Dit artikel is het vierde deel in een serie over T-SQL-bugs, valkuilen en best practices. Eerder behandelde ik determinisme, subquery's en joins. De focus van het artikel van deze maand ligt op bugs, valkuilen en best practices met betrekking tot vensterfuncties. Bedankt Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man en Paul White voor het aanbieden van uw ideeën!
In mijn voorbeelden gebruik ik een voorbeelddatabase met de naam TSQLV5. U vindt het script dat deze database maakt en vult hier, en het ER-diagram hier.
Er zijn twee veelvoorkomende valkuilen met betrekking tot vensterfuncties, die beide het gevolg zijn van contra-intuïtieve impliciete standaardinstellingen die worden opgelegd door de SQL-standaard. Een valkuil heeft te maken met berekeningen van lopende totalen waarbij je een raamkozijn krijgt met de impliciete RANGE-optie. Een andere valkuil is enigszins verwant, maar heeft ernstigere gevolgen, met een impliciete framedefinitie voor de FIRST_VALUE- en LAST_VALUE-functies.
Vensterkozijn met impliciete RANGE-optie
Onze eerste valkuil is de berekening van lopende totalen met behulp van een geaggregeerde vensterfunctie, waarbij u wel expliciet de raamvolgorde-clausule specificeert, maar niet expliciet de raamkozijneenheid (ROWS of RANGE) en de gerelateerde raamkozijnomvang specificeert, bijv. RIJEN ONGEBONDEN VOORAFGAAND. De impliciete standaard is contra-intuïtief en de gevolgen ervan kunnen verrassend en pijnlijk zijn.
Om deze valkuil te demonstreren, gebruik ik een tabel met de naam Transacties met twee miljoen bankrekeningtransacties met tegoeden (positieve waarden) en afschrijvingen (negatieve waarden). Voer de volgende code uit om de tabel Transacties te maken en vul deze met voorbeeldgegevens:
STEL NOCOUNT IN; GEBRUIK TSQLV5; -- https://tsql.solidq.com/SampleDatabases/TSQLV5.zip DROP TABEL INDIEN BESTAAT dbo.Transactions; MAAK TABEL dbo.Transactions (actid INT NIET NULL, tranid INT NIET NULL, val GELD NIET NULL, CONSTRAINT PK_Transactions PRIMAIRE SLEUTEL (actid, tranid) - creëert POC-index); DECLARE @num_partitions AS INT =100, @rows_per_partition AS INT =20000; INSERT INTO dbo.Transactions WITH (TABLOCK) (actid, tranid, val) SELECT NP.n, RPP.n, (ABS(CHECKSUM(NEWID())%2)*2-1) * (1 + ABS(CHECKSUM( NEWID())%5)) VAN dbo.GetNums(1, @num_partitions) AS NP CROSS JOIN dbo.GetNums(1, @rows_per_partition) AS RPP;
Onze valkuil heeft zowel een logische kant met een mogelijke logische bug als een prestatiekant met een prestatiestraf. De prestatievermindering is alleen relevant wanneer de vensterfunctie is geoptimaliseerd met bewerkingsoperators in rijmodus. SQL Server 2016 introduceert de batch-modus Window Aggregate-operator, die het prestatieverlies van de valkuil verwijdert, maar vóór SQL Server 2019 wordt deze operator alleen gebruikt als er een columnstore-index aanwezig is op de gegevens. SQL Server 2019 introduceert batch-modus op rowstore-ondersteuning, zodat u batch-modus-verwerking kunt krijgen, zelfs als er geen columnstore-indexen op de gegevens aanwezig zijn. Gebruik de volgende code om het compatibiliteitsniveau van de database in te stellen op 140 als u de codevoorbeelden in dit artikel in dit artikel op SQL Server 2019 of hoger of op Azure SQL Database wilt demonstreren om de prestatievermindering met de verwerking in de rijmodus te demonstreren. om batch-modus op rijopslag nog niet in te schakelen:
WIJZIG DATABASE TSQLV5 SET COMPATIBILITY_LEVEL =140;
Gebruik de volgende code om tijd- en I/O-statistieken in de sessie in te schakelen:
STEL STATISTIEKEN TIJD IN, IO AAN;
Om te voorkomen dat twee miljoen rijen in SSMS moeten worden afgedrukt, raad ik aan de codevoorbeelden in deze sectie uit te voeren met de optie Resultaten negeren na uitvoering ingeschakeld (ga naar Query-opties, Resultaten, Raster en vink Resultaten negeren na uitvoering aan).
