De IGNORE_DUP_KEY optie voor unieke indexen specificeert hoe SQL Server reageert op een poging tot INSERT dubbele waarden:het is alleen van toepassing op tabellen (geen weergaven) en alleen op invoegingen. Elk invoeggedeelte van een MERGE statement negeert elke IGNORE_DUP_KEY indexinstelling.
Wanneer IGNORE_DUP_KEY is OFF , het eerste gevonden duplicaat resulteert in een fout , en geen van de nieuwe rijen is ingevoegd.
Wanneer IGNORE_DUP_KEY is ON , worden ingevoegde rijen die de uniciteit zouden schenden weggegooid. De overige rijen zijn succesvol ingevoegd. Een waarschuwing bericht wordt verzonden in plaats van een fout:
Artikelsamenvatting
De IGNORE_DUP_KEY index-optie kan worden opgegeven voor zowel geclusterde als niet-geclusterde unieke indexen. Het gebruik ervan op een geclusterde index kan resulteren in veel slechtere prestaties dan voor een niet-geclusterde unieke index.
De grootte van het prestatieverschil hangt af van hoeveel uniciteitsschendingen worden aangetroffen tijdens de INSERT operatie. Hoe meer schendingen, hoe slechter de geclusterde unieke index presteert in vergelijking. Als er helemaal geen overtredingen zijn, kan de geclusterde index-insertie zelfs beter presteren.
Geclusterde unieke index-inserts
Voor een geclusterde unieke index met IGNORE_DUP_KEY ingesteld, worden duplicaten afgehandeld door de opslagengine .
Veel van het werk dat nodig is om elke rij in te voegen, wordt uitgevoerd voordat het duplicaat wordt gedetecteerd. Bijvoorbeeld een geclusterde index-insert de operator navigeert door de geclusterde index b-tree naar het punt waar de nieuwe rij zou komen, waarbij hij paginavergrendelingen en de gebruikelijke hiërarchie van sloten gebruikt, voordat hij de dubbele sleutel ontdekt.
Wanneer de dubbele sleutelvoorwaarde wordt gedetecteerd, wordt een fout wordt verhoogd. In plaats van de uitvoering te annuleren en de fout terug te sturen naar de klant, wordt de fout intern afgehandeld. De problematische rij wordt niet ingevoegd en de uitvoering gaat door, op zoek naar de volgende rij om in te voegen. Als die rij een dubbele sleutel aantreft, wordt een nieuwe fout gemeld en afgehandeld, enzovoort.
Uitzonderingen zijn erg duur om te gooien en te vangen. Een aanzienlijk aantal duplicaten zal de uitvoering aanzienlijk vertragen.
Niet-geclusterde unieke index-inserts
Voor een niet-geclusterde unieke index met IGNORE_DUP_KEY ingesteld, worden duplicaten afgehandeld door de queryprocessor . Duplicaten worden gedetecteerd en er wordt een waarschuwing afgegeven voordat wordt geprobeerd om in te voegen.
De queryprocessor verwijdert duplicaten uit de invoegstroom, zodat er geen duplicaten worden gezien door de opslagengine. Als gevolg hiervan worden er geen unieke fouten met sleutelovertredingen gemeld of intern afgehandeld.
De afweging
Er is een afweging tussen de kosten van het detecteren en verwijderen van dubbele sleutels in het uitvoeringsplan, versus de kosten van het uitvoeren van aanzienlijk invoeggerelateerd werk, en het weggooien en opvangen van fouten wanneer een duplicaat wordt gevonden.
Als duplicaten naar verwachting zeer zeldzaam zijn , is de storage engine-oplossing (clustered index) wellicht efficiënter. Wanneer duplicaten minder zeldzaam zijn, zal de benadering van de queryprocessor waarschijnlijk vruchten afwerpen. Het exacte kruispunt is afhankelijk van factoren zoals de runtime-efficiëntie van de componenten van het uitvoeringsplan die worden gebruikt om duplicaten te detecteren en te verwijderen.
