Dit is deel 2 van deze blogreeks. Je kunt deel 1 hier lezen: Digitale transformatie is een datareis van edge naar Insight
Deze blogreeks volgt de productie-, operatie- en verkoopgegevens voor een fabrikant van verbonden voertuigen terwijl de gegevens stadia en transformaties doorlopen die typisch zijn voor een groot productiebedrijf met de voorhoede van de huidige technologie. De eerste blog introduceerde een namaakbedrijf voor de productie van verbonden voertuigen, The Electric Car Company (ECC), om het pad van productiegegevens door de gegevenslevenscyclus te illustreren. Om dit te bereiken maakt ECC gebruik van het Cloudera Data Platform (CDP) om gebeurtenissen te voorspellen en een top-down beeld te krijgen van het fabricageproces van de auto in zijn fabrieken over de hele wereld.
Na de stap Gegevensverzameling in de vorige blog te hebben voltooid, is de volgende stap van ECC in de gegevenslevenscyclus Gegevensverrijking. ECC zal de verzamelde gegevens verrijken en beschikbaar stellen voor gebruik bij analyse en modelcreatie later in de levenscyclus van gegevens. Hieronder vindt u de volledige reeks stappen in de gegevenslevenscyclus, en elke stap in de levenscyclus wordt ondersteund door een speciale blogpost (zie Afb. 1):
- Gegevensverzameling – gegevensopname en monitoring aan de rand (of de rand nu industriële sensoren zijn of mensen in een voertuigshowroom)
- Gegevensverrijking - verwerking, aggregatie en beheer van gegevenspijplijnen om de gegevens klaar te maken voor verdere analyse
- Rapportage – het leveren van zakelijk inzicht (verkoopanalyse en prognoses, budgettering als voorbeelden)
- Bedienen – controle en uitvoering van essentiële bedrijfsactiviteiten (dealeractiviteiten, productiebewaking)
- Voorspellende analyses – voorspellende analyses op basis van AI en machine learning (voorspellend onderhoud, vraaggebaseerde voorraadoptimalisatie als voorbeelden)
- Beveiliging en bestuur – een geïntegreerde set van beveiligings-, beheer- en governancetechnologieën over de gehele levenscyclus van gegevens

Fig. 1 De levenscyclus van bedrijfsgegevens
Uitdaging voor gegevensverrijking
ECC heeft een uitgebreid overzicht en gedegen begrip nodig van alle gegevens met betrekking tot de productie, de dealeractiviteiten en verzending van hun voertuigen. Ze moeten ook snel problemen met de gegevens identificeren, zoals operationele sensoren die gegevens afspinnen, waaronder valse temperatuurpieken veroorzaakt door ongeplande machineonderbrekingen of abrupte start-ups. Gegevens die geen verband houden met het proces wanneer onderhoudsmedewerkers bijvoorbeeld een sensor uit een zuurdiptank verwijderen tijdens routine-inspecties, mogen bij de analyse niet in aanmerking worden genomen.
Bovendien wordt ECC geconfronteerd met de volgende gegevensuitdagingen die moeten worden aangepakt om de motorproductie met succes door de toeleveringsketen te verplaatsen. Deze gegevensuitdagingen omvatten de volgende:
- Gegevens ophalen in verschillende formaten uit verschillende bronnen: Data engineering-pijplijnen vereisen dat gegevens uit verschillende bronnen en in veel verschillende formaten worden aangevoerd. Of gegevens nu afkomstig zijn van sensoren die op de productielijn zitten en productieactiviteiten ondersteunen, of ERP-gegevens die de toeleveringsketen besturen, het moet allemaal worden samengebracht voor verdere analyse.
- Overtollige of irrelevante gegevens uitfilteren: Het verwijderen van dubbele of ongeldige gegevens en het verzekeren van de nauwkeurigheid van de resterende gegevens, is een belangrijke stap bij het voorbereiden van de gegevens voor verder gebruik in geavanceerde voorspellende analyses.
- Mogelijkheid om inefficiënte processen te identificeren: ECC vereist de mogelijkheid om te zien welke gegevensprocessen de meeste tijd en middelen in beslag nemen, waardoor het gemakkelijk is om slecht presterende delen van de pijplijn aan te pakken om het algehele proces te versnellen.
- Mogelijkheid om alle processen vanuit één paneel te bewaken: ECC heeft een gecentraliseerd systeem nodig waarmee ze alle lopende gegevensprocessen kunnen bewaken, evenals een manier om hun huidige infrastructuur uit te breiden met behoud van transparantie.