Voordat we bij de valkuil komen, overweeg dan de volgende query (noem het Query 1) die het bankrekeningsaldo na elke transactie berekent door een lopend totaal toe te passen met behulp van een vensteraggregatiefunctie met een expliciete framespecificatie:
SELECTEER actid, tranid, val, SUM(val) OVER (VERDELING DOOR actid ORDER DOOR tranid RIJEN ONGEBONDEN VOORAFGAANDE) ALS saldo VAN dbo.Transacties;
Het plan voor deze zoekopdracht, waarbij gebruik wordt gemaakt van rijmodusverwerking, wordt weergegeven in afbeelding 1.
 Figuur 1:Plan voor Query 1, verwerking in rijmodus
Figuur 1:Plan voor Query 1, verwerking in rijmodus
Het plan haalt de vooraf bestelde gegevens uit de geclusterde index van de tabel. Vervolgens gebruikt het de operators Segment en Sequence Project om rijnummers te berekenen om erachter te komen welke rijen bij het frame van de huidige rij horen. Vervolgens gebruikt het de operators Segment, Window Spool en Stream Aggregate om de window-aggregatiefunctie te berekenen. De Window Spool-operator wordt gebruikt om de framerijen te spoolen die vervolgens moeten worden geaggregeerd. Zonder enige speciale optimalisatie zou het plan per rij alle toepasselijke framerijen naar de spoel moeten schrijven en deze vervolgens moeten samenvoegen. Dit zou hebben geleid tot kwadratische of N-complexiteit. Het goede nieuws is dat wanneer het frame begint met UNBOUNDED PRECEDING, SQL Server de casus identificeert als een fast track geval, waarin het gewoon het lopende totaal van de vorige rij neemt en de waarde van de huidige rij optelt om het lopende totaal van de huidige rij te berekenen, wat resulteert in lineaire schaling. In deze fast track-modus schrijft het plan slechts twee rijen naar de spoel per invoerrij:één met het totaal en één met de details.
De Window Spool kan op twee manieren fysiek worden geïmplementeerd. Ofwel als een snelle spool in het geheugen die speciaal is ontworpen voor vensterfuncties, of als een langzame spool op de schijf, die in wezen een tijdelijke tabel in tempdb is. Als het aantal rijen dat naar de spoel moet worden geschreven per onderliggende rij kan de 10.000 overschrijden, of als SQL Server het aantal niet kan voorspellen, gebruikt het de langzamere spool op de schijf. In ons queryplan hebben we precies twee rijen geschreven naar de spool per onderliggende rij, dus SQL Server gebruikt de in-memory spool. Helaas is er geen manier om uit het plan te zien wat voor soort spoel je krijgt. Er zijn twee manieren om dit te achterhalen. Een daarvan is het gebruik van een uitgebreide gebeurtenis genaamd window_spool_ondisk_warning. Een andere optie is om STATISTICS IO in te schakelen en het aantal logische leesbewerkingen te controleren dat is gerapporteerd voor een tabel met de naam Worktable. Een getal groter dan nul betekent dat u de spool op de schijf hebt. Nul betekent dat je de spoel in het geheugen hebt. Dit zijn de I/O-statistieken voor onze vraag:
Tabel 'Werktafel' logische leest:0. Tabel 'Transacties' logische leest:6208.Zoals je kunt zien, hebben we de in-memory spoel gebruikt. Dat is over het algemeen het geval wanneer u de ROWS raamkozijneenheid gebruikt met UNBOUNDED PRECEDING als eerste scheidingsteken.
Dit zijn de tijdstatistieken voor onze zoekopdracht:
CPU-tijd:4297 ms, verstreken tijd:4441 ms.Het kostte deze query ongeveer 4,5 seconden om op mijn computer te voltooien, waarbij de resultaten werden weggegooid.
