MongoDB is een NoSQL-database die een breed scala aan invoergegevenssetbronnen ondersteunt. Het kan gegevens opslaan in flexibele JSON-achtige documenten, wat betekent dat velden of metagegevens van document tot document kunnen verschillen en dat de gegevensstructuur in de loop van de tijd kan worden gewijzigd. Het documentmodel maakt het gemakkelijk om met de gegevens te werken door deze toe te wijzen aan de objecten in de applicatiecode. MongoDB staat in de kern ook bekend als een gedistribueerde database, dus hoge beschikbaarheid, horizontale schaling en geografische distributie zijn ingebouwd en gemakkelijk te gebruiken. Het wordt geleverd met de mogelijkheid om parameters voor modeltraining naadloos aan te passen. Data Scientists kunnen de structurering van data eenvoudig samenvoegen met deze modelgeneratie.
Wat is machine learning?
Machine learning is de wetenschap die ervoor zorgt dat computers leren en handelen zoals mensen dat doen en hun leren in de loop van de tijd op autonome wijze verbetert. Het leerproces begint met observaties of gegevens, zoals voorbeelden, directe ervaring of instructie, om patronen in gegevens te zoeken en in de toekomst betere beslissingen te nemen op basis van de voorbeelden die we bieden. Het primaire doel is om de computers automatisch te laten leren zonder menselijke tussenkomst of hulp en acties dienovereenkomstig aan te passen.
Een uitgebreid programmeer- en querymodel
MongoDB biedt zowel native drivers als gecertificeerde connectoren voor ontwikkelaars en datawetenschappers die machine learning-modellen bouwen met gegevens van MongoDB. PyMongo is een geweldige bibliotheek om MongoDB-syntaxis in Python-code in te sluiten. We kunnen alle functies en methoden van MongoDB importeren om ze in onze machine learning-code te gebruiken. Het is een geweldige techniek om meertalige functionaliteit in één code te krijgen. Het extra voordeel is dat u de essentiële functies van die programmeertalen kunt gebruiken om een efficiënte applicatie te maken.
De MongoDB-querytaal met rijke secundaire indexen stelt ontwikkelaars in staat applicaties te bouwen die de gegevens in meerdere dimensies kunnen opvragen en analyseren. Gegevens zijn toegankelijk via enkele sleutels, bereiken, tekstzoekopdrachten, grafieken en geospatiale zoekopdrachten via complexe aggregaties en MapReduce-taken, waarbij antwoorden in milliseconden worden geretourneerd.
Om gegevensverwerking in een gedistribueerd databasecluster parallel te laten verlopen, biedt MongoDB de aggregatiepijplijn en MapReduce. De MongoDB-aggregatiepijplijn is gemodelleerd volgens het concept van gegevensverwerkingspijplijnen. Documenten komen in een meerfasenpijplijn die de documenten omzet in een geaggregeerd resultaat met behulp van native bewerkingen die worden uitgevoerd binnen MongoDB. De meest elementaire pijplijnfasen bieden filters die werken als query's en documenttransformaties die de vorm van het uitvoerdocument wijzigen. Andere pijplijnbewerkingen bieden tools voor het groeperen en sorteren van documenten op specifieke velden, evenals tools voor het aggregeren van de inhoud van arrays, inclusief arrays van documenten. Bovendien kunnen pipseline-stadia operators gebruiken voor taken zoals het berekenen van het gemiddelde of de standaarddeviaties voor verzamelingen documenten en het manipuleren van tekenreeksen. MongoDB biedt ook native MapReduce-bewerkingen binnen de database, waarbij aangepaste JavaScript-functies worden gebruikt om de kaart uit te voeren en stadia te verkleinen.
Naast het native queryframework biedt MongoDB ook een hoogwaardige connector voor Apache Spark. De connector toont alle bibliotheken van Spark, inclusief Python, R, Scala en Java. MongoDB-gegevens worden gematerialiseerd als dataframes en datasets voor analyse met machine learning, grafieken, streaming en SQL-API's.
