Vorige maand plaatste ik een uitdaging om een efficiënte nummerreeksgenerator te maken. De reacties waren overweldigend. Er waren veel briljante ideeën en suggesties, met veel toepassingen die veel verder gingen dan deze specifieke uitdaging. Het deed me beseffen hoe geweldig het is om deel uit te maken van een gemeenschap, en dat geweldige dingen kunnen worden bereikt wanneer een groep slimme mensen de handen in elkaar slaat. Bedankt Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason en John Number2 voor het delen van uw ideeën en opmerkingen.
Aanvankelijk dacht ik eraan om slechts één artikel te schrijven om de ideeën samen te vatten die mensen hadden ingediend, maar het waren er te veel. Dus ik zal de dekking opsplitsen in verschillende artikelen. Deze maand zal ik me vooral concentreren op de door Charlie en Alan Burstein voorgestelde verbeteringen aan de twee originele oplossingen die ik vorige maand heb gepost in de vorm van de inline TVF's genaamd dbo.GetNumsItzikBatch en dbo.GetNumsItzik. Ik noem de verbeterde versies respectievelijk dbo.GetNumsAlanCharlieItzikBatch en dbo.GetNumsAlanCharlieItzik.
Dit is zo spannend!
Itzik's originele oplossingen
Ter herinnering:de functies die ik vorige maand heb behandeld, gebruiken een basis-CTE die een tabelwaardeconstructor met 16 rijen definieert. De functies gebruiken een reeks trapsgewijze CTE's, waarbij elk een product (cross join) van twee instanties van de voorgaande CTE toepast. Op deze manier kunt u, met vijf CTE's voorbij de basis, een set van maximaal 4.294.967.296 rijen krijgen. Een CTE met de naam Nums gebruikt de functie ROW_NUMBER om een reeks getallen te produceren die begint met 1. Ten slotte berekent de buitenste query de getallen in het gevraagde bereik tussen de invoer @low en @high.
De functie dbo.GetNumsItzikBatch gebruikt een dummy-join naar een tabel met een columnstore-index om batchverwerking op te halen. Hier is de code om de dummy-tabel te maken:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
En hier is de code die de functie dbo.GetNumsItzikBatch definieert:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Ik heb de volgende code gebruikt om de functie te testen met "Resultaten negeren na uitvoering" ingeschakeld in SSMS:
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Dit zijn de prestatiestatistieken die ik voor deze uitvoering heb gekregen:
CPU time = 16985 ms, elapsed time = 18348 ms.
De functie dbo.GetNumsItzik is vergelijkbaar, alleen heeft deze geen dummy-join en wordt normaal gesproken in de rijmodus verwerkt door het hele plan. Dit is de definitie van de functie:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Dit is de code die ik heb gebruikt om de functie te testen:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Dit zijn de prestatiestatistieken die ik voor deze uitvoering heb gekregen:
CPU time = 19969 ms, elapsed time = 21229 ms.
De verbeteringen van Alan Burstein en Charlie
Alan en Charlie stelden verschillende verbeteringen aan mijn functies voor, sommige met matige gevolgen voor de prestaties en sommige met meer dramatische. Ik zal beginnen met Charlie's bevindingen met betrekking tot compilatie-overhead en constant vouwen. Ik zal dan de suggesties van Alan behandelen, waaronder 1-gebaseerde versus @low-gebaseerde reeksen (ook gedeeld door Charlie en Jeff Moden), onnodige sortering vermijden en een getallenreeks in tegenovergestelde volgorde berekenen.