De rest van dit artikel biedt een demo en gaat in meer detail in op waarom de storage engine-aanpak zo slecht kan presteren.
Demo
Het volgende script maakt een tijdelijke tabel met een miljoen rijen. Het heeft 1.000 unieke waarden en 1.000 rijen voor elke unieke waarde. Deze gegevensset wordt gebruikt als gegevensbron voor invoegingen in tabellen met verschillende indexconfiguraties.
DROP TABLE IF EXISTS #Data;
GO
CREATE TABLE #Data (c1 integer NOT NULL);
GO
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE
@Loop integer = 1,
@N integer = 1;
WHILE @N <= 1000
BEGIN
SET @Loop = 1;
BEGIN TRANSACTION;
-- Add 1,000 copies of the current loop value
WHILE @Loop <= 50
BEGIN
INSERT #Data
(c1)
VALUES
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N);
SET @Loop += 1;
END;
COMMIT TRANSACTION;
SET @N += 1;
END;
CREATE CLUSTERED INDEX cx
ON #Data (c1)
WITH (MAXDOP = 1); Basislijn
Het volgende invoegen in een tabelvariabele met een niet-unieke geclusterde index duurt ongeveer 900 ms :
DECLARE @T table
(
c1 integer NOT NULL
INDEX cuq CLUSTERED (c1)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D;
Let op het ontbreken van IGNORE_DUP_KEY op de doeltabelvariabele.
Geclusterde unieke index
Dezelfde gegevens invoegen in een unieke geclusterde index met IGNORE_DUP_KEY zet ON duurt ongeveer 15.900 ms — bijna 18 keer erger:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Niet-geclusterde unieke index
De gegevens invoegen in een unieke niet-geclusterde index met IGNORE_DUP_KEY zet ON duurt ongeveer 700 ms :
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE NONCLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Prestatiesamenvatting
De basislijntest duurt 900 ms om alle een miljoen rijen in te voegen. De niet-geclusterde indextest duurt 700 ms om alleen de 1000 verschillende sleutels in te voegen. De geclusterde indextest duurt 15.900 ms om dezelfde 1.000 unieke rijen in te voegen.
Deze test is met opzet opgezet om slechte prestaties van de opslagengine-implementatie aan het licht te brengen, door voor elke succesvolle rij 999 eenheden verspild werk (vergrendelingen, vergrendelingen, foutafhandeling) te genereren.
Het bedoelde bericht is niet dat IGNORE_DUP_KEY zal altijd slecht presteren op geclusterde indexen, alleen dat zou kunnen, en er kan een groot verschil zijn tussen geclusterde en niet-geclusterde indexen.
Geclusterd Index Uitvoeringsplan
Er is niet veel te zien in het geclusterde index-invoegplan:
Er worden 1.000.000 rijen doorgegeven aan de Geclusterde Index Insert operator, die wordt weergegeven als 'terugkerende' 1.000 rijen. Als we in de details van het plan duiken, kunnen we zien:
- 1.244.008 logische reads bij de insert-operator.
- Het overgrote deel van de uitvoeringstijd wordt besteed aan de Invoegen operator.
- 11ms van
SOS_SCHEDULER_YIELDwacht (d.w.z. geen andere wacht).
Niets dat de 15.900 ms echt verklaart van de verstreken tijd.
Waarom de prestaties zo slecht zijn
Het is duidelijk dat dit plan voor elke rij veel werk zal moeten verzetten:
- Navigeer door de geclusterde index b-tree-niveaus, vergrendelend en vergrendelend zoals het gaat, om het invoegpunt voor het nieuwe record te vinden.
- Als een van de benodigde indexpagina's zich niet in het geheugen bevindt, moeten ze van de schijf worden opgehaald.
- Maak een nieuwe b-tree-rij in het geheugen.
- Bereid logrecords voor.
- Als een sleutelduplicaat wordt gevonden (dat is geen spookrecord), maak dan een fout aan, behandel die fout intern, laat de huidige rij los en ga verder op een geschikt punt in de code om de volgende kandidaatrij te verwerken. li>
Dat is allemaal behoorlijk wat werk, en onthoud dat het allemaal voor elke rij happens gebeurt .
