Vrijwel elk prestatieprobleem met betrekking tot berekende kolommen dat ik in de loop der jaren ben tegengekomen, had een (of meer) van de volgende hoofdoorzaken:
- Implementatiebeperkingen
- Gebrek aan ondersteuning voor kostenmodellen in de query-optimizer
- Uitbreiding van berekende kolomdefinitie voordat optimalisatie begint
Een voorbeeld van een implementatiebeperking is niet in staat om een gefilterde index op een berekende kolom te maken (zelfs als deze blijft bestaan). Aan deze probleemcategorie kunnen we niet veel doen; we moeten tijdelijke oplossingen gebruiken terwijl we wachten op productverbeteringen.
Het ontbreken van kostenmodelondersteuning optimize betekent dat SQL Server kleine vaste kosten toewijst aan scalaire berekeningen, ongeacht de complexiteit of implementatie. Als gevolg hiervan besluit de server vaak om een opgeslagen berekende kolomwaarde opnieuw te berekenen in plaats van de persistente of geïndexeerde waarde rechtstreeks te lezen. Dit is vooral pijnlijk wanneer de berekende expressie duur is, bijvoorbeeld wanneer het gaat om het aanroepen van een scalaire, door de gebruiker gedefinieerde functie.
De problemen rond definitie-uitbreiding zijn een beetje meer betrokken en hebben brede effecten.
De problemen van berekende kolomuitbreiding
SQL Server breidt normaal gesproken berekende kolommen uit naar hun onderliggende definities tijdens de bindingsfase van querynormalisatie. Dit is een zeer vroege fase in het querycompilatieproces, ruim voordat er beslissingen worden genomen over de keuze van een plan (inclusief een triviaal plan).
In theorie kan het uitvoeren van vroege uitbreiding optimalisaties mogelijk maken die anders zouden worden gemist. Het optimalisatieprogramma kan bijvoorbeeld vereenvoudigingen toepassen op basis van andere informatie in de zoekopdracht en metagegevens (bijv. beperkingen). Dit is dezelfde soort redenering die ertoe leidt dat weergavedefinities worden uitgebreid (tenzij een NOEXPAND hint wordt gebruikt).
Later in het compilatieproces (maar nog voordat zelfs maar een triviaal plan is overwogen), kijkt de optimizer om expressies terug te koppelen aan persistente of geïndexeerde berekende kolommen. Het probleem is dat optimalisatieactiviteiten in de tussentijd de uitgebreide expressies zo kunnen hebben gewijzigd dat terugkoppeling niet langer mogelijk is.
Wanneer dit gebeurt, ziet het uiteindelijke uitvoeringsplan eruit alsof de optimizer een "voor de hand liggende" kans heeft gemist om een persistente of geïndexeerde berekende kolom te gebruiken. Er zijn weinig details in uitvoeringsplannen die kunnen helpen bij het bepalen van de oorzaak, waardoor dit een potentieel frustrerend probleem is om te debuggen en op te lossen.
Uitdrukkingen afstemmen op berekende kolommen
Het is de moeite waard om vooral duidelijk te zijn dat er hier twee afzonderlijke processen zijn:
- Vroege uitbreiding van berekende kolommen; en
- Latere pogingen om uitdrukkingen te matchen met berekende kolommen.
Houd er in het bijzonder rekening mee dat elke query-expressie later kan worden gekoppeld aan een geschikte berekende kolom, niet alleen expressies die zijn ontstaan uit het uitbreiden van berekende kolommen.
Door het matchen van berekende kolomexpressies kunnen planverbeteringen mogelijk worden, zelfs als de tekst van de oorspronkelijke query niet kan worden gewijzigd. Als u bijvoorbeeld een berekende kolom maakt die overeenkomt met een bekende query-expressie, kan het optimalisatieprogramma statistieken en indexen gebruiken die aan de berekende kolom zijn gekoppeld. Deze functie is conceptueel vergelijkbaar met geïndexeerde weergave-overeenkomst in Enterprise Edition. Het matchen van berekende kolommen is functioneel in alle edities.