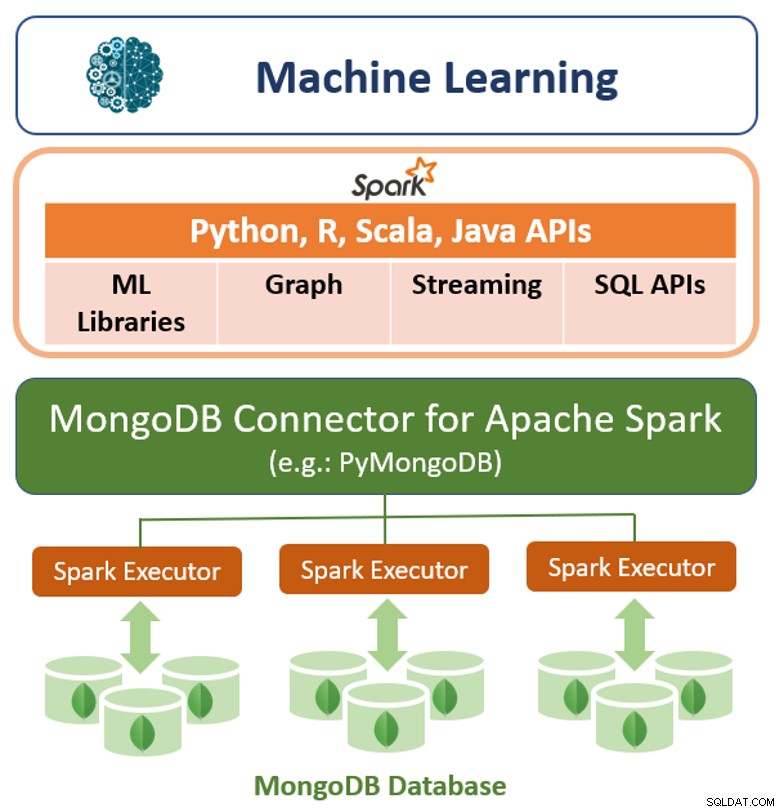
De MongoDB-connector voor Apache Spark kan profiteren van MongoDB's aggregatiepijplijn en secundaire indexen om alleen de reeks gegevens te extraheren, filteren en verwerken die het nodig heeft - bijvoorbeeld het analyseren van alle klanten in een specifieke regio. Dit is heel anders dan eenvoudige NoSQL-datastores die geen secundaire indexen of aggregaties in de database ondersteunen. In deze gevallen zou Spark alle gegevens moeten extraheren op basis van een eenvoudige primaire sleutel, zelfs als slechts een subset van die gegevens nodig is voor het Spark-proces. Dit betekent meer verwerkingsoverhead, meer hardware en een langere tijd tot inzicht voor datawetenschappers en technici. Om de prestaties van grote, gedistribueerde datasets te maximaliseren, kan de MongoDB-connector voor Apache Spark Resilient Distributed Datasets (RDD's) samen met het bron-MongoDB-knooppunt plaatsen, waardoor de gegevensverplaatsing over het cluster wordt geminimaliseerd en de latentie wordt verminderd.
Prestaties, schaalbaarheid en redundantie
De trainingstijd van het model kan worden verkort door het machine learning-platform te bouwen bovenop een performante en schaalbare databaselaag. MongoDB biedt een aantal innovaties om de doorvoer te maximaliseren en de latentie van machine learning-workloads te minimaliseren:
- WiredTiger staat bekend als de standaard opslagengine voor MongoDB, ontwikkeld door de architecten van Berkeley DB, de meest gebruikte embedded datamanagementsoftware ter wereld. WiredTiger schaalt op moderne, multi-core architecturen. Met behulp van een verscheidenheid aan programmeertechnieken zoals gevarenwijzers, lock-free algoritmen, snelle vergrendeling en het doorgeven van berichten, maximaliseert WiredTiger het rekenwerk per CPU-kern en klokcyclus. Om overhead en I/O op de schijf te minimaliseren, gebruikt WiredTiger compacte bestandsindelingen en opslagcompressie.