Samengestelde, hoogwaardige datasets vormen de ruggengraat van elk geavanceerd analyse-initiatief. Om dit te bereiken, moet een raamwerk voor data-engineering worden gebruikt om de bouw van alle leidingen en leidingen mogelijk te maken die nodig zijn om de gegevens van de verschillende voertuigonderdelen in de gegevenslevenscyclus te verplaatsen, manipuleren en beheren.
Een pijplijn bouwen met Cloudera Data Engineering
Voordat de gegevens worden verrijkt en besproken in de eerste blog, worden de IT- en OT-gegevensstromen die vanuit de fabriek zijn verzameld, opgeschoond, gemanipuleerd en aangepast. Fabrieks-ID, machine-ID, tijdstempel, onderdeelnummer en serienummer kunnen worden afgeleid uit een QR-code die op de elektromotor is afgedrukt. Terwijl de motor in het verbonden voertuig wordt gemonteerd, worden gegevens vastgelegd, zoals modeltype, VIN en basisvoertuigkosten.
Nadat het voertuig is verkocht, worden de verkoopinformatie zoals klantnaam, contactgegevens, uiteindelijke verkoopprijs en klantlocatie afzonderlijk geregistreerd. Deze gegevens zijn cruciaal om contact op te nemen met de klant voor eventuele terugroepacties of gericht preventief onderhoud. Er worden ook geolocatiegegevens opgeslagen, waardoor de locaties van klanten op lengte- en breedtegraden in kaart kunnen worden gebracht om beter te begrijpen waar deze motoren zich bevinden nadat ze in een voertuig zijn verkocht.
ECC zal Cloudera Data Engineering (CDE) gebruiken om de bovenstaande gegevensuitdagingen aan te pakken (zie Fig. 2). CDE stelt de gegevens vervolgens beschikbaar aan Cloudera Data Warehouse (CDW), waar ze beschikbaar worden gesteld voor geavanceerde analyses en business intelligence-rapporten. De CDE-stappen worden hieronder beschreven.
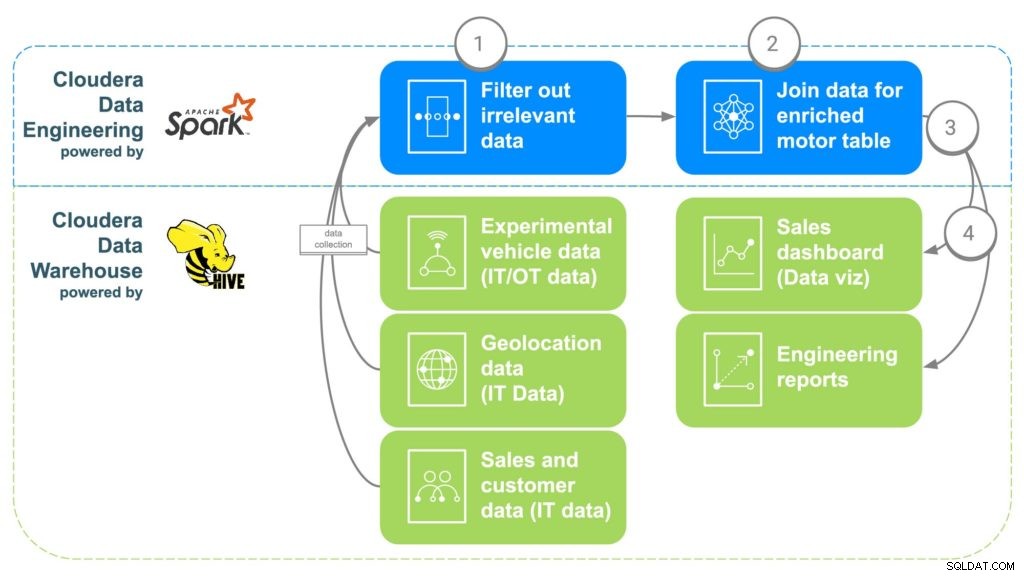
Fig. 2 ECC-gegevensverrijkingspijplijn
STAP 1:Filter en scheid de gegevens
De eerste stap bij het gebruik van CDE is het maken van een PySpark-taak die de gegevens uit deze verschillende "onbewerkte" bronnen uit stap 1 binnenhaalt. Dit is een mogelijkheid om irrelevante gegevens, zoals klanten onder de 16 jaar, te filteren, aangezien dat is meestal de minimumleeftijd om te rijden. Dubbele gegevens en andere irrelevante gegevens kunnen ook worden gefilterd of gescheiden.