Vanuit praktisch oogpunt is mijn eigen ervaring dat het matchen van algemene query-expressies aan berekende kolommen inderdaad de prestaties, efficiëntie en stabiliteit van het uitvoeringsplan ten goede kan komen. Aan de andere kant heb ik zelden (of nooit) berekende kolomuitbreiding de moeite waard gevonden. Het lijkt gewoon nooit bruikbare optimalisaties op te leveren.
Berekend kolomgebruik
Berekende kolommen die geen van beide . zijn persistent noch geïndexeerd hebben geldige toepassingen. Ze kunnen bijvoorbeeld automatische statistieken ondersteunen als de kolom deterministisch en nauwkeurig is (geen drijvende-komma-elementen). Ze kunnen ook worden gebruikt om opslagruimte te besparen (ten koste van een beetje extra runtime-processorgebruik). Als laatste voorbeeld kunnen ze een nette manier bieden om ervoor te zorgen dat een eenvoudige berekening altijd correct wordt uitgevoerd, in plaats van elke keer expliciet in query's te worden geschreven.
Volhardde berekende kolommen werden specifiek aan het product toegevoegd om indexen te bouwen op deterministische maar "onnauwkeurige" (floating point) kolommen. In mijn ervaring is dit beoogde gebruik relatief zeldzaam. Misschien komt dit gewoon omdat ik niet zo vaak drijvende-kommagegevens tegenkom.
Drijvende-komma-indexen terzijde, persistente kolommen zijn vrij gebruikelijk. Tot op zekere hoogte kan dit zijn omdat onervaren gebruikers ervan uitgaan dat een berekende kolom altijd moet worden bewaard voordat deze kan worden geïndexeerd. Meer ervaren gebruikers kunnen persistente kolommen gebruiken, simpelweg omdat ze hebben ontdekt dat de prestaties op die manier meestal beter zijn.
Geïndexeerd berekende kolommen (aangehouden of niet) kunnen worden gebruikt om ordening en een efficiënte toegangsmethode te bieden. Het kan handig zijn om een berekende waarde in een index op te slaan zonder deze ook in de basistabel te bewaren. Evenzo kunnen geschikte berekende kolommen ook in indexen worden opgenomen in plaats van sleutelkolommen te zijn.
Slechte prestatie
Een belangrijke oorzaak van slechte prestaties is het eenvoudig niet gebruiken van een geïndexeerde of persistente berekende kolomwaarde zoals verwacht. Ik ben de tel kwijtgeraakt van het aantal vragen dat ik in de loop der jaren heb gehad met de vraag waarom de optimizer een verschrikkelijk uitvoeringsplan zou kiezen terwijl er een duidelijk beter plan bestaat met behulp van een geïndexeerde of persistente berekende kolom.
De precieze oorzaak varieert in elk geval, maar is bijna altijd ofwel een foutieve, op kosten gebaseerde beslissing (omdat aan scalairen lage vaste kosten worden toegewezen); of het niet koppelen van een uitgebreide expressie aan een persistente berekende kolom of index.
De matchback-mislukkingen zijn vooral interessant voor mij, omdat ze vaak gepaard gaan met complexe interacties met orthogonale engine-functies. Even vaak laat het niet "terug matchen" een uitdrukking (in plaats van een kolom) achter op een positie in de interne zoekstructuur die verhindert dat een belangrijke optimalisatieregel overeenkomt. In beide gevallen is het resultaat hetzelfde:een suboptimaal uitvoeringsplan.