- Voor de meest latentiegevoelige machine learning-applicaties kan MongoDB worden geconfigureerd met de In-Memory storage-engine. Deze opslagengine is gebaseerd op WiredTiger en biedt gebruikers de voordelen van in-memory computing, zonder de rijke queryflexibiliteit, realtime analyse en schaalbare capaciteit van conventionele schijfgebaseerde databases in te leveren.
- Om modeltraining te parallelliseren en invoergegevenssets buiten een enkel knooppunt te schalen, gebruikt MongoDB een techniek genaamd sharding, die de verwerking en gegevens verdeelt over clusters van basishardware. MongoDB-sharding is volledig elastisch en herbalanceert automatisch gegevens over het cluster naarmate de invoergegevensset groeit of wanneer knooppunten worden toegevoegd en verwijderd.
- Binnen een MongoDB-cluster worden gegevens van elke shard automatisch gedistribueerd naar meerdere replica's die op afzonderlijke knooppunten worden gehost. MongoDB-replicasets bieden redundantie om trainingsgegevens te herstellen in het geval van een storing, waardoor de overhead van checkpointing wordt verminderd.
MongoDB's afstembare consistentie
MongoDB is standaard sterk consistent, waardoor machine learning-applicaties onmiddellijk kunnen lezen wat er in de database is geschreven, waardoor de ontwikkelaarscomplexiteit die wordt opgelegd door uiteindelijk consistente systemen wordt vermeden. Sterke consistentie levert de meest nauwkeurige resultaten op voor machine learning-algoritmen; in sommige scenario's is het echter acceptabel om consistentie te verruilen voor specifieke prestatiedoelen door query's te verdelen over een cluster van MongoDB secundaire replicasetleden.
Flexibel gegevensmodel in MongoDB
MongoDB's documentgegevensmodel maakt het gemakkelijk voor ontwikkelaars en gegevenswetenschappers om gegevens van elke vorm van structuur in de database op te slaan en te aggregeren, zonder geavanceerde validatieregels op te geven om de gegevenskwaliteit te regelen. Het schema kan dynamisch worden gewijzigd zonder uitvaltijd van een applicatie of database die het gevolg is van kostbare schemawijzigingen of herontwerp van relationele databasesystemen.
Het opslaan van modellen in een database en het laden ervan, met behulp van python, is ook een gemakkelijke en veelgevraagde methode. Kiezen voor MongoDB is ook een voordeel, omdat het een open-source documentdatabase is en ook een toonaangevende NoSQL-database. MongoDB dient ook als een connector voor apache spark gedistribueerd framework.
De dynamische aard van MongoDB
Het dynamische karakter van MongoDB maakt het gebruik ervan in databasemanipulatietaken bij het ontwikkelen van Machine Learning-applicaties mogelijk. Het is een zeer efficiënte en gemakkelijke manier om een analyse van datasets en databases uit te voeren. De output van de analyse kan worden gebruikt bij het trainen van machine learning-modellen. Het is aanbevolen dat data-analisten en machine learning-programmeurs de MongoDB onder de knie krijgen en in veel verschillende toepassingen toepassen. Het aggregatieraamwerk van MongoDB wordt gebruikt voor de datawetenschapsworkflow voor het uitvoeren van gegevensanalyse voor tal van toepassingen.
Conclusie
MongoDB biedt verschillende mogelijkheden, zoals:flexibel datamodel, uitgebreide programmering, datamodel, querymodel en de afstembare consistentie die training en het gebruik van machine learning-algoritmen veel gemakkelijker maken dan met traditionele, relationele databases. Door MongoDB als backend-database te gebruiken, kunnen machine learning-gegevens worden opgeslagen en verrijkt, wat zorgt voor persistentie en verhoogde efficiëntie.