Bevindingen compilatietijd
Zoals Charlie opmerkte, wordt een nummerreeksgenerator vaak gebruikt om reeksen met zeer kleine aantallen rijen te genereren. In die gevallen kan de compileertijd van de code een substantieel deel van de totale queryverwerkingstijd gaan uitmaken. Dat is vooral belangrijk bij het gebruik van iTVF's, omdat het, in tegenstelling tot opgeslagen procedures, niet de geparametreerde querycode is die wordt geoptimaliseerd, maar de querycode nadat de parameterinsluiting heeft plaatsgevonden. Met andere woorden, de parameters worden vóór optimalisatie vervangen door de invoerwaarden en de code met de constanten wordt geoptimaliseerd. Dit proces kan zowel negatieve als positieve gevolgen hebben. Een van de negatieve implicaties is dat u meer compilaties krijgt omdat de functie wordt aangeroepen met verschillende invoerwaarden. Om deze reden moet zeker rekening worden gehouden met compileertijden, vooral wanneer de functie zeer vaak wordt gebruikt met kleine bereiken.
Hier zijn de compilatietijden die Charlie heeft gevonden voor de verschillende basis CTE-kardinaliteiten:
2: 22ms 4: 9ms 16: 7ms 256: 35ms
Het is merkwaardig om te zien dat onder deze 16 het optimale is, en dat er een zeer dramatische sprong is wanneer je naar het volgende niveau gaat, dat 256 is. Bedenk dat de functies dbo.GetNumsItzikBacth en dbo.GetNumsItzik basis CTE-kardinaliteit van 16 gebruiken .
Constant vouwen
Constant vouwen is vaak een positieve implicatie dat onder de juiste omstandigheden mogelijk wordt gemaakt dankzij het parameterinbeddingsproces dat een iTVF ervaart. Stel bijvoorbeeld dat uw functie een uitdrukking heeft @x + 1, waarbij @x een invoerparameter van de functie is. Je roept de functie aan met @x =5 als invoer. De inline-uitdrukking wordt dan 5 + 1, en als deze in aanmerking komt voor constant vouwen (hierover binnenkort meer), wordt dan 6. Als deze uitdrukking deel uitmaakt van een meer uitgebreide uitdrukking met kolommen en wordt toegepast op vele miljoenen rijen, kan dit resulteren in niet te verwaarlozen besparingen in CPU-cycli.
Het lastige is dat SQL Server erg kieskeurig is over wat constant moet worden gevouwen en wat niet. SQL Server zal bijvoorbeeld niet constant fold col1 + 5 + 1, noch zal het 5 + col1 + 1 vouwen. Maar het zal 5 + 1 + col1 tot 6 + col1 vouwen. Ik weet. Als uw functie bijvoorbeeld SELECT @x + col1 + 1 AS mycol1 FROM dbo.T1 retourneert, kunt u constant vouwen inschakelen met de volgende kleine wijziging:SELECT @x + 1 + col1 AS mycol1 FROM dbo.T1. Geloof me niet? Bekijk de plannen voor de volgende drie zoekopdrachten in de PerformanceV5-database (of vergelijkbare zoekopdrachten met uw gegevens) en overtuig uzelf:
SELECT orderid + 5 + 1 AS myorderid FROM dbo.orders; SELECT 5 + orderid + 1 AS myorderid FROM dbo.orders; SELECT 5 + 1 + orderid AS myorderid FROM dbo.orders;
Ik heb de volgende drie uitdrukkingen in de Compute Scalar-operators voor respectievelijk deze drie query's:
[Expr1003] = Scalar Operator([PerformanceV5].[dbo].[Orders].[orderid]+(5)+(1)) [Expr1003] = Scalar Operator((5)+[PerformanceV5].[dbo].[Orders].[orderid]+(1)) [Expr1003] = Scalar Operator((6)+[PerformanceV5].[dbo].[Orders].[orderid])
Zie je waar ik hiermee naartoe ga? In mijn functies heb ik de volgende uitdrukking gebruikt om de resultaatkolom n te definiëren:
@low + rownum - 1 AS n
Charlie realiseerde zich dat hij met de volgende kleine wijziging constant kan vouwen:
@low - 1 + rownum AS n
Bijvoorbeeld, het plan voor de eerdere query die ik opleverde tegen dbo.GetNumsItzik, met @low =1, had oorspronkelijk de volgende expressie gedefinieerd door de Compute Scalar-operator:
[Expr1154] = Scalar Operator((1)+[Expr1153]-(1))
Na het toepassen van de bovenstaande kleine wijziging, wordt de uitdrukking in het plan:
[Expr1154] = Scalar Operator((0)+[Expr1153])
Dat is briljant!