Nu voor de vangst. Als u de optie BEREIK gebruikt in plaats van RIJEN, met dezelfde scheidingstekens, kan er een subtiel verschil in betekenis zijn, maar een groot verschil in prestatie in rijmodus. Het verschil in betekenis is alleen relevant als je geen totale bestelling hebt, d.w.z. als je iets bestelt dat niet uniek is. De optie RIJEN ONGEBONDEN PRECEDING stopt bij de huidige rij, dus in het geval van gelijkspel is de berekening niet-deterministisch. Omgekeerd kijkt de optie RANGE ONBOUNDED PRECEDING vooruit op de huidige rij, en bevat gelijkspel indien aanwezig. Het gebruikt vergelijkbare logica als de TOP WITH TIES-optie. Als je een totale bestelling hebt, d.w.z. je bestelt op iets unieks, zijn er geen banden om op te nemen, en daarom worden RIJEN en BEREIK in een dergelijk geval logisch equivalent. Het probleem is dat wanneer u RANGE gebruikt, SQL Server altijd de spool op de schijf gebruikt bij verwerking in rijmodus, aangezien het bij het verwerken van een bepaalde rij niet kan voorspellen hoeveel rijen er nog zullen worden opgenomen. Dit kan een ernstige prestatiestraf opleveren.
Overweeg de volgende query (noem deze Query 2), die hetzelfde is als Query 1, alleen met de optie RANGE in plaats van RIJEN:
SELECTEER actid, tranid, val, SUM(val) OVER (VERDELING DOOR actid ORDER DOOR tranid RANGE ONBOUNDED PRECEDING) ALS saldo VAN dbo.Transactions;
Het plan voor deze zoekopdracht wordt getoond in figuur 2.
 Figuur 2:Plan voor Query 2, verwerking in rijmodus
Figuur 2:Plan voor Query 2, verwerking in rijmodus
Query 2 is logisch gelijk aan Query 1 omdat we een totale volgorde hebben; omdat het echter RANGE gebruikt, wordt het geoptimaliseerd met de spool op de schijf. Merk op dat in het plan voor Query 2 de Window Spool er hetzelfde uitziet als in het plan voor Query 1, en dat de geschatte kosten hetzelfde zijn.
Hier zijn de tijd- en I/O-statistieken voor de uitvoering van Query 2:
CPU-tijd:19515 ms, verstreken tijd:20201 ms.Tabel 'Werktafel' logische leest:12044701. Tabel 'Transacties' logische leest:6208.
Let op het grote aantal logische reads tegen Worktable, wat aangeeft dat je de spool op de schijf hebt. De looptijd is meer dan vier keer langer dan voor Query 1.
Als je denkt dat als dat het geval is, je gewoon de RANGE-optie zult vermijden, tenzij je echt banden moet opnemen, dat is een goede gedachte. Het probleem is dat als u een vensterfunctie gebruikt die een frame ondersteunt (aggregaten, FIRST_VALUE, LAST_VALUE) met een expliciete venstervolgorde-clausule, maar geen melding maakt van de raamkozijneenheid en de bijbehorende omvang, u standaard RANGE UNBOUNDED PRECEDING krijgt . Deze standaard wordt gedicteerd door de SQL-standaard en de standaard koos ervoor omdat deze over het algemeen de voorkeur geeft aan meer deterministische opties als standaardinstellingen. De volgende query (noem het Query 3) is een voorbeeld dat in deze valkuil valt:
SELECTEER actid, tranid, val, SUM(val) OVER (PARTITION DOOR actid ORDER DOOR tranid) ALS saldo VAN dbo.Transactions;
Vaak schrijven mensen op deze manier in de veronderstelling dat ze standaard RIJEN ONBONDEN PRECEDING krijgen, zich niet realiserend dat ze eigenlijk RANGE UNBOUNDED PRECEDING krijgen. Het punt is dat, aangezien de functie de totale volgorde gebruikt, je hetzelfde resultaat krijgt als bij RIJEN, dus je kunt niet zien dat er een probleem is met het resultaat. Maar de prestatiecijfers die u krijgt, zijn die van Query 2. Ik zie mensen voortdurend in deze val trappen.
De beste werkwijze om dit probleem te vermijden is in gevallen waarin u een vensterfunctie met een kozijn gebruikt, expliciet te zijn over de kozijneenheid en de omvang ervan, en in het algemeen de voorkeur te geven aan RIJEN. Reserveer het gebruik van RANGE alleen voor gevallen waarin de bestelling niet uniek is en u stropdassen moet toevoegen.