Nu denk ik dat het redelijk is om te zeggen dat mensen over het algemeen een berekende kolom indexeren of volhouden met de sterke verwachting dat de opgeslagen waarde daadwerkelijk zal worden gebruikt. Het kan een behoorlijke schok zijn om te zien dat SQL Server de onderliggende expressie elke keer opnieuw berekent, terwijl de opzettelijk opgegeven opgeslagen waarde wordt genegeerd. Mensen zijn niet altijd erg geïnteresseerd in de interne interacties en de tekortkomingen van het kostenmodel die tot de ongewenste uitkomst hebben geleid. Zelfs als er tijdelijke oplossingen bestaan, vereisen deze tijd, vaardigheid en moeite om te ontdekken en te testen.
Kortom:veel mensen zouden er gewoon de voorkeur aan geven dat SQL Server de persistente of geïndexeerde waarde gebruikt. Altijd.
Een nieuwe optie
Historisch gezien was er geen manier om SQL Server te dwingen om altijd de opgeslagen waarde te gebruiken (geen equivalent van de NOEXPAND hint voor weergaven). Er zijn enkele omstandigheden waarin een plangids zal werken, maar het is niet altijd mogelijk om de vereiste planvorm in de eerste plaats te genereren, en niet alle planelementen en posities kunnen worden geforceerd (bijvoorbeeld filters en compute scalaires).
Er is nog steeds geen nette, volledig gedocumenteerde oplossing, maar een recente update van SQL Server 2016 heeft gezorgd voor een interessante nieuwe aanpak. Het is van toepassing op SQL Server 2016-instanties die zijn gepatcht met ten minste Cumulatieve Update 2 voor SQL Server 2016 SP1 of Cumulatieve Update 4 voor SQL Server 2016 RTM.
De relevante update is gedocumenteerd in:FIX:Kan de partitie niet online opnieuw opbouwen voor een tabel die een berekende partitioneringskolom bevat in SQL Server 2016
Zoals zo vaak met ondersteunende documentatie, staat hier niet precies wat er in de engine is gewijzigd om het probleem op te lossen. Het ziet er zeker niet erg relevant uit voor onze huidige zorgen, te oordelen naar de titel en beschrijving. Desalniettemin introduceert deze correctie een nieuwe ondersteunde traceringsvlag 176 , die wordt gecontroleerd in een codemethode genaamd FDontExpandPersistedCC . Zoals de naam van de methode suggereert, voorkomt dit dat een persistente berekende kolom wordt uitgebreid.
Hierbij zijn drie belangrijke kanttekeningen te plaatsen:
- De berekende kolom moet persistent zijn . Zelfs als deze is geïndexeerd, moet de kolom ook worden bewaard.
- Terugkoppeling van algemene query-expressies naar persistente berekende kolommen is uitgeschakeld .
- De documentatie beschrijft de functie van de traceringsvlag niet en schrijft deze ook niet voor voor enig ander gebruik. Als u ervoor kiest om traceringsvlag 176 te gebruiken om uitbreiding van persistente berekende kolommen te voorkomen, is dit daarom op eigen risico.
Deze traceervlag is effectief als een start-up –T optie, zowel globaal als sessiebereik met behulp van DBCC TRACEON , en per zoekopdracht met OPTION (QUERYTRACEON) .