Wat betreft de prestatie-implicaties, onthoud dat de prestatiestatistieken die ik voor de query tegen dbo.GetNumsItzikBatch vóór de wijziging kreeg de volgende waren:
CPU time = 16985 ms, elapsed time = 18348 ms.
Dit zijn de nummers die ik kreeg na de wijziging:
CPU time = 16375 ms, elapsed time = 17932 ms.
Hier zijn de nummers die ik heb gekregen voor de zoekopdracht tegen dbo.GetNumsItzik oorspronkelijk:
CPU time = 19969 ms, elapsed time = 21229 ms.
En hier zijn de cijfers na de wijziging:
CPU time = 19266 ms, elapsed time = 20588 ms.
De prestaties verbeterden slechts een beetje met een paar procent. Maar wacht, er is meer! Als u de bestelde gegevens moet verwerken, kunnen de gevolgen voor de prestaties veel dramatischer zijn, zoals ik later in het gedeelte over bestellen zal bespreken.
1-gebaseerde versus @low-gebaseerde reeks en tegenoverliggende rijnummers
Alan, Charlie en Jeff merkten op dat in de overgrote meerderheid van de echte gevallen waarin je een reeks getallen nodig hebt, je het moet beginnen met 1 of soms met 0. Het is veel minder gebruikelijk om een ander beginpunt nodig te hebben. Het kan dus logischer zijn om de functie altijd een bereik te laten retourneren dat begint met bijvoorbeeld 1, en wanneer u een ander startpunt nodig heeft, past u eventuele berekeningen extern in de query toe op de functie.
Alan kwam eigenlijk met een elegant idee om de inline TVF zowel een kolom te laten retourneren die begint met 1 (eenvoudig het directe resultaat van de ROW_NUMBER-functie) als rn, als een kolom die begint met @low met een alias als n. Omdat de functie inline wordt en de buitenste query alleen interactie heeft met de kolom rn, wordt de kolom n niet eens geëvalueerd en krijgt u het prestatievoordeel. Als u de reeks nodig heeft om met @low te beginnen, werkt u met de kolom n en betaalt u de toepasselijke extra kosten, dus het is niet nodig om expliciete externe berekeningen toe te voegen. Alan stelde zelfs voor om een kolom met de naam op toe te voegen die de getallen in tegengestelde volgorde berekent, en er alleen interactie mee heeft als een dergelijke reeks nodig is. De kolom op is gebaseerd op de berekening:@high + 1 – rownum. Deze kolom is van belang wanneer u de rijen in aflopende nummervolgorde moet verwerken, zoals ik later in het bestelgedeelte laat zien.
Laten we dus de verbeteringen van Charlie en Alan toepassen op mijn functies.
Zorg ervoor dat u voor de batchmodusversie eerst de dummytabel maakt met de columnstore-index, als deze nog niet aanwezig is:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Gebruik dan de volgende definitie voor de functie dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Hier is een voorbeeld voor het gebruik van de functie:
SELECT * FROM dbo.GetNumsAlanCharlieItzikBatch(-2, 3) AS F ORDER BY rn;
Deze code genereert de volgende uitvoer:
rn op n --- --- --- 1 3 -2 2 2 -1 3 1 0 4 0 1 5 -1 2 6 -2 3
Test vervolgens de prestaties van de functie met 100 miljoen rijen, waarbij u eerst de kolom n retourneert:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Dit zijn de prestatiestatistieken die ik voor deze uitvoering heb gekregen:
CPU time = 16375 ms, elapsed time = 17932 ms.
Zoals je kunt zien, is er een kleine verbetering vergeleken met dbo.GetNumsItzikBatch in zowel CPU als verstreken tijd dankzij het constante vouwen dat hier plaatsvond.
