Het verwijderen en voorkomen van indexfragmentatie is al lang een onderdeel van normale database-onderhoudsactiviteiten, niet alleen in SQL Server, maar op veel platforms. Indexfragmentatie is om veel redenen van invloed op de prestaties, en de meeste mensen spreken over de effecten van willekeurige kleine I/O-blokken die fysiek op schijfgebaseerde opslag kunnen optreden als iets dat moet worden vermeden. De algemene zorg rond indexfragmentatie is dat het de prestaties van scans beïnvloedt door de grootte van read-ahead I/O's te beperken. Het is gebaseerd op dit beperkte begrip van de problemen die indexfragmentatie veroorzaakt, dat sommige mensen het idee zijn gaan verspreiden dat indexfragmentatie er niet toe doet met Solid State Storage-apparaten (SSD's) en dat je indexfragmentatie in de toekomst gewoon kunt negeren.
Om een aantal redenen is dat echter niet het geval. In dit artikel wordt een van die redenen uitgelegd en gedemonstreerd:dat indexfragmentatie een negatieve invloed kan hebben op de keuze van het uitvoeringsplan voor query's. Dit gebeurt omdat indexfragmentatie over het algemeen leidt tot een index met meer pagina's (deze extra pagina's zijn afkomstig van paginasplitsing bewerkingen, zoals beschreven in dit bericht op deze site), en dus wordt het gebruik van die index geacht hogere kosten te hebben door de query-optimizer van SQL Server.
Laten we een voorbeeld bekijken.
Het eerste dat we moeten doen, is een geschikte testdatabase en gegevensset bouwen om te onderzoeken hoe indexfragmentatie van invloed kan zijn op de keuze van het queryplan in SQL Server. Het volgende script maakt een database aan met twee tabellen met identieke gegevens, één sterk gefragmenteerd en één minimaal gefragmenteerd.