STAP 2:Combineer de gegevens
Om alle gegevens te combineren, correleert CDE gemeenschappelijke links met elkaar. Ten eerste worden de autoverkoopgegevens gekoppeld aan de klant die de auto heeft gekocht om de metagegevens van de klant te krijgen, zoals contactgegevens, leeftijd, salaris, enz. Geolocatiegegevens worden vervolgens gebruikt om nauwkeurigere locatie-informatie voor de klant te krijgen , die later zal helpen bij het in kaart brengen van de motoren. De installatiegegevens van onderdelen worden gebruikt om de serienummers te identificeren voor elke motor die in de auto van de klant is geïnstalleerd. Ten slotte worden de fabrieksgegevens afgestemd op het serienummer van de motor, dat aangeeft welke fabriek, machine en wanneer elke specifieke motor is gemaakt.
STAP 3:Verstuur gegevens naar Cloudera Data Warehouse
Zodra alle gegevens zijn samengebracht in een verrijkte tabel, schrijft een eenvoudige Apache Spark-opdracht de gegevens naar een nieuwe tabel binnen Cloudera Data Warehouse. Dit maakt de gegevens toegankelijk voor alle gegevenswetenschappers die er toegang toe willen hebben om aanvullende analyses uit te voeren.
STAP 4:Genereer dashboards en rapporten voor gegevensvisualisatie
Met de gegevens allemaal op één plek, kunnen nu rapporten worden gemaakt waarmee werknemers beter geïnformeerde beslissingen kunnen nemen en mogelijkheden kunnen ontsluiten die nog niet bestonden. Heatmaps kunnen worden gemaakt om de locatie van de motor te volgen en eventuele problemen te correleren met potentiële geografische locaties, zoals storingen door extreme kou of hitte. Deze gegevens kunnen ook worden gebruikt om precies bij te houden welke klanten kunnen worden getroffen als er gedurende een bepaalde periode een probleem zou zijn in een bepaalde fabriek, waardoor het gemakkelijk wordt om klanten op te sporen die mogelijk een terugroepactie of preventief onderhoud nodig hebben.
Conclusie
Cloudera Data Engineering stelt ECC in staat een pijplijn te bouwen die productie- en onderdelengegevens, het type klantgebruik, omgevingsomstandigheden, verkoopinformatie en meer kan correleren om de klanttevredenheid en de betrouwbaarheid van het voertuig te verbeteren. ECC heeft zijn doelstellingen bereikt en hun uitdagingen aangepakt door de gegevens met betrekking tot de productie van zijn motoren bij te houden en op de volgende manieren te profiteren:
- ECC bracht tijd naar waarde door datapijplijnen te orkestreren en te automatiseren om gecureerde, hoogwaardige datasets veilig en transparant te leveren uit verschillende databronnen.
- ECC was in staat relevante gegevens te identificeren en overtollige en dubbele gegevens eruit te filteren.
- ECC was in staat om datapijplijnbewaking vanuit één enkel paneel te realiseren, terwijl het in een positie was om te worden gewaarschuwd om problemen vroegtijdig op te sporen door middel van visuele probleemoplossing om problemen snel op te lossen voordat het bedrijf er last van had.
Zoek naar de volgende blog die ingaat op Reporting, waarin wordt getoond hoe ECC-technici ad-hocquery's in CDW uitvoeren op basis van deze samengestelde gegevens en de gegevens koppelen aan andere relevante bronnen in een enterprise datawarehouse. CDW faciliteert het samenbrengen van alle gegevens en biedt een ingebouwde tool voor gegevensvisualisatie om van opgevraagde resultaten naar dashboards te gaan. Houd ons in de gaten voor de volgende!
Meer bronnen voor gegevensverzameling
Om dit alles in actie te zien, klikt u op de gerelateerde links hieronder voor meer informatie over gegevensverrijking:
- Video – Als je wilt zien en horen hoe dit is gebouwd, bekijk dan de video via de link.
- Tutorials – Als je dit in je eigen tempo wilt doen, bekijk dan een gedetailleerd overzicht met screenshots en regel voor regel instructies over hoe je dit kunt instellen en uitvoeren.
- Meetup – Als je rechtstreeks met experts van Cloudera wilt praten, neem dan deel aan een virtuele meetup om een livestreampresentatie te zien. Aan het einde is er tijd voor directe Q&A.
- Gebruikers – Klik op de link om meer technische inhoud te zien die specifiek is voor gebruikers.