Test de functie, maar retourneer deze keer de kolom rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Dit zijn de prestatiestatistieken die ik voor deze uitvoering heb gekregen:
CPU time = 15890 ms, elapsed time = 18561 ms.
CPU-tijd verder verminderd, hoewel de verstreken tijd in deze uitvoering iets langer lijkt te zijn dan bij het opvragen van de kolom n.
Afbeelding 1 bevat de plannen voor beide zoekopdrachten.
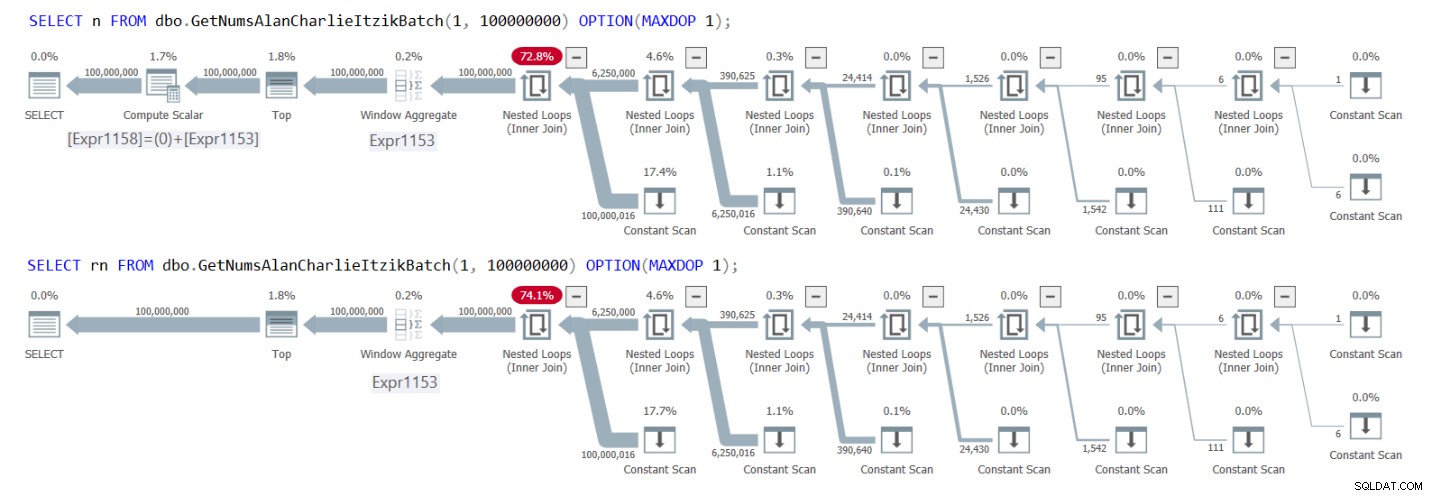 Figuur 1:Plannen voor GetNumsAlanCharlieItzikBatch die n versus rn retourneert
Figuur 1:Plannen voor GetNumsAlanCharlieItzikBatch die n versus rn retourneert
Je kunt duidelijk in de plannen zien dat bij interactie met de kolom rn de extra Compute Scalar-operator niet nodig is. Let ook op in het eerste plan wat de uitkomst is van de constante vouwactiviteit die ik eerder beschreef, waarbij @low – 1 + rownum werd ingelijnd met 1 – 1 + rownum en vervolgens werd gevouwen tot 0 + rownum.
Hier is de definitie van de rijmodusversie van de functie genaamd dbo.GetNumsAlanCharlieItzik:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzik(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum; Gebruik de volgende code om de functie te testen, waarbij u eerst de kolom n opvraagt:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Dit zijn de prestatiestatistieken die ik heb gekregen:
CPU time = 19047 ms, elapsed time = 20121 ms.
Zoals je kunt zien, is het iets sneller dan dbo.GetNumsItzik.