Beschouw de volgende vraag die een geval illustreert waarin er een conceptueel verschil is tussen RIJEN en BEREIK:
SELECT orderdate, orderid, val, SUM(val) OVER( ORDER BY orderdate RIJEN UITGEBONDEN PRECEDING ) AS sumrows, SUM(val) OVER( ORDER BY orderdatum RANGE ONBOUNDED PRECEDING ) AS sumrange FROM Sales.OrderValues ORDER BY orderdate;
Deze query genereert de volgende uitvoer:
besteldatum bestel-ID val sumrows sumrange ---------- ------- -------- -------- -------- - 2017-07-04 10248 440,00 440,00 440,00 2017-07-05 10249 1863,40 2303,40 2303,40 2017-07-08 10250 1552,60 3856,00 4510,06 2017-07-08 10251 654,06 4510,06 4510,06 2017-07-09 10252 3597,90 8107,96 8107,96 ...
Let op het verschil in de resultaten voor de rijen waar dezelfde besteldatum meer dan één keer voorkomt, zoals het geval is voor 8 juli 2017. Merk op hoe de RIJEN-optie geen banden bevat en daarom niet-deterministisch is, en hoe de RANGE-optie dat wel doet omvat banden, en is daarom altijd deterministisch.
Het is echter de vraag of je in de praktijk gevallen hebt waarin je iets bestelt dat niet uniek is, en je echt banden moet opnemen om de berekening deterministisch te maken. Wat in de praktijk waarschijnlijk veel gebruikelijker is, is om een van de twee dingen te doen. Een daarvan is om banden te verbreken door iets aan de venstervolgorde toe te voegen om het uniek te maken en op deze manier te resulteren in een deterministische berekening, zoals:
SELECT orderdate, orderid, val, SUM(val) OVER( ORDER BY orderdate, orderid RIJEN ONGEBONDEN VOORAFGAANDE ) AS runningsum FROM Sales.OrderValues ORDER BY orderdate;
Deze query genereert de volgende uitvoer:
besteldatum bestel-ID val runningsum ---------- -------- --------- ----------- 2017-07-04 10248 440,00 440,00 2017-07-05 10249 1863,40 2303,40 2017-07-08 10250 1552,60 3856,00 2017-07-08 10251 654,06 4510,06 2017-07-09 10252 3597,90 8107,96 ...
Een andere optie is om voorlopige groepering toe te passen, in ons geval op besteldatum, zoals:
SELECT orderdate, SUM(val) AS daytotal, SUM(SUM(val)) OVER( ORDER BY orderdatum RIJEN ONGEBONDEN VOORAFGAANDE ) AS runningsum FROM Sales.OrderValues GROUP OP orderdatum ORDER BY orderdatum;
Deze zoekopdracht genereert de volgende uitvoer waarbij elke besteldatum slechts één keer voorkomt:
besteldatum dagtotaal lopende som ---------- --------- ----------- 2017-07-04 440,00 440,00 2017-07-05 1863,40 2303,40 2017-07-08 2206.66 4510.06 2017-07-09 3597.90 8107.96 ...
Onthoud in ieder geval de best practice hier!
Het goede nieuws is dat als u SQL Server 2016 of later gebruikt en een columnstore-index op de gegevens aanwezig bent (zelfs als het een nepgefilterde columnstore-index is), of als u SQL Server 2019 of later gebruikt, of op Azure SQL Database, ongeacht de aanwezigheid van columnstore-indexen, worden alle drie de bovengenoemde query's geoptimaliseerd met de batch-modus Window Aggregate-operator. Met deze operator worden veel van de inefficiënties in de rijmodus geëlimineerd. Deze operator gebruikt helemaal geen spool, dus er is geen probleem van spool in het geheugen versus op schijf. Het maakt gebruik van meer geavanceerde verwerking waarbij het meerdere parallelle passages kan toepassen over het venster met rijen in het geheugen voor zowel RIJEN als BEREIK.
Om het gebruik van de batchmodus-optimalisatie te demonstreren, moet u ervoor zorgen dat uw databasecompatibiliteitsniveau is ingesteld op 150 of hoger:
WIJZIG DATABASE TSQLV5 SET COMPATIBILITY_LEVEL =150;
Voer Query 1 opnieuw uit:
SELECTEER actid, tranid, val, SUM(val) OVER (VERDELING DOOR actid ORDER DOOR tranid RIJEN ONGEBONDEN VOORAFGAANDE) ALS saldo VAN dbo.Transacties;
Het plan voor deze zoekopdracht wordt getoond in figuur 3.