USE master;
GO
DROP DATABASE FragmentationTest;
GO
CREATE DATABASE FragmentationTest;
GO
USE FragmentationTest;
GO
CREATE TABLE GuidHighFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidHighFragmentation_LastName
ON GuidHighFragmentation(LastName);
GO
CREATE TABLE GuidLowFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidLowFragmentation_LastName
ON GuidLowFragmentation(LastName);
GO
INSERT INTO GuidHighFragmentation (FirstName, LastName)
SELECT TOP 100000 a.name, b.name
FROM master.dbo.spt_values AS a
CROSS JOIN master.dbo.spt_values AS b
WHERE a.name IS NOT NULL
AND b.name IS NOT NULL
ORDER BY NEWID();
GO 70
INSERT INTO GuidLowFragmentation (UniqueID, FirstName, LastName)
SELECT UniqueID, FirstName, LastName
FROM GuidHighFragmentation;
GO
ALTER INDEX ALL ON GuidLowFragmentation REBUILD;
GO Na het opnieuw opbouwen van de index kunnen we de fragmentatieniveaus bekijken met de volgende vraag:
SELECT
OBJECT_NAME(ps.object_id) AS table_name,
i.name AS index_name,
ps.index_id,
ps.index_depth,
avg_fragmentation_in_percent,
fragment_count,
page_count,
avg_page_space_used_in_percent,
record_count
FROM sys.dm_db_index_physical_stats(
DB_ID(),
NULL,
NULL,
NULL,
'DETAILED') AS ps
JOIN sys.indexes AS i
ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE index_level = 0;
GO Resultaten:

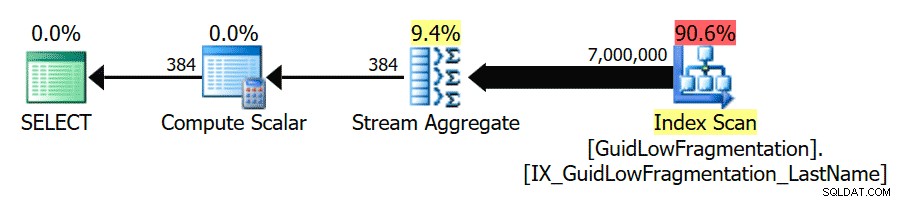
Hier kunnen we zien dat onze GuidHighFragmentation tabel is 99% gefragmenteerd en gebruikt 31% meer paginaruimte dan de GuidLowFragmentation tabel in de database, ondanks dat ze dezelfde 7.000.000 rijen met gegevens hebben. Als we een elementaire aggregatiequery uitvoeren op elk van de tabellen en de uitvoeringsplannen vergelijken op een standaardinstallatie (met standaardconfiguratieopties en -waarden) van SQL Server met behulp van SentryOne Plan Explorer:
-- Aggregate the data from both tables SELECT LastName, COUNT(*) FROM GuidLowFragmentation GROUP BY LastName; GO SELECT LastName, COUNT(*) FROM GuidHighFragmentation GROUP BY LastName; GO


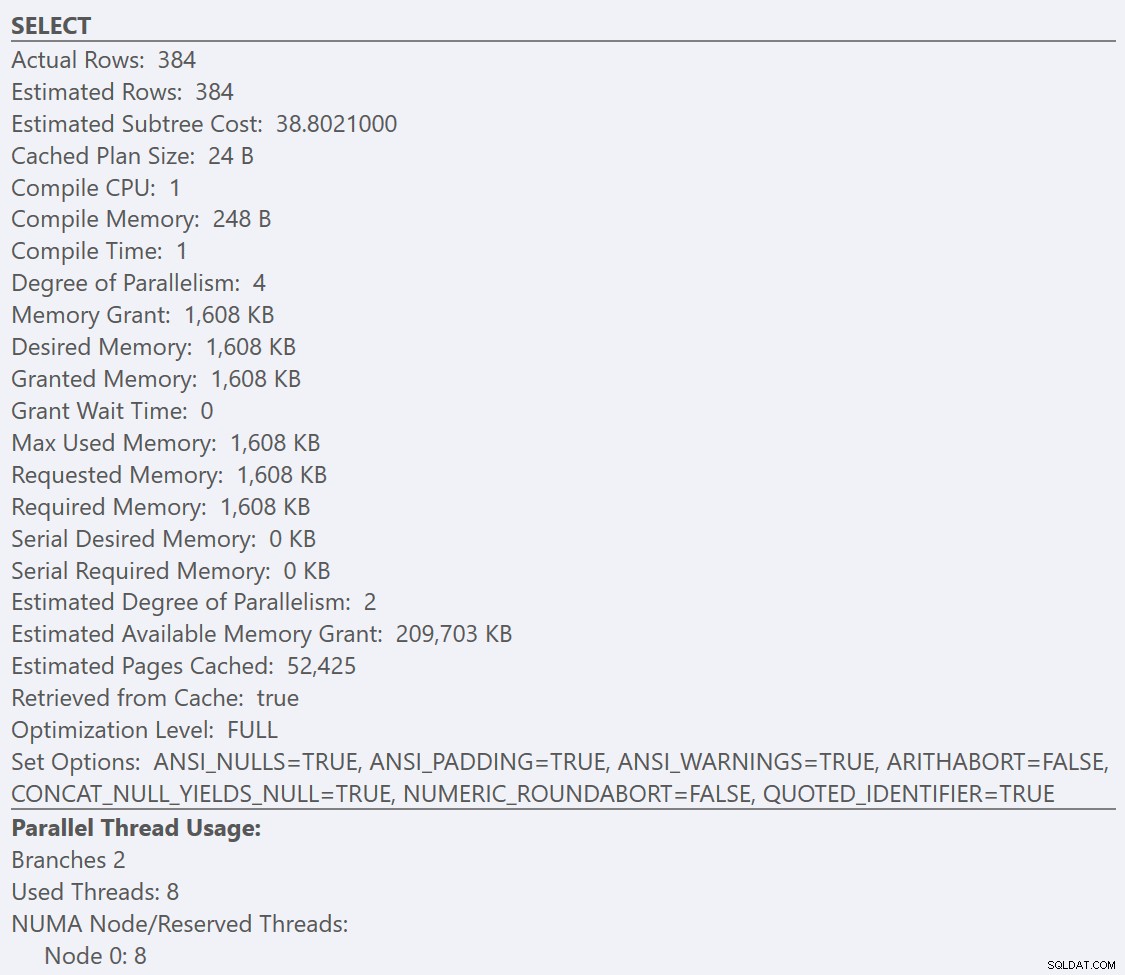

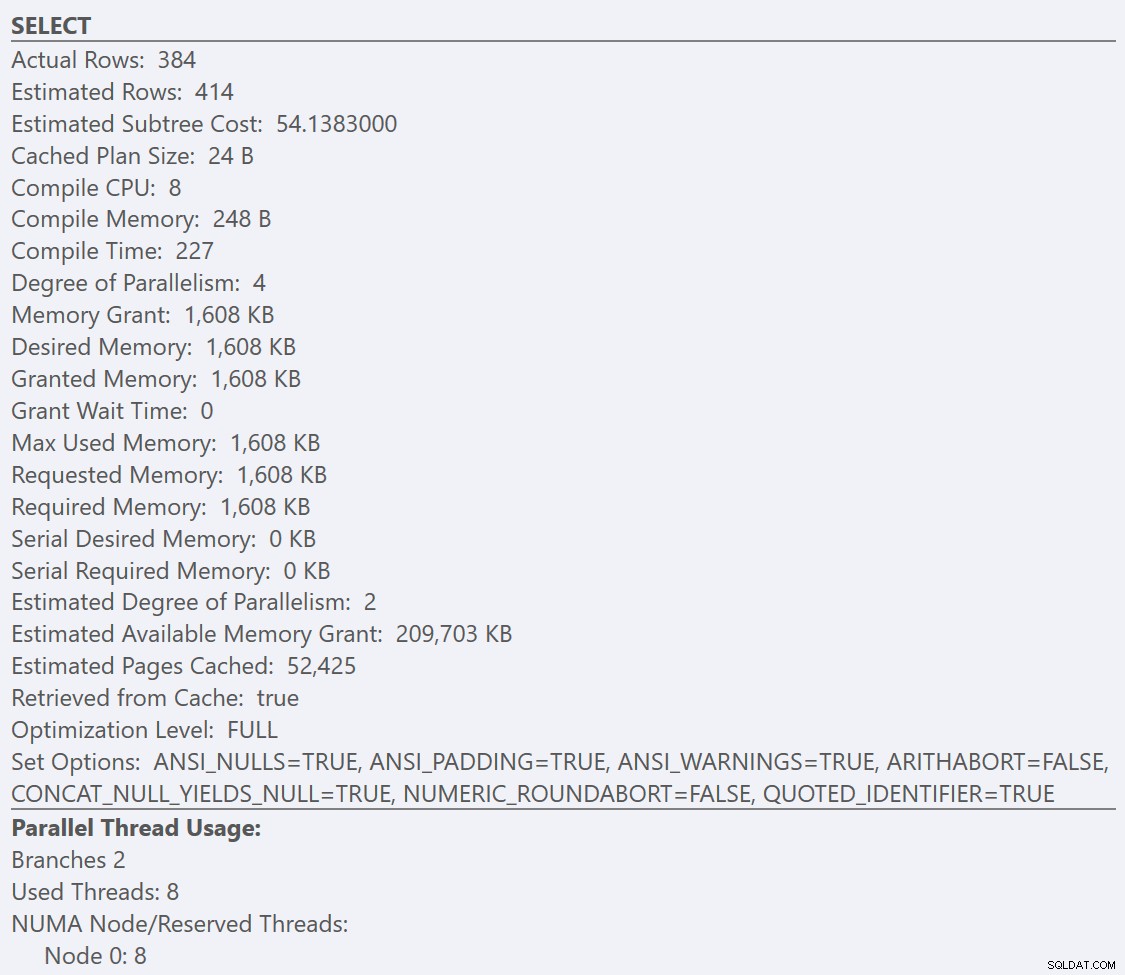
Als we kijken naar de tooltips van de SELECT operator voor elk plan, het plan voor de GuidLowFragmentation tabel heeft een querykost van 38,80 (de derde regel naar beneden vanaf de bovenkant van de knopinfo) versus een querykost van 54,14 voor het plan voor het GuidHighFragmentation-plan.
Bij een standaardconfiguratie voor SQL Server genereren beide query's uiteindelijk een parallel uitvoeringsplan, aangezien de geschatte kosten van de query hoger zijn dan de 'kostendrempel voor parallellisme' sp_configure optie standaard van 5. Dit komt omdat de query-optimizer eerst een seriële plan (dat alleen kan worden uitgevoerd door een enkele thread) bij het compileren van het plan voor een query. Als de geschatte kosten van dat seriële plan de geconfigureerde 'kostendrempel voor parallellisme' overschrijden, wordt in plaats daarvan een parallel plan gegenereerd en in de cache opgeslagen.
Maar wat als de sp_configure-optie 'kostendrempel voor parallellisme' niet is ingesteld op de standaardwaarde van 5 en hoger is ingesteld? Het is een goede gewoonte (en een juiste) om deze optie te verhogen van de lage standaardwaarde van 5 naar ergens tussen de 25 en 50 (of zelfs veel hoger) om te voorkomen dat kleine zoekopdrachten de extra overhead veroorzaken van parallel gaan.