Het deel waar ik me op wil concentreren is het verhogen en afhandelen van fouten, omdat het extreem is duur. De overige hierboven genoemde aspecten zijn al zo goedkoop mogelijk gemaakt door in de demo een tabelvariabele en tijdelijke tabel te gebruiken.
Uitzonderingen
Het eerste wat ik wil doen is laten zien dat de Geclusterde Index Insert operator maakt echt een uitzondering wanneer hij een dubbele sleutel tegenkomt.
Een manier om dit direct te laten zien, is door een debugger toe te voegen en een stacktracering vast te leggen op het punt waarop de uitzondering wordt gegenereerd:
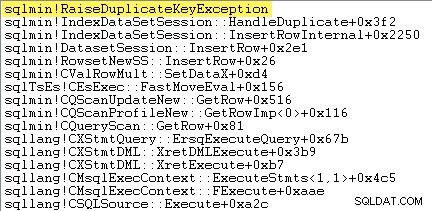
Het belangrijkste punt hier is dat het gooien en vangen van uitzonderingen erg duur is.
Monitoring van SQL Server met Windows Performance Recorder terwijl de test liep, en analyse van de resultaten in Windows Performance Analyzer toont:
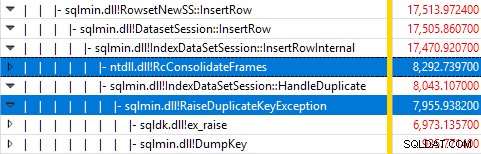
Bijna alle uitvoeringstijd van de query wordt besteed in sqlmin!IndexDataSetSession::InsertRowInternal zoals zou worden verwacht voor een zoekopdracht die weinig anders doet dan rijen invoegen.
De verrassing is dat 45% van die tijd wordt besteed aan het genereren van uitzonderingen via sqlmin!RaiseDuplicateKeyException en nog eens 47% wordt besteed aan het bijbehorende catch-blok voor uitzonderingen (de ntdll!RcConsolidateFrames hiërarchie).
Samenvattend:het melden en ondervangen van uitzonderingen is goed voor 92% van de uitvoeringstijd van onze test-query voor het invoegen van geclusterde indexen.
Problemen met het verzamelen van gegevens
Lezers met een scherpe blik kunnen een aanzienlijk deel – ongeveer 12% – van de uitzonderlijke tijd die wordt besteed aan sqlmin!DumpKey opmerken. in de Windows Performance Analyzer-afbeelding. Dit is de moeite waard om snel te onderzoeken, samen met een aantal gerelateerde items.
Als onderdeel van het genereren van een uitzondering moet SQL Server enkele gegevens verzamelen die alleen beschikbaar zijn op het moment dat de fout optrad. Het foutnummer dat is gekoppeld aan een dubbele sleuteluitzondering is 2627. De berichttekst in sys.messages voor dat foutnummer is:
Informatie om die plaatsmarkeringen te vullen, moet worden verzameld op het moment dat de fout wordt gemeld - deze zal later niet beschikbaar zijn! Dat betekent dat u het type beperking, de naam, de volledige naam van het doelobject en de specifieke sleutelwaarde moet opzoeken en opmaken. Dat kost allemaal tijd.