Voorbeeld
Dit is een vereenvoudigde versie van een vraag (gebaseerd op een reëel probleem) die ik een paar jaar geleden op Database Administrators Stack Exchange heb beantwoord. De tabeldefinitie bevat een persistente berekende kolom:
CREATE TABLE dbo.T
(
ID integer IDENTITY NOT NULL,
A varchar(20) NOT NULL,
B varchar(20) NOT NULL,
C varchar(20) NOT NULL,
D date NULL,
Computed AS A + '-' + B + '-' + C PERSISTED,
CONSTRAINT PK_T_ID
PRIMARY KEY CLUSTERED (ID),
);
GO
INSERT dbo.T WITH (TABLOCKX)
(A, B, C, D)
SELECT
A = STR(SV.number % 10, 2),
B = STR(SV.number % 20, 2),
C = STR(SV.number % 30, 2),
D = DATEADD(DAY, 0 - SV.number, SYSUTCDATETIME())
FROM master.dbo.spt_values AS SV
WHERE SV.[type] = N'P'; De onderstaande query retourneert alle rijen uit de tabel in een bepaalde volgorde, terwijl ook de volgende waarde van kolom D in dezelfde volgorde wordt geretourneerd:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
(
SELECT TOP (1)
t2.D
FROM dbo.T AS T2
WHERE
T2.Computed = T1.Computed
AND T2.D > T1.D
ORDER BY
T2.D ASC
)
FROM dbo.T AS T1
ORDER BY
T1.Computed, T1.D; Een voor de hand liggende dekkende index ter ondersteuning van de uiteindelijke volgorde en opzoekingen in de subquery is:
CREATE UNIQUE NONCLUSTERED INDEX IX_T_Computed_D_ID ON dbo.T (Computed, D, ID);
Het door de optimizer geleverde uitvoeringsplan is verrassend en teleurstellend:
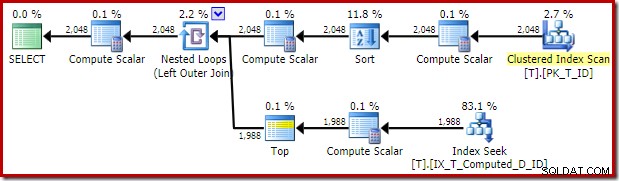
De Index Seek aan de binnenkant van de Nested Loops Join lijkt allemaal goed te zijn. De Clustered Index Scan and Sort op de buitenste invoer is echter onverwacht. We hadden gehoopt in plaats daarvan een geordende scan van onze dekkende niet-geclusterde index te zien.
We kunnen de optimizer dwingen om de niet-geclusterde index te gebruiken met een tabelhint:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
(
SELECT TOP (1)
t2.D
FROM dbo.T AS T2
WHERE
T2.Computed = T1.Computed
AND T2.D > T1.D
ORDER BY
T2.D ASC
)
FROM dbo.T AS T1
WITH (INDEX(IX_T_Computed_D_ID)) -- New!
ORDER BY
T1.Computed, T1.D; Het resulterende uitvoeringsplan is:
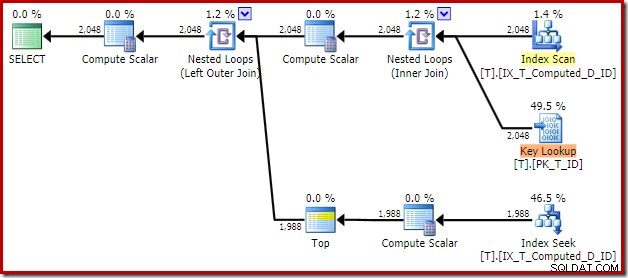
Het scannen van de niet-geclusterde index verwijdert de Sort, maar voegt een Key Lookup! De zoekopdrachten in dit nieuwe plan zijn verrassend, aangezien onze index zeker alle kolommen dekt die nodig zijn voor de zoekopdracht.
Kijken naar de eigenschappen van de Key Lookup-operator:
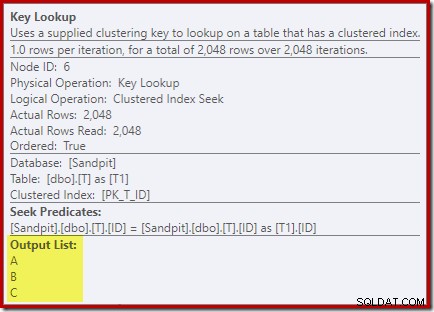
Om de een of andere reden heeft de optimizer besloten dat drie kolommen die niet in de query worden genoemd, moeten worden opgehaald uit de basistabel (aangezien ze niet aanwezig zijn in onze niet-geclusterde index door ontwerp).