EXEC sys.sp_configure N'show advanced options', N'1'; RECONFIGURE; GO EXEC sys.sp_configure N'cost threshold for parallelism', N'50'; RECONFIGURE; GO EXEC sys.sp_configure N'show advanced options', N'0'; RECONFIGURE; GO
Na het volgen van de richtlijnen voor best practices en het verhogen van de 'kostendrempel voor parallellisme' tot 50, resulteert het opnieuw uitvoeren van de query's in hetzelfde uitvoeringsplan voor de GuidHighFragmentation tabel, maar de GuidLowFragmentation seriële kosten voor query's, 44,68, liggen nu onder de waarde 'kostendrempel voor parallellisme' (onthoud dat de geschatte parallelle kosten 38,80 waren), dus we krijgen een serieel uitvoeringsplan:
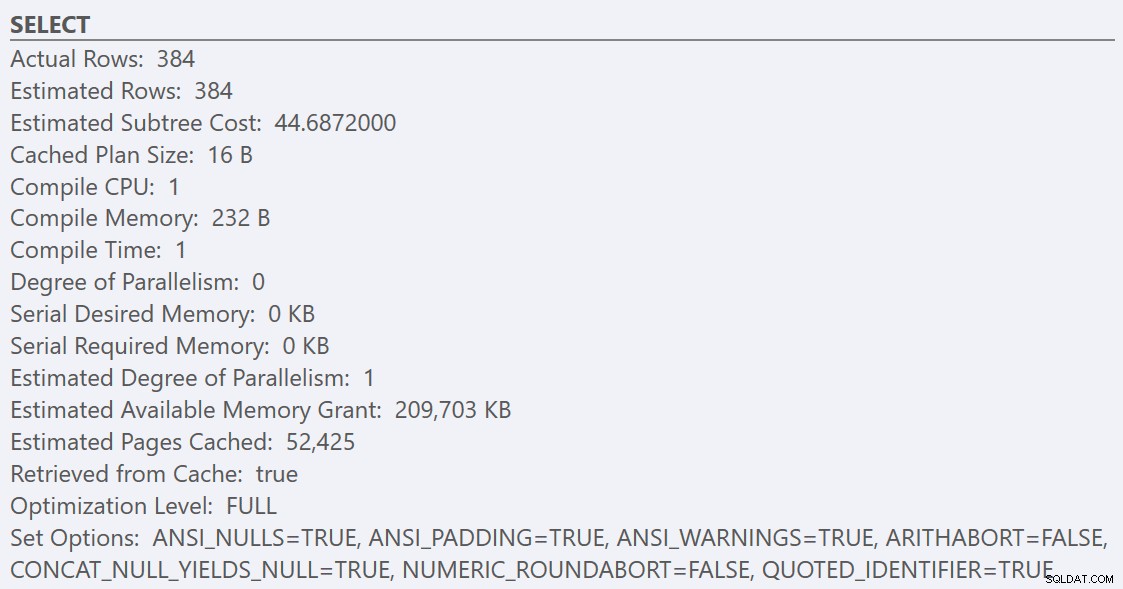
De extra paginaruimte in de GuidHighFragmentation geclusterde index hield de kosten boven de best-practice-instelling voor 'kostendrempel voor parallellisme' en resulteerde in een parallel plan.
Stel je nu voor dat dit een systeem was waarbij je de best-practice-richtlijnen volgde en aanvankelijk de 'kostendrempel voor parallellisme' op een waarde van 50 configureerde. Later volgde je het misplaatste advies om indexfragmentatie gewoon helemaal te negeren.
In plaats van dat dit een basisquery is, is het complexer, maar als het ook heel vaak op uw systeem wordt uitgevoerd, en als gevolg van indexfragmentatie, kantelt het aantal pagina's de kosten naar een parallel plan, dan zal het meer CPU en gevolgen hebben voor de algehele werklastprestaties.
Wat doe je? Verhoogt u de 'kostendrempel voor parallellisme' zodat de query een serieel uitvoeringsplan onderhoudt? Geef je de query een hint met OPTION(MAXDOP 1) en forceer je deze gewoon tot een serieel uitvoeringsplan?
Houd er rekening mee dat indexfragmentatie waarschijnlijk niet alleen van invloed is op één tabel in uw database, nu u deze volledig negeert; het is waarschijnlijk dat veel geclusterde en niet-geclusterde indexen gefragmenteerd zijn en een hoger dan nodig aantal pagina's hebben, dus de kosten van veel I/O-bewerkingen nemen toe als gevolg van de wijdverbreide indexfragmentatie, wat kan leiden tot mogelijk veel inefficiënte zoekopdrachten plannen.
Samenvatting
U kunt indexfragmentatie niet volledig negeren, zoals sommigen u misschien willen doen geloven. Naast andere nadelen hiervan, zullen de geaccumuleerde kosten van het uitvoeren van query's u inhalen, met verschuivingen in het queryplan omdat de query-optimizer een op kosten gebaseerde optimizer is en die gefragmenteerde indexen dus terecht als duurder in gebruik beschouwt.
De query's en het scenario hier zijn duidelijk gekunsteld, maar we hebben wijzigingen in het uitvoeringsplan gezien als gevolg van fragmentatie in het echte leven op clientsystemen.
U moet ervoor zorgen dat u indexfragmentatie aanpakt voor die indexen waar fragmentatie prestatieproblemen met de werkbelasting veroorzaakt, ongeacht de hardware die u gebruikt.