De volgende stacktracering toont de server die de dubbele sleutelwaarde opmaakt als een Unicode-tekenreeks tijdens de DumpKey bel:
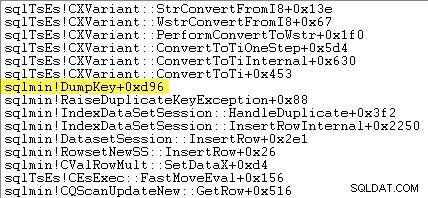
Het afhandelen van uitzonderingen omvat ook het vastleggen van een stacktracering:
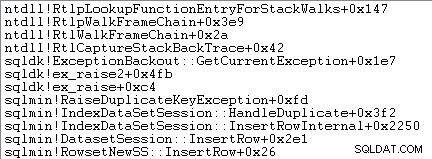
SQL Server registreert ook informatie over uitzonderingen (inclusief stapelframes) in een kleine ringbuffer, zoals het volgende laat zien:
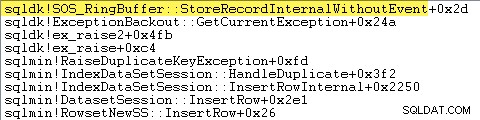
U kunt die ringbuffervermeldingen zien met een commando als:
SELECT TOP (10)
date_time =
DATEADD
(
MILLISECOND,
DORB.[timestamp] - DOSI.ms_ticks,
SYSDATETIME()
),
record = CONVERT(xml, DORB.record)
FROM sys.dm_os_ring_buffers AS DORB
CROSS JOIN sys.dm_os_sys_info AS DOSI
WHERE
DORB.ring_buffer_type = N'RING_BUFFER_EXCEPTION'
ORDER BY
DORB.[timestamp] DESC; Een voorbeeld van het xml-record voor een duplicaatsleuteluitzondering volgt. Let op de stapelframes:
<Record id="4611442" type="RING_BUFFER_EXCEPTION" time="93079430">
<Exception>
<Task address="0x00000245B5E1FC28" />
<Error>2627</Error>
<Severity>14</Severity>
<State>1</State>
<UserDefined>0</UserDefined>
<Origin>0</Origin>
</Exception>
<Stack>
<frame id="0">0X00007FFAC659E80A</frame>
<frame id="1">0X00007FFACBAC0EFD</frame>
<frame id="2">0X00007FFACBAA1252</frame>
<frame id="3">0X00007FFACBA9E040</frame>
<frame id="4">0X00007FFACAB55D53</frame>
<frame id="5">0X00007FFACAB55C06</frame>
<frame id="6">0X00007FFACB3E3D0B</frame>
<frame id="7">0X00007FFAC92020EC</frame>
<frame id="8">0X00007FFACAB5B2FA</frame>
<frame id="9">0X00007FFACABA3B9B</frame>
<frame id="10">0X00007FFACAB3D89F</frame>
<frame id="11">0X00007FFAC6A9D108</frame>
<frame id="12">0X00007FFAC6AB2BBF</frame>
<frame id="13">0X00007FFAC6AB296F</frame>
<frame id="14">0X00007FFAC6A9B7D0</frame>
<frame id="15">0X00007FFAC6A9B233</frame>
</Stack>
</Record> Al dit achtergrondwerk gebeurt voor elke uitzondering. In onze test betekent dit dat het 999.000 keer gebeurt - één keer voor elke rij die een dubbele sleutelovertreding tegenkomt.
Er zijn veel manieren om dit te zien, bijvoorbeeld door een Profiler-tracering uit te voeren met behulp van de Uitzondering gebeurtenis in de Fouten en waarschuwingen klas. In onze testcase zal dit uiteindelijk produceer 999.000 rijen met TextData elementen zoals deze:
Schending van UNIQUE KEY-beperking 'UQ__#AC166DE__3213663B8B6E2E0E'Kan geen dubbele sleutel invoegen in object 'dbo.@T'.
De dubbele sleutelwaarde is (173).
Het toevoegen van Profiler betekent dat elke gebeurtenis voor het afhandelen van uitzonderingen veel extra overhead met zich meebrengt, omdat de extra benodigde gegevens worden verzameld en geformatteerd. De eerder genoemde standaardgegevens worden altijd verzameld, zelfs als niemand de informatie actief gebruikt.
Voor alle duidelijkheid:de prestatiecijfers die in dit artikel worden vermeld, zijn allemaal verkregen zonder dat er een debugger is aangesloten en er is geen andere actieve monitoring.
Niet-geclusterd Index Uitvoeringsplan
Ondanks dat het zo veel sneller is, is het plan voor het invoegen van niet-geclusterde indexen een stuk ingewikkelder, dus ik zal het in twee delen splitsen.