Zoek vervolgens in de kolom rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
De prestatiecijfers verbeteren verder op zowel de CPU als de verstreken tijdfronten:
CPU time = 17656 ms, elapsed time = 18990 ms.
Overwegingen bij het bestellen
De bovengenoemde verbeteringen zijn zeker interessant, en de prestatie-impact is niet te verwaarlozen, maar niet erg significant. Een veel dramatischer en diepgaander effect op de prestaties kan worden waargenomen wanneer u de gegevens moet verwerken die zijn gerangschikt op de nummerkolom. Dit kan zo simpel zijn als het retourneren van de bestelde rijen, maar is net zo relevant voor elke ordergebaseerde verwerkingsbehoefte, bijvoorbeeld een Stream Aggregate-operator voor groepering en aggregatie, een Merge Join-algoritme voor samenvoeging, enzovoort.
Bij het opvragen van dbo.GetNumsItzikBatch of dbo.GetNumsItzik en bestellen op n, realiseert de optimizer zich niet dat de onderliggende ordeningsuitdrukking @low + rownum – 1 orderbehoudend is met betrekking tot rijnum. De implicatie is een beetje vergelijkbaar met die van een niet-SARGable filterexpressie, alleen met een orderexpressie resulteert dit in een expliciete Sort-operator in het plan. De extra sortering heeft invloed op de reactietijd. Het heeft ook invloed op de schaling, die doorgaans n log n wordt in plaats van n.
Om dit aan te tonen, voert u een query uit op dbo.GetNumsItzikBatch, waarbij u de kolom n opvraagt, geordend op n:
SELECT n FROM dbo.GetNumsItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Ik heb de volgende prestatiestatistieken:
CPU time = 34125 ms, elapsed time = 39656 ms.
De looptijd is meer dan verdubbeld in vergelijking met de test zonder de ORDER BY-clausule.
Test de dbo.GetNumsItzik-functie op een vergelijkbare manier:
SELECT n FROM dbo.GetNumsItzik(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Ik heb de volgende cijfers voor deze test:
CPU time = 52391 ms, elapsed time = 55175 ms.
Ook hier wordt de looptijd meer dan verdubbeld vergeleken met de test zonder de ORDER BY-clausule.
Afbeelding 2 bevat de plannen voor beide zoekopdrachten.
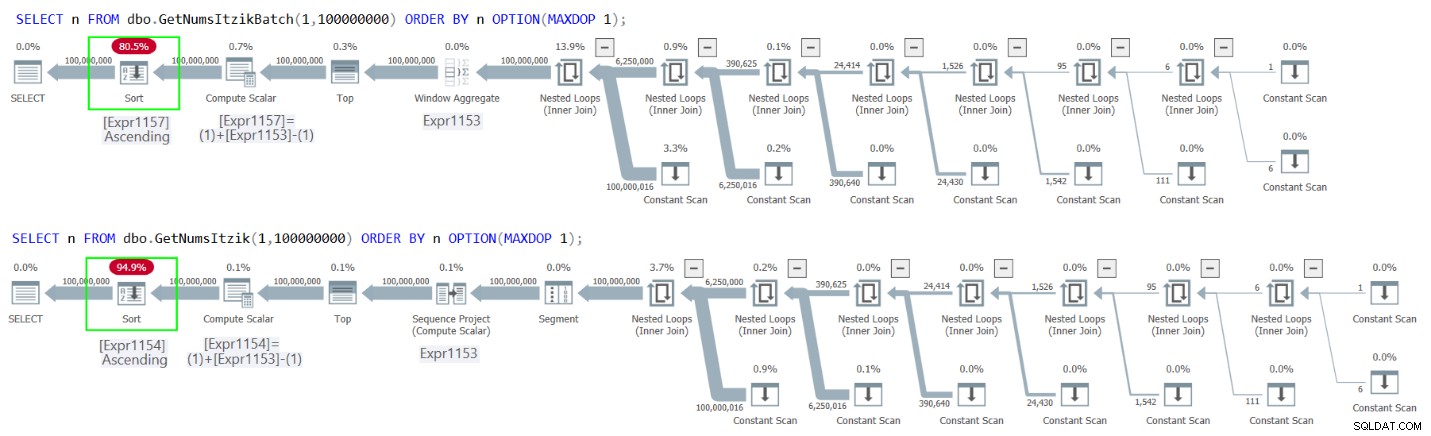 Figuur 2:Plannen voor GetNumsItzikBatch en GetNumsItzik bestellen per n
Figuur 2:Plannen voor GetNumsItzikBatch en GetNumsItzik bestellen per n
In beide gevallen zie je de expliciete Sort-operator in de plannen.
