In deze Hadoop tutorial , gaan we u een volledige introductie geven tot MapReduce Key Value Pair.
Allereerst zullen we bespreken wat een sleutelwaardepaar is in Hadoop, hoe een sleutelwaardepaar wordt gegenereerd in MapReduce. Ten slotte zullen we het genereren van MapReduce-sleutelwaardeparen uitleggen met voorbeelden.
Wat is een sleutelwaardepaar in Hadoop?
Sleutel-waardepaar in MapReduce is de recordentiteit die Hadoop MapReduce accepteert voor uitvoering.
We gebruiken Hadoop voornamelijk voor data-analyse. Het gaat over gestructureerde, ongestructureerde en semi-gestructureerde data. Met Hadoop kunnen we, als het schema statisch is, direct aan de kolom werken in plaats van aan de sleutelwaarde. Maar als het schema niet statisch is, werken we aan een sleutelwaarde.
De waarde van sleutels is niet de intrinsieke eigenschappen van de gegevens. Maar ze worden gekozen door de gebruiker die de gegevens analyseert.
MapReduce is het kernonderdeel van Hadoop, dat zorgt voor gegevensverwerking. Het voert de verwerking uit door de taak in twee fasen te splitsen:Kaartfase en Verminder fase . Elke fase heeft een sleutelwaarde als invoer en uitvoer.
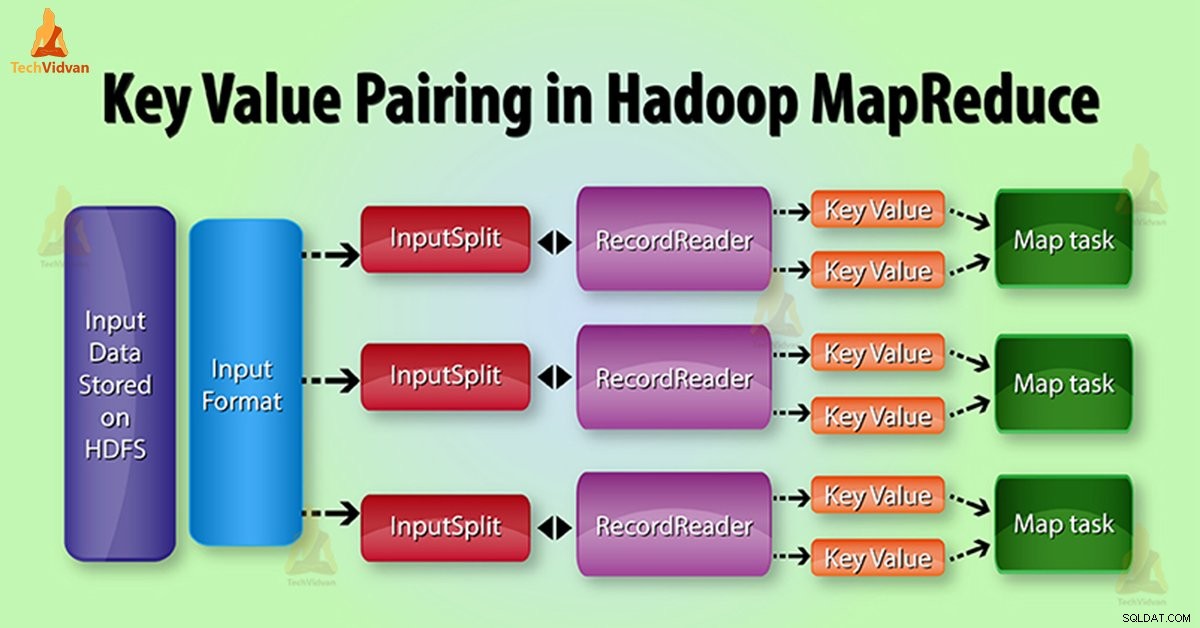
MapReduce Generatie sleutelwaardepaar in Hadoop
In MapReduce-taakuitvoering, voordat gegevens naar de mapper worden verzonden , zet deze eerst om in sleutel-waardeparen. Omdat mapper alleen sleutel-waardeparen van gegevens toewijst.
Sleutel-waardepaar in MapReduce wordt als volgt gegenereerd:
InputSplit – Het is de logische weergave van gegevens die InputFormat genereert. In het MapReduce-programma beschrijft het een werkeenheid die een enkele kaarttaak bevat.
RecordReader – Het communiceert met de InputSplit. Daarna zet het de gegevens om in sleutelwaardeparen die geschikt zijn om door de Mapper te worden gelezen. RecordReader gebruikt standaard TextInputFormat om gegevens om te zetten in sleutelwaardeparen.
In MapReduce-taakuitvoering verwerkt de kaartfunctie een bepaald sleutel-waardepaar. Zendt vervolgens een bepaald aantal sleutel-waardeparen uit. De functie Verminderen verwerkt de waarden die op dezelfde toets zijn gegroepeerd.
Zendt vervolgens een andere set sleutel-waardeparen uit als uitvoer. De kaartuitvoertypen moeten overeenkomen met de invoertypen van de Vermindering, zoals hieronder weergegeven:
- Kaart: (K1, V1) -> lijst (K2, V2)
- Verminderen: {(K2, lijst (V2}) -> lijst (K3, V3)
Op welke basis wordt een sleutel-waardepaar gegenereerd in Hadoop?
MapReduce Het genereren van sleutel-waardeparen is volledig afhankelijk van de dataset. Hangt ook af van de gewenste output. Framework specificeert sleutel/waarde-paar op 4 plaatsen:Invoer/uitvoer in kaart brengen, invoer/uitvoer verminderen.
1. Kaartinvoer
Kaartinvoer neemt standaard de lijnoffset als sleutel. De inhoud van de regel is waarde als Tekst. We kunnen ze aanpassen; door het aangepaste invoerformaat te gebruiken.
2. Kaartuitvoer
De kaart is verantwoordelijk voor het filteren van de gegevens. Het biedt ook de omgeving om de gegevens te groeperen op basis van sleutel.
- Sleutel– Het is een veld/tekst/object waarop de gegevens worden gegroepeerd en geaggregeerd op de reducer .
- Waarde– Het is het veld/tekst/object dat elk individu de handvatten van de methode reduceert.
3. Invoer verminderen
Kaartuitvoer wordt ingevoerd om te verminderen. Het is dus hetzelfde als Map-Output.
4. Uitvoer verminderen
Het hangt helemaal af van de vereiste output.
MapReduce Sleutel-waardepaar Voorbeeld
Bijvoorbeeld de inhoud van het bestand dat HDFS winkels zijn Chandler is Joey Mark is John . Dus, door InputFormat te gebruiken, zullen we definiëren hoe dit bestand wordt gesplitst en gelezen. Standaard gebruikt RecordReader TextInputFormat om dit bestand om te zetten in een sleutel-waardepaar.
- Sleutel – Het is verschoven ten opzichte van het begin van de regel in het bestand.
- Waarde – Het is de inhoud van de lijn, exclusief lijnafsluitingen.
Hier, sleutel is 0 en Waarde is Chandler is Joey Mark is John.
Conclusie
Concluderend kunnen we zeggen dat sleutelwaarde slechts een recordentiteit is die MapReduce accepteert voor uitvoering. InputSplit en RecordReader genereren een sleutel-waardepaar. Daarom is de sleutel byte-offset en waarde is de inhoud van de regel.
Ik hoop dat je deze blog leuk vond. Als je een suggestie of vraag hebt met betrekking tot het MapReduce-sleutelwaardepaar, laat dan een reactie achter in een sectie hieronder.