Als we rondkijken in het uitvoeringsplan, ontdekken we dat de opgezochte kolommen nodig zijn voor de binnenkant Index Zoek:

Het eerste deel van dit zoekpredikaat komt overeen met de correlatie T2.Computed = T1.Computed in de oorspronkelijke vraag. De optimizer heeft de definities van beide berekende kolommen uitgebreid, maar is er alleen in geslaagd om terug te matchen met de persistente en geïndexeerde berekende kolom voor de binnenste alias T1 . Het verlaten van de T2 referentie uitgevouwen heeft ertoe geleid dat de buitenkant van de join de kolommen van de basistabel moet leveren (A , B , en C ) nodig om die uitdrukking voor elke rij te berekenen.
Zoals soms het geval is, is het mogelijk om deze query te herschrijven zodat het probleem verdwijnt (een optie wordt getoond in mijn oude antwoord op de Stack Exchange-vraag). Met SQL Server 2016 kunnen we ook traceringsvlag 176 proberen om te voorkomen dat de berekende kolommen worden uitgebreid:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
(
SELECT TOP (1)
t2.D
FROM dbo.T AS T2
WHERE
T2.Computed = T1.Computed
AND T2.D > T1.D
ORDER BY
T2.D ASC
)
FROM dbo.T AS T1
ORDER BY
T1.Computed, T1.D
OPTION (QUERYTRACEON 176); -- New! Het uitvoeringsplan is nu veel verbeterd:
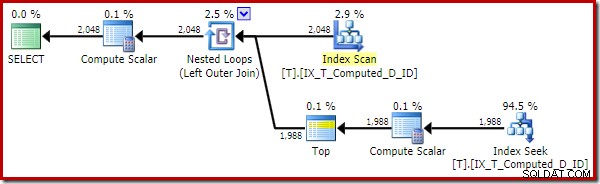
Dit uitvoeringsplan bevat alleen verwijzingen naar de berekende kolommen. De Compute Scalars doen niets nuttigs en zouden worden opgeruimd als de optimizer wat netter was in huis.
Het belangrijkste punt is dat de optimale index nu correct wordt gebruikt en dat de sorteer- en sleutelzoekopdracht zijn geëlimineerd. Dit alles door te voorkomen dat SQL Server iets doet waarvan we in de eerste plaats nooit hadden verwacht dat het zou doen (uitbreiding van een persistente en geïndexeerde berekende kolom).
LEAD gebruiken
De oorspronkelijke Stack Exchange-vraag was gericht op SQL Server 2008, waar LEAD is niet beschikbaar. Laten we proberen de vereiste op SQL Server 2016 uit te drukken met behulp van de nieuwere syntaxis:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
LEAD(T1.D) OVER (
PARTITION BY T1.Computed
ORDER BY T1.D)
FROM dbo.T AS T1
ORDER BY
T1.Computed; Het uitvoeringsplan voor SQL Server 2016 is:
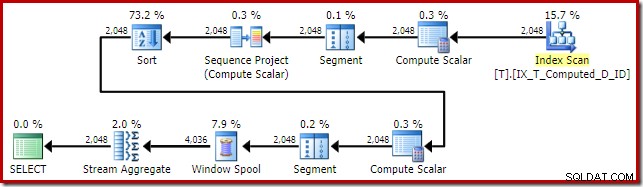
Deze plattegrondvorm is vrij typerend voor een eenvoudige vensterfunctie in de rijmodus. Het enige onverwachte item is de sorteeroperator in het midden. Als de dataset groot zou zijn, zou deze sortering een grote impact kunnen hebben op de prestaties en het geheugengebruik.
Het probleem is opnieuw berekende kolomuitbreiding. In dit geval bevindt een van de uitgevouwen uitdrukkingen zich op een positie die de normale optimalisatielogica verhindert die het sorteren vereenvoudigt.