 Figuur 3:Plan voor Query 1, batchverwerking
Figuur 3:Plan voor Query 1, batchverwerking
Dit zijn de prestatiestatistieken die ik voor deze zoekopdracht heb gekregen:
CPU-tijd:937 ms, verstreken tijd:983 ms.Tabel 'Transacties' logische leest:6208.
De looptijd is gedaald tot 1 seconde!
Voer Query 2 opnieuw uit met de expliciete RANGE-optie:
SELECTEER actid, tranid, val, SUM(val) OVER (VERDELING DOOR actid ORDER DOOR tranid RANGE ONBOUNDED PRECEDING) ALS saldo VAN dbo.Transactions;
Het plan voor deze zoekopdracht wordt getoond in figuur 4.
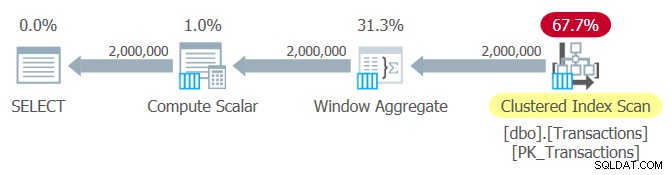 Figuur 2:Plan voor Query 2, batchverwerking
Figuur 2:Plan voor Query 2, batchverwerking
Dit zijn de prestatiestatistieken die ik voor deze zoekopdracht heb gekregen:
CPU-tijd:969 ms, verstreken tijd:1048 ms.Tabel 'Transacties' logische leest:6208.
De prestatie is hetzelfde als voor Query 1.
Voer Query 3 opnieuw uit, met de impliciete RANGE-optie:
SELECTEER actid, tranid, val, SUM(val) OVER (PARTITION DOOR actid ORDER DOOR tranid) ALS saldo VAN dbo.Transactions;
Het plan en de prestatiecijfers zijn natuurlijk hetzelfde als voor Query 2.
Als u klaar bent, voert u de volgende code uit om prestatiestatistieken uit te schakelen:
STEL STATISTIEKEN TIJD IN, IO UIT;
Vergeet ook niet de optie Resultaten negeren na uitvoering in SSMS uit te schakelen.
Impliciet frame met FIRST_VALUE en LAST_VALUE
De functies FIRST_VALUE en LAST_VALUE zijn offset-vensterfuncties die respectievelijk een uitdrukking uit de eerste of laatste rij in het raamkozijn retourneren. Het lastige hieraan is dat wanneer mensen ze voor de eerste keer gebruiken, ze zich vaak niet realiseren dat ze een frame ondersteunen, maar eerder denken dat ze van toepassing zijn op de hele partitie.
Overweeg de volgende poging om bestelinformatie te retourneren, plus de waarden van de eerste en laatste bestellingen van de klant:
SELECT custid, orderdate, orderid, val, FIRST_VALUE(val) OVER( PARTITION BY custid ORDER BY orderdate, orderid ) AS firstval, LAST_VALUE(val) OVER( PARTITION BY custid ORDER BY orderdate, orderid ) AS lastval FROM Sales. OrderValues BESTELLEN OP custid, orderdatum, orderid;
Als u ten onrechte denkt dat deze functies op de hele vensterpartitie werken, wat de mening is van veel mensen die deze functies voor de eerste keer gebruiken, verwacht u natuurlijk dat FIRST_VALUE de bestelwaarde van de eerste bestelling van de klant retourneert en LAST_VALUE de bestelwaarde van de laatste bestelling van de klant. In de praktijk ondersteunen deze functies echter een frame. Ter herinnering:met functies die een frame ondersteunen, krijg je standaard RANGE UNBOUNDED PRECEDING als je de raamvolgorde-clausule opgeeft, maar niet de raamkozijneenheid en de bijbehorende omvang. Met de FIRST_VALUE-functie krijgt u het verwachte resultaat, maar als uw zoekopdracht wordt geoptimaliseerd met operators voor rijmodus, betaalt u de boete voor het gebruik van de spool op de schijf. Met de functie LAST_VALUE is het nog erger. U betaalt niet alleen de boete van de spoel op schijf, maar in plaats van de waarde van de laatste rij in de partitie te krijgen, krijgt u de waarde van de huidige rij!