Bij het opvragen van dbo.GetNumsAlanCharlieItzikBatch of dbo.GetNumsAlanCharlieItzik en bestellen op rn hoeft de optimizer geen sorteeroperator aan het plan toe te voegen. Dus je zou n kunnen retourneren, maar sorteer op rn, en op deze manier vermijd je een sortering. Wat echter een beetje schokkend is - en ik bedoel het op een goede manier - is dat de herziene versie van n, die constant wordt gevouwen, de orde behoudt! Het is gemakkelijk voor de optimizer om te beseffen dat 0 + rownum een uitdrukking is die de volgorde behoudt met betrekking tot rownum, en zo een sortering vermijden.
Probeer het. Vraag dbo.GetNumsAlanCharlieItzikBatch, retourneer n en bestel door n of rn, zoals zo:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Ik heb de volgende prestatienummers:
CPU time = 16500 ms, elapsed time = 17684 ms.
Dat is natuurlijk te danken aan het feit dat er geen sorteeroperator nodig was in het plan.
Voer een vergelijkbare test uit tegen dbo.GetNumsAlanCharlieItzik:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Ik heb de volgende nummers:
CPU time = 19546 ms, elapsed time = 20803 ms.
Afbeelding 3 bevat de plannen voor beide zoekopdrachten:
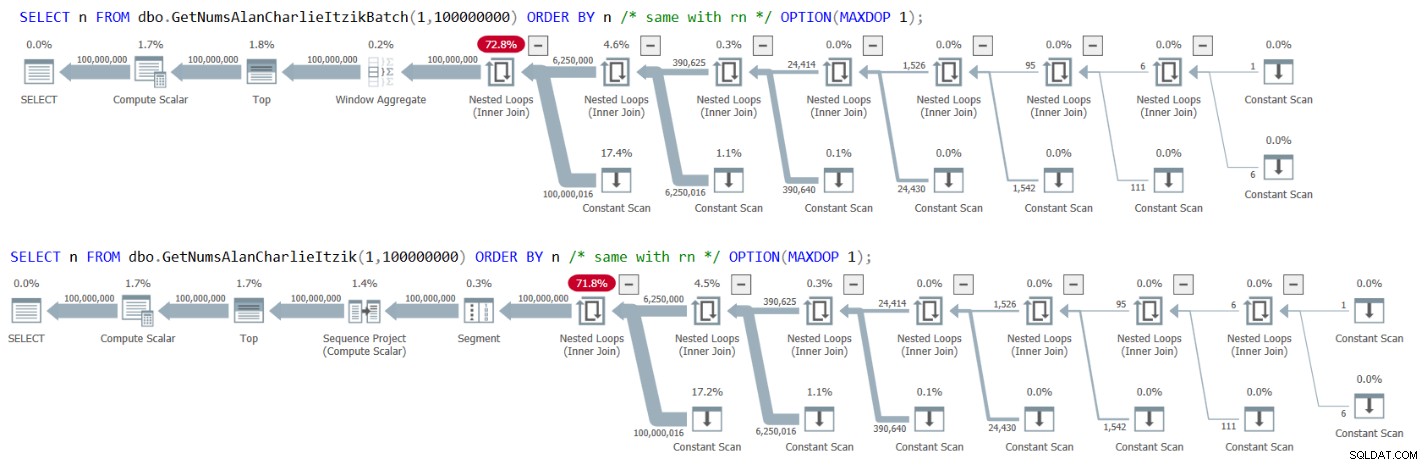
Figuur 3:Plannen voor GetNumsAlanCharlieItzikBatch en GetNumsAlanCharlieItzik bestellen op n of rn
Merk op dat er geen sorteeroperator in de plannen is.