Het algemene thema is dat dit plan sneller is omdat het dubbele voor . elimineert proberen ze in de doeltabel in te voegen.
Deel 1
Eerst de rechterkant van het niet-geclusterde indexplan:
Dit deel van het plan verwerpt alle rijen die een sleutelovereenkomst hebben in de doeltabel voor de unieke index met IGNORE_DUP_KEY zet ON .
Misschien verwacht je een Anti Semi Join hier, maar SQL Server heeft niet de benodigde infrastructuur om de vereiste dubbele sleutelwaarschuwing af te geven met een Anti Semi Join exploitant. (Als dat nog niet logisch is, zou het binnenkort moeten gebeuren.)
In plaats daarvan krijgen we een abonnement met een aantal interessante functies:
- De geclusterde indexscan is
Ordered:Trueom input te leveren voor de links semi-join samenvoegen gesorteerd op kolomc1in de#Datatafel. - De Indexscan van de tabelvariabele is
Ordered:False - Het Sorteren orden rijen per kolom
c1in de tabelvariabele. Deze bestelling kan zijn geleverd door een bestelde scan van de tabelvariabele index opc1, maar de optimizer beslist de Sorteren is de goedkoopste manier om het vereiste niveau van Halloween-bescherming te bieden. - De tabelvariabele Index Scan heeft interne
UPDLOCKenSERIALIZABLEhints toegepast om de stabiliteit van het doel te garanderen tijdens de uitvoering van het plan. - De links semi-join samenvoegen controleert op overeenkomsten in de tabelvariabele voor elke waarde van
c1geretourneerd van de#Datatafel. In tegenstelling tot een gewone semi-join, zendt het elke rij uit die op zijn bovenste invoer wordt ontvangen. Het zet een vlag in een sondekolom om aan te geven of de huidige rij een overeenkomst heeft gevonden of niet. De sondekolom wordt uitgezonden vanuit de Links semi-join samenvoegen als een uitdrukking met de naamExpr1012. - De Bewering operator controleert de waarde van de sondekolom
Expr1012. De eerste keer dat het een rij ziet met een niet-null-testkolomwaarde (wat aangeeft dat er een indexsleutelovereenkomst is gevonden), geeft het een "Dubbele sleutel werd genegeerd" bericht. - De Bewering geeft alleen rijen door waar de sondekolom nul is. Dit elimineert inkomende rijen die een dubbele sleutelfout zouden veroorzaken.
Dat lijkt misschien allemaal ingewikkeld, maar het is in wezen net zo eenvoudig als het instellen van een vlag als er een overeenkomst wordt gevonden, een waarschuwing afgeven wanneer de vlag voor het eerst wordt ingesteld en alleen rijen doorgeven aan de invoeging die nog niet in de doeltabel staan .
Deel 2
Het tweede deel van het plan volgt de Assert operator:
In het vorige deel van het plan werden rijen verwijderd die een overeenkomst hadden in de doeltabel. Dit deel van het plan verwijdert duplicaten binnen de invoegset .
Stel je bijvoorbeeld voor dat er geen rijen in de doeltabel zijn waar c1 = 1 . We kunnen nog steeds een dubbele sleutelfout veroorzaken als we proberen twee rijen in te voegen met c1 = 1 uit de brontabel. We moeten dat vermijden om de semantiek van IGNORE_DUP_KEY = ON te respecteren .
Dit aspect wordt afgehandeld door het Segment en Boven operators.
Het segment operator stelt een nieuwe vlag in (met het label Segment1015 ) wanneer het een rij tegenkomt met een nieuwe waarde voor c1 . Aangezien rijen worden weergegeven in c1 bestelling (dankzij de orderbehoudende Samenvoegen ), kan het plan vertrouwen op alle rijen met dezelfde c1 waarde arriveert in een aaneengesloten stroom.
