaties. Voor mij, tenzij ik een prestatie-knelpunt raak en ik alle wegen nastreef, zal ik mijn aanpak blijven gebruiken voor consistentie. Zoals ik hierboven suggereerde, als je een heel smal scenario hebt en erg gevoelig bent voor kleine verschillen in duur, wil je je eigen tests uitvoeren om te bepalen welke methode consequent het beste presteert voor jou.