Je wilt zingen...
All you need is constant folding All you need is constant folding All you need is constant folding, constant folding Constant folding is all you need
Bedankt Charlie!
Maar wat als u de nummers in aflopende volgorde moet retourneren of verwerken? De voor de hand liggende poging is om ORDER BY n DESC of ORDER BY rn DESC te gebruiken, zoals:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n DESC OPTION(MAXDOP 1); SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY rn DESC OPTION(MAXDOP 1);
Helaas resulteren beide gevallen echter in een expliciete sortering in de plannen, zoals weergegeven in figuur 4.
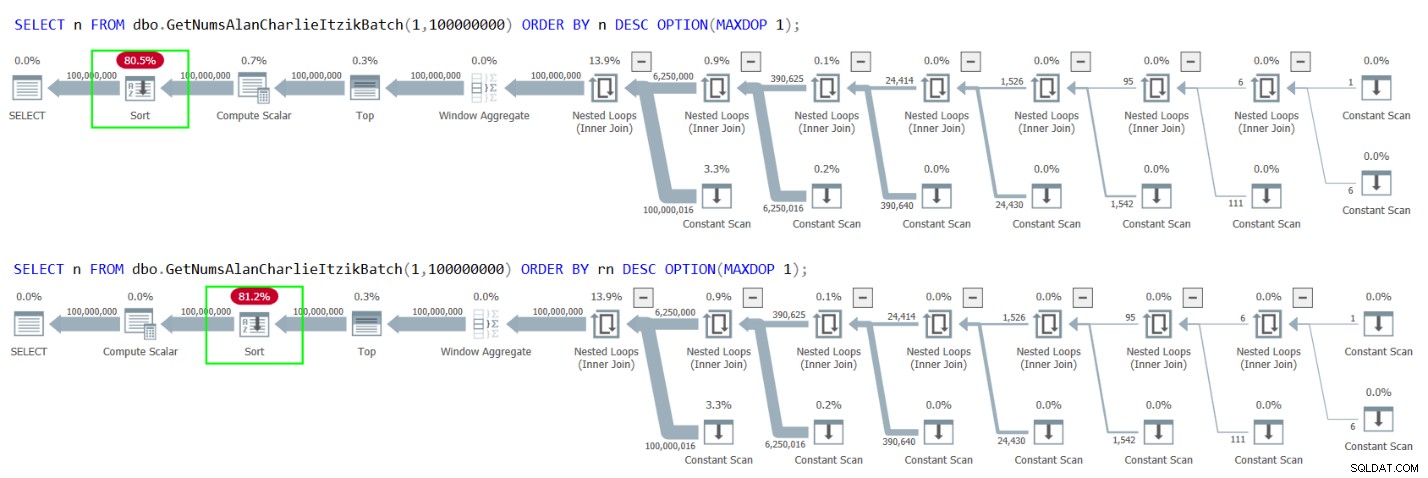 Figuur 4:Plannen voor GetNumsAlanCharlieItzikBatch bestellen op n of rn aflopend
Figuur 4:Plannen voor GetNumsAlanCharlieItzikBatch bestellen op n of rn aflopend
Dit is waar Alan's slimme truc met de column op een redder in nood wordt. Retourneer de kolom op terwijl u bestelt met n of rn, zoals zo:
SELECT op FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Het plan voor deze zoekopdracht wordt getoond in figuur 5.