De Top operator geeft één rij door voor elke groep duplicaten, zoals aangegeven door het Segment vlag. Als de Boven operator komt meer dan één rij tegen voor hetzelfde Segment groep (c1 waarde), geeft het een "Dubbele sleutel werd genegeerd" waarschuwing, als dat de eerste keer is dat het plan die voorwaarde tegenkomt.
Het netto-effect van dit alles is dat er slechts één rij wordt doorgegeven aan de invoegoperators voor elke unieke waarde van c1 , en indien nodig wordt er een waarschuwing gegenereerd.
Het uitvoeringsplan heeft nu alle mogelijke dubbele sleutelovertredingen geëlimineerd, dus de resterende Tabel invoegen en Index invoegen operators kunnen veilig rijen invoegen in de heap en niet-geclusterde index zonder angst voor een dubbele sleutelfout.
Onthoud dat de UPDLOCK en SERIALIZABLE hints toegepast op de doeltabel zorgen ervoor dat de set niet kan veranderen tijdens de uitvoering. Met andere woorden, een gelijktijdige instructie kan de doeltabel niet zodanig wijzigen dat er een dubbele sleutelfout zou optreden bij de Insert exploitanten. Dat is hier geen probleem omdat we een privétabelvariabele gebruiken, maar SQL Server voegt de hints nog steeds toe als algemene veiligheidsmaatregel.
Zonder die hints zou een gelijktijdig proces een rij aan de doeltabel kunnen toevoegen die een dubbele sleutelovertreding zou genereren, ondanks de controles die zijn uitgevoerd door deel 1 van het plan. SQL Server moet er zeker van zijn dat de resultaten van de bestaanscontrole geldig blijven.
De nieuwsgierige lezer kan enkele van de hierboven beschreven functies zien door traceringsvlaggen 3604 en 8607 in te schakelen om de uitvoerstructuur van de optimalisatie te zien:
PhyOp_RestrRemap
PhyOp_StreamUpdate(INS TBL: @T, iid 0x2 as IDX, Sort(QCOL: .c1, )), {
- COL: Bmk10001013 = COL: Bmk1000
- COL: c11014 = QCOL: .c1}
PhyOp_StreamUpdate(INS TBL: @T, iid 0x0 as TBLInsLocator(COL: Bmk1000 ) REPORT-COUNT), {
- QCOL: .c1= QCOL: [D].c1}
PhyOp_GbTop Group(QCOL: [D].c1,) WARN-DUP
PhyOp_StreamCheck (WarnIgnoreDuplicate TABLE)
PhyOp_MergeJoin x_jtLeftSemi M-M, Probe COL: Expr1012 ( QCOL: [D].c1) = ( QCOL: .c1)
PhyOp_Range TBL: #Data(alias TBL: D)(1) ASC
PhyOp_Sort +s -d QCOL: .c1
PhyOp_Range TBL: @T(2) ASC Hints( UPDLOCK SERIALIZABLE FORCEDINDEX )
ScaOp_Comp x_cmpIs
ScaOp_Identifier QCOL: [D].c1
ScaOp_Identifier QCOL: .c1
ScaOp_Logical x_lopIsNotNull
ScaOp_Identifier COL: Expr1012
Laatste gedachten
De IGNORE_DUP_KEY index-optie is niet iets dat de meeste mensen heel vaak zullen gebruiken. Toch is het interessant om te kijken hoe deze functionaliteit wordt geïmplementeerd en waarom er grote prestatieverschillen kunnen zijn tussen IGNORE_DUP_KEY op geclusterde en niet-geclusterde indexen.
In veel gevallen loont het om het voorbeeld van de queryprocessor te volgen en query's te schrijven die duplicaten expliciet elimineren, in plaats van te vertrouwen op IGNORE_DUP_KEY . In ons voorbeeld zou dat betekenen dat je schrijft:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED -- no IGNORE_DUP_KEY!
);
INSERT @T
(c1)
SELECT DISTINCT -- Remove duplicates
D.c1
FROM #Data AS D; Dit wordt uitgevoerd in ongeveer 400ms , voor de goede orde.