Precies dezelfde query proberen met traceringsvlag 176:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
LEAD(T1.D) OVER (
PARTITION BY T1.Computed
ORDER BY T1.D)
FROM dbo.T AS T1
ORDER BY
T1.Computed
OPTION (QUERYTRACEON 176); Produceert het plan:
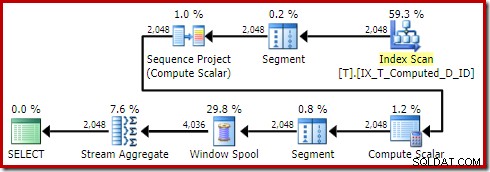
De Sort is verdwenen zoals het hoort. Merk terloops ook op dat deze zoekopdracht in aanmerking kwam voor een triviaal plan, waardoor optimalisatie op basis van kosten helemaal werd vermeden.
Overeenkomen van algemene uitdrukkingen uitgeschakeld
Een van de eerder genoemde waarschuwingen was dat traceringsvlag 176 ook het matchen van expressies in de bronquery met persistente berekende kolommen uitschakelt.
Bekijk ter illustratie de volgende versie van de voorbeeldquery. De LEAD berekening is verwijderd en de verwijzingen naar de berekende kolom in de SELECT en ORDER BY clausules zijn vervangen door de onderliggende uitdrukkingen. Voer het eerst uit zonder traceervlag 176:
SELECT
T1.ID,
Computed = T1.A + '-' + T1.B + '-' + T1.C,
T1.D
FROM dbo.T AS T1
ORDER BY
T1.A + '-' + T1.B + '-' + T1.C; De expressies komen overeen met de persistente berekende kolom en het uitvoeringsplan is een eenvoudige geordende scan van de niet-geclusterde index:
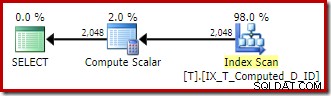
De Compute Scalar daar is weer alleen maar overgebleven architecturale rommel.
Probeer nu dezelfde query met traceringsvlag 176 ingeschakeld:
SELECT
T1.ID,
Computed = T1.A + '-' + T1.B + '-' + T1.C,
T1.D
FROM dbo.T AS T1
ORDER BY
T1.A + '-' + T1.B + '-' + T1.C
OPTION (QUERYTRACEON 176); -- New! Het nieuwe uitvoeringsplan is:
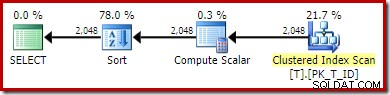
De niet-geclusterde indexscan is vervangen door een geclusterde indexscan. De Compute Scalar evalueert de uitdrukking en de Sorteervolgorde op het resultaat. De optimizer kan geen gebruik maken van de persistente waarde of de niet-geclusterde index.
Houd er rekening mee dat de beperking voor het overeenkomen van uitdrukkingen alleen van toepassing is op aanhoudende berekende kolommen wanneer traceringsvlag 176 actief is. Als we de berekende kolom geïndexeerd maar niet persistent maken, werkt het matchen van expressies correct.
Om het persistente kenmerk te verwijderen, moeten we eerst de niet-geclusterde index verwijderen. Zodra de wijziging is aangebracht, kunnen we de index meteen terugzetten (omdat de uitdrukking deterministisch en nauwkeurig is):
DROP INDEX IX_T_Computed_D_ID ON dbo.T; GO ALTER TABLE dbo.T ALTER COLUMN Computed DROP PERSISTED; GO CREATE UNIQUE NONCLUSTERED INDEX IX_T_Computed_D_ID ON dbo.T (Computed, D, ID);
De optimizer heeft nu geen problemen om de query-expressie te matchen met de berekende kolom wanneer traceringsvlag 176 actief is:
-- Computed column no longer persisted
-- but still indexed. TF 176 active.