 Figuur 5:Plan voor GetNumsAlanCharlieItzikBatch retourneren op en bestellen met n of rn oplopend
Figuur 5:Plan voor GetNumsAlanCharlieItzikBatch retourneren op en bestellen met n of rn oplopend
U krijgt de gegevens terug gesorteerd door n aflopend en er is geen sortering in het plan nodig.
Bedankt Alan!
Prestatiesamenvatting
Dus wat hebben we hiervan geleerd?
Compilatietijden kunnen een factor zijn, vooral wanneer de functie vaak met kleine bereiken wordt gebruikt. Op een logaritmische schaal met grondtal 2 lijkt sweet 16 een mooi magisch getal te zijn.
Begrijp de eigenaardigheden van constant vouwen en gebruik ze in uw voordeel. Als een iTVF uitdrukkingen heeft die parameters, constanten en kolommen bevatten, plaatst u de parameters en constanten in het begingedeelte van de uitdrukking. Dit vergroot de kans op folden, vermindert de CPU-overhead en vergroot de kans op orderbehoud.
Het is prima om meerdere kolommen te hebben die voor verschillende doeleinden in een iTVF worden gebruikt, en in elk geval de relevante te doorzoeken zonder dat u zich zorgen hoeft te maken over het betalen voor de kolommen waarnaar niet wordt verwezen.
Als u de getallenreeks in tegenovergestelde volgorde wilt retourneren, gebruikt u de oorspronkelijke kolom n of rn in de ORDER BY-component met oplopende volgorde en retourneert u de kolom op, die de getallen in omgekeerde volgorde berekent.
Afbeelding 6 vat de prestatiecijfers samen die ik in de verschillende tests heb gekregen.
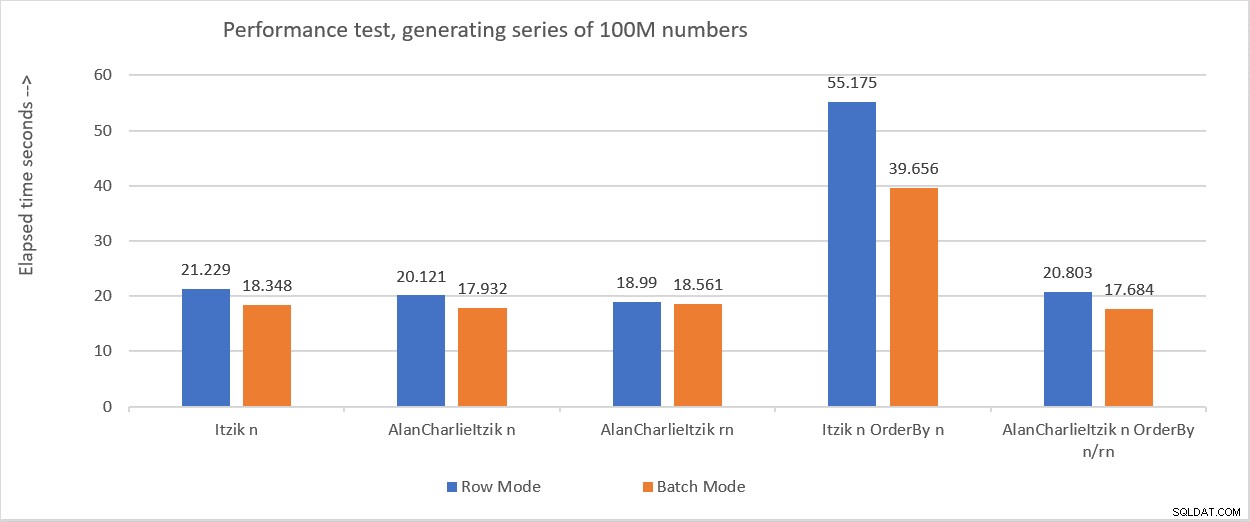 Figuur 6:Prestatiesamenvatting
Figuur 6:Prestatiesamenvatting
Volgende maand ga ik verder met het verkennen van aanvullende ideeën, inzichten en oplossingen voor de uitdaging van het genereren van getallenreeksen.