Hier is de uitvoer van de bovenstaande vraag:
custid orderdatum orderid val firstval lastval ------ ---------- -------- ---------- ------ ---- ---------- 1 2018-08-25 10643 814,50 814,50 814,50 1 2018-10-03 10692 878,00 814,50 878,00 1 2018-10-13 10702 330,00 814,50 330,00 1 2019-01-15 10835 845,80 814,50 845,80 1 2019-03-16 10952 471,20 814,50 471,20 1 2019-04-09 11011 933,50 814,50 933,50 2 2017-09-18 10308 88,80 88,80 88,80 2 2018-08-08 10625 479,75 88,80-11 479,75 2 2018 10759 320,00 88,80 320,00 2 2019-03-04 10926 514,40 88,80 514,40 3 2017-11-27 10365 403.20 403.20 403.20 3 2018-04-15 10507 749.06 403.20 749.06 3 2018-05-13 10535 1940.85 403.20 1940.85 3 2018-06-19 10573 2082,00 403.20 2082,00 3 2018-09-22 10677 813,37 403.20 813,37 3 2018-09-25 10682 375,50 403,20 375,50 3 2019-01-28 10856 660,00 403,20 660,00 ...
Wanneer mensen dergelijke uitvoer voor het eerst zien, denken ze vaak dat SQL Server een fout bevat. Maar dat doet het natuurlijk niet; het is gewoon de standaard van de SQL-standaard. Er zit een fout in de query. Als je je realiseert dat er een frame bij betrokken is, wil je expliciet zijn over de framespecificatie en het minimale frame gebruiken dat de rij vastlegt die je zoekt. Zorg er ook voor dat u de ROWS-eenheid gebruikt. Dus, om de eerste rij in de partitie te krijgen, gebruik je de FIRST_VALUE functie met het frame RIJEN TUSSEN ONGEBONDEN VORIGE EN HUIDIGE RIJ. Om de laatste rij in de partitie te krijgen, gebruikt u de functie LAST_VALUE met het frame RIJEN TUSSEN HUIDIGE RIJ EN NIET-GEBONDEN VOLGENDE.
Hier is onze herziene vraag met de bug opgelost:
SELECT custid, orderdate, orderid, val, FIRST_VALUE(val) OVER( PARTITION BY custid ORDER BY orderdatum, orderid RIJEN TUSSEN UNBOUNDED VOORAFGAANDE EN HUIDIGE RIJ ) AS firstval, LAST_VALUE(val) OVER( PARTITION BY custid, ORDER orderid RIJEN TUSSEN HUIDIGE RIJ EN ONGEBONDEN VOLGENDE ) ALS laatste waarde VAN Sales.OrderValues ORDER BY custid, orderdate, orderid;
Deze keer krijg je het juiste resultaat:
custid orderdatum orderid val firstval lastval ------ ---------- -------- ---------- ------ ---- ---------- 1 2018-08-25 10643 814,50 814,50 933,50 1 2018-10-03 10692 878,00 814,50 933,50 1 2018-10-13 10702 330,00 814,50 933,50 1 2019-01-15 10835 845,80 814,50 933,50 1 2019-03-16 10952 471,20 814,50 933,50 1 2019-04-09 11011 933,50 814,50 933,50 2 2017-09-18 10308 88,80 88,80 514,40 2 2018-08-08 10625 479,75 88,80-11 514,40 2 2018 10759 320,00 88,80 514,40 2 2019-03-04 10926 514,40 88,80 514,40 3 2017-11-27 10365 403.20 403.20 660,00 3 2018-04-15 10507 749,06 403.20 660,00 3 2018-05-13 10535 1940,85 403.20 660,00 3 2018-06-19 10573 2082,00 403.20 660,00 3 22-09-2018 10677 813,37 403.20 660,00 3 2018-09-25 10682 375,50 403,20 660,00 3 2019-01-28 10856 660,00 403,20 660,00 ...