SELECT
T1.ID,
Computed = T1.A + '-' + T1.B + '-' + T1.C,
T1.D
FROM dbo.T AS T1
ORDER BY
T1.A + '-' + T1.B + '-' + T1.C
OPTION (QUERYTRACEON 176); Het uitvoeringsplan keert terug naar de optimale niet-geclusterde indexscan zonder sortering:
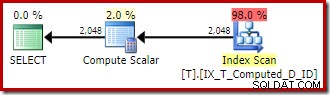
Samenvattend:Traceringsvlag 176 voorkomt aanhoudende berekende kolomuitbreiding. Als een neveneffect voorkomt het ook dat zoekopdrachtexpressies alleen overeenkomen met persistente berekende kolommen.
Schema-metadata wordt slechts één keer geladen, tijdens de bindingsfase. Traceringsvlag 176 voorkomt uitbreiding, dus de berekende kolomdefinitie wordt op dat moment niet geladen. Latere expressie-naar-kolom-matching kan niet werken zonder de berekende kolomdefinitie om tegen te matchen.
Het aanvankelijke laden van metagegevens levert alle kolommen op, niet alleen de kolommen waarnaar in de query wordt verwezen (de optimalisatie wordt later uitgevoerd). Dit maakt alle berekende kolommen beschikbaar voor matching, wat over het algemeen een goede zaak is. Helaas, als een van de geladen berekende kolommen een scalaire door de gebruiker gedefinieerde functie bevat, schakelt zijn aanwezigheid parallellisme voor de hele query uit, zelfs als de problematische kolom niet wordt gebruikt. Traceringsvlag 176 kan hier ook bij helpen, als de betreffende kolom behouden blijft. Door de definitie niet te laden, is er nooit een scalaire, door de gebruiker gedefinieerde functie aanwezig, dus parallellisme wordt niet uitgeschakeld.
Laatste gedachten
Het lijkt mij dat de SQL Server-wereld een betere plek zou zijn als de optimizer persistente of geïndexeerde berekende kolommen meer als gewone kolommen zou behandelen. In bijna alle gevallen zou dit beter overeenkomen met de verwachtingen van de ontwikkelaar dan de huidige regeling. Het uitbreiden van berekende kolommen naar hun onderliggende uitdrukkingen en later proberen om ze terug te vinden, is in de praktijk niet zo succesvol als de theorie zou suggereren.
Totdat SQL Server specifieke ondersteuning biedt om aanhoudende of geïndexeerde berekende kolomuitbreiding te voorkomen, is de nieuwe traceringsvlag 176 een verleidelijke optie voor gebruikers van SQL Server 2016, zij het een onvolmaakte. Het is een beetje jammer dat het algemene expressie-matching als bijwerking uitschakelt. Het is ook jammer dat de berekende kolom moet worden volgehouden wanneer deze wordt geïndexeerd. Er bestaat dan het risico dat een traceervlag wordt gebruikt voor een ander doel dan het gedocumenteerde doel ervan.
Het is redelijk om te zeggen dat de meeste problemen met berekende kolomquery's uiteindelijk op andere manieren kunnen worden opgelost, mits voldoende tijd, moeite en expertise. Aan de andere kant lijkt traceringsvlag 176 vaak als magie te werken. De keuze, zoals ze zeggen, is aan jou.
Om af te sluiten, zijn hier enkele interessante berekende kolomproblemen die baat hebben bij traceringsvlag 176:
- Berekende kolomindex niet gebruikt
- PERSISTED berekende kolom niet gebruikt in partitionering van vensterfunctie
- Aanhoudende berekende kolom die scan veroorzaakte
- Berekende kolomindex niet gebruikt met MAX-gegevenstypen
- Ernstig prestatieprobleem met aanhoudende berekende kolommen en joins
- Waarom "Compute Scalar" in SQL Server wanneer ik een persistente berekende kolom SELECTEER?
- Basiskolommen gebruikt in plaats van persistente berekende kolom door engine
- Berekende kolom met UDF schakelt parallellisme uit voor zoekopdrachten op *andere* kolommen