Je vraagt je af wat de motivatie was voor de standaard om zelfs maar een frame met deze functies te ondersteunen. Als je erover nadenkt, zul je ze meestal gebruiken om iets uit de eerste of laatste rij in de partitie te halen. Als je de waarde nodig hebt van bijvoorbeeld twee rijen voor de huidige, in plaats van FIRST_VALUE te gebruiken met een frame dat begint met 2 PRECEDING, is het dan niet veel gemakkelijker om LAG te gebruiken met een expliciete offset van 2, zoals:
SELECTEER custid, orderdate, orderid, val, LAG(val, 2) OVER( PARTITION BY custid ORDER BY orderdate, orderid ) AS prevtwoval FROM Sales.OrderValues ORDER BY custid, orderdatum, orderid;
Deze query genereert de volgende uitvoer:
custid orderdatum orderid val prevtwoval ------- ---------- -------- ---------- ------- ---- 1 2018-08-25 10643 814,50 NULL 1 2018-10-03 10692 878,00 NULL 1 2018-10-13 10702 330,00 814,50 1 2019-01-15 10835 845,80 878,00 1 2019-03-16 10952 471,20 330,00 1 2019-04-09 11011 933,50 845,80 2 2017-09-18 10308 88,80 NULL 2 2018-08-08 10625 479,75 NULL 2 2018-11-28 10759 320,00 88,80 2 2019-03-04 10926 514,40 479,75 3 2017-11-27 10365 403.20 NULL 3 2018-04-15 10507 749.06 NULL 3 2018-05-13 10535 1940,85 403.20 3 2018-06-19 10573 2082,00 749,06 3 2018-09-22 10677 813,37 1940,85 3 2018-09-25 10682 375,50 2082,00 3 2019 -01-28 10856 660,00 813,37 ...
Blijkbaar is er een semantisch verschil tussen het bovenstaande gebruik van de LAG-functie en FIRST_VALUE met een frame dat begint met 2 PRECEDING. Bij de eerste krijg je, als een rij niet bestaat in de gewenste offset, standaard een NULL. Bij de laatste krijg je nog steeds de waarde van de eerste rij die aanwezig is, d.w.z. de waarde van de eerste rij in de partitie. Overweeg de volgende vraag:
SELECTEER custid, orderdate, orderid, val, FIRST_VALUE(val) OVER( PARTITION BY custid ORDER BY orderdate, orderid RIJEN TUSSEN 2 VOORGAANDE EN HUIDIGE RIJ ) ALS vorig UIT Sales.OrderValues ORDER BY custid, orderdatum, orderid; pre>Deze query genereert de volgende uitvoer:
custid orderdatum orderid val prevtwoval ------- ---------- -------- ---------- ------- ---- 1 2018-08-25 10643 814,50 814,50 1 2018-10-03 10692 878,00 814,50 1 2018-10-13 10702 330,00 814,50 1 2019-01-15 10835 845,80 878,00 1 2019-03-16 10952 471,20 330,00 1 2019-04-09 11011 933,50 845,80 2 2017-09-18 10308 88,80 88,80 2 2018-08-08 10625 479,75 88,80 2 2018-11-28 10759 320,00 88,80 2 2019-03-04 10926 514,40 479,75 3 2017-11-27 10365 403.20 403.20 3 2018-04-15 10507 749.06 403.20 3 2018-05-13 10535 1940,85 403.20 3 2018-06-19 10573 2082,00 749,06 3 2018-09-22 10677 813,37 1940,85 3 2018-09-25 10682 375,50 2082,00 3 2019 -01-28 10856 660,00 813,37 ...Merk op dat dit keer geen NULL's in de uitvoer zijn. Het heeft dus enige waarde om een frame met FIRST_VALUE en LAST_VALUE te ondersteunen. Zorg ervoor dat u de beste werkwijze onthoudt om altijd expliciet te zijn over de framespecificatie met deze functies, en om de RIJEN-optie te gebruiken met het minimale frame dat de rij bevat die u zoekt.
Conclusie
Dit artikel was gericht op bugs, valkuilen en best practices met betrekking tot vensterfuncties. Onthoud dat zowel de vensteraggregatiefuncties als de FIRST_VALUE en LAST_VALUE vensteroffsetfuncties een frame ondersteunen, en dat als u de venstervolgorde-clausule opgeeft, maar u de vensterframe-eenheid en de bijbehorende omvang niet specificeert, u RANGE UBOUNDED PRECEDING krijgt door standaard. Dit leidt tot prestatieverlies wanneer de query wordt geoptimaliseerd met operators voor rijmodus. Met de functie LAST_VALUE resulteert dit in het ophalen van de waarden uit de huidige rij in plaats van de laatste rij in de partitie. Vergeet niet expliciet te zijn over het frame en in het algemeen de voorkeur te geven aan de RIJEN-optie boven RANGE. Het is geweldig om de prestatieverbeteringen te zien met de batch-modus Window Aggregate-operator. Als het van toepassing is, wordt in ieder geval de prestatievalkuil geëlimineerd.