Lees meer over de bijna realtime architectuur voor gegevensopname voor het transformeren en verrijken van gegevensstromen met behulp van Apache Flume, Apache Kafka en RocksDB in Santander UK.
Cloudera Professional Services heeft samengewerkt met Santander UK om een bijna realtime (NRT) transactieanalysesysteem op Apache Hadoop te bouwen. Het doel is om een transactie vast te leggen, te transformeren, te verrijken, te tellen en op te slaan binnen enkele seconden nadat een kaartaankoop heeft plaatsgevonden. Het systeem ontvangt de transacties van de retailklantenkaart van de bank en berekent de bijbehorende trendinformatie geaggregeerd per rekeninghouder en over een aantal dimensies en taxonomieën. Deze informatie wordt vervolgens veilig verzonden naar Santander's "Spendlytics"-app (zie hieronder) om klanten in staat te stellen hun laatste bestedingspatroon te analyseren.
Apache HBase werd gekozen als de onderliggende opslagoplossing vanwege de mogelijkheid om willekeurige schrijfbewerkingen met hoge doorvoer en willekeurige leesbewerkingen met lage latentie te ondersteunen. De NRT-vereiste sloot echter het uitvoeren van transformaties en verrijking van de transacties in batch uit, dus deze moeten worden gedaan terwijl de transacties naar HBase worden gestreamd. Dit omvat het transformeren van berichten van XML naar Avro en het verrijken ervan met trendgevoelige informatie, zoals merk- en handelsinformatie.
Dit bericht beschrijft hoe Santander Apache Flume, Apache Kafka en RocksDB gebruikt om transacties te transformeren, te verrijken en te streamen naar HBase. Dit is een implementatie van de NRT Event Processing with External Context streamingpatroon beschreven door Ted Malaska in dit bericht.
Flafka
De eerste beslissing die Santander moest nemen, was hoe gegevens het beste naar HBase konden worden gestreamd. Flume is bijna altijd de beste keuze voor het streamen van opname in Hadoop, gezien de eenvoud, betrouwbaarheid, rijke reeks bronnen en sinks en inherente schaalbaarheid.
Onlangs is een uitstekende integratie met Kafka toegevoegd, wat leidt tot de onvermijdelijke naam Fafka. Flume kan native gegarandeerde levering van evenementen bieden via zijn bestandskanaal, maar de mogelijkheid om evenementen opnieuw af te spelen en de extra flexibiliteit en toekomstbestendige Kafka die met zich meebrengt, waren de belangrijkste drijfveren voor de integratie.
In deze architectuur gebruikt Santander Kafka-kanalen om een betrouwbare, zelfbalancerende en schaalbare opnamebuffer te bieden waarin alle transformaties en verwerkingen worden weergegeven in geketende Kafka-onderwerpen. We maken met name uitgebreid gebruik van Flafka's source en sink, en Flume's vermogen om tijdens de vlucht verwerking uit te voeren met behulp van Interceptors. Dit voorkwam dat we onze eigen Kafka-producent en -consument moesten coderen, en stelde Santander in staat volledig te profiteren van Cloudera Manager om de agenten en makelaars te configureren, implementeren en controleren.
Transformatie
Transacties die door de kernbanksystemen worden vastgelegd, worden als XML-berichten aan Flume geleverd, nadat ze uit de brondatabase zijn gelezen via logreplicatie. (Het op deze manier afstemmen van een databaselog op Kafka-onderwerpen is een steeds vaker voorkomend patroon en in combinatie met logverdichting kan dit een "meest recente weergave" van de database opleveren voor gebruiksscenario's voor het vastleggen van wijzigingsgegevens.)
Flume slaat deze XML-berichten op in een "onbewerkt" Kafka-onderwerp. Vanaf hier, en als een voorloper van alle andere verwerkingen, werd besloten om de semi-gestructureerde XML om te zetten in gestructureerde binaire records om gestandaardiseerde downstream-verwerking te vergemakkelijken. Deze verwerking wordt uitgevoerd door een aangepaste Flume Interceptor die de XML-berichten omzet in een generieke Avro-representatie, waarbij specifieke typen worden toegepast waar van toepassing en terugvallen op een string-representatie waar dat niet het geval is. Alle daaropvolgende NRT-verwerking slaat vervolgens afgeleide resultaten op in Avro in speciale Kafka-onderwerpen, waardoor het gemakkelijk is om gebruik te maken van de stream en op elk punt in de verwerkingsketen een gebeurtenisfeed te krijgen.
Als complexere gebeurtenisverwerking vereist zou zijn, bijvoorbeeld aggregaties met Spark Streaming, zou het een triviale zaak zijn om een of meer van deze onderwerpen te gebruiken en te publiceren naar nieuwe afgeleide onderwerpen. (Apache Avro is een natuurlijke keuze voor dit formaat:het is een compact binair protocol dat schema-evolutie ondersteunt, heeft een flexibele schemadefinitie en wordt ondersteund door de hele Hadoop-stack. Avro wordt snel een de facto standaard voor tussentijdse en algemene gegevensopslag in een enterprise data hub en is perfect geplaatst voor transformatie naar Apache Parquet voor analytische workloads.)
Verrijking
De inspiratie voor het ontwerp van de streamingverrijkingsoplossing kwam van een O'Reilly Radar-bericht geschreven door Jay Kreps. In zijn post beschrijft Jay de voordelen van het gebruik van een lokale winkel om een streamprocessor in staat te stellen een lokale status op te vragen of te wijzigen als reactie op de invoer, in plaats van op afstand te bellen naar een gedistribueerde database.
Bij Santander hebben we dit patroon aangepast om lokale referentiewinkels te bieden die worden gebruikt om transacties op te vragen en te verrijken terwijl ze door Flume worden gestreamd. Waarom gebruik je HBase niet gewoon als de referentiewinkel? Welnu, een typisch patroon voor dit soort problemen is om de status eenvoudig in HBase op te slaan en het verrijkingsmechanisme er rechtstreeks naar te laten vragen. We hebben om een aantal redenen van deze aanpak afgezien. Ten eerste zijn de referentiegegevens relatief klein en zouden ze in een enkele HBase-regio passen, wat waarschijnlijk een regio-hotspot veroorzaakt. Ten tweede bedient HBase de klantgerichte Spendlytics-app en Santander wilde niet dat de extra belasting de latentie van de app zou beïnvloeden, of omgekeerd. Dit is ook de reden waarom we hebben besloten om HBase niet te gebruiken om zelfs de lokale winkels bij het opstarten op te starten.
Dus door elke Flume-agent een snelle lokale winkel te bieden om evenementen tijdens de vlucht te verrijken, kan Santander betere prestatiegaranties geven voor zowel verrijking tijdens de vlucht als de Spendlytics-app. We hebben besloten om RocksDB te gebruiken om de lokale winkels te implementeren, omdat het in staat is om snelle toegang te bieden tot grote hoeveelheden off-heap data (waardoor de last voor GC wordt geëlimineerd), en het feit dat het een Java API heeft om het gebruiksvriendelijker te maken. een aangepaste Flume Interceptor. Deze aanpak behoedde ons voor het coderen van onze eigen off-heap store. RocksDB kan gemakkelijk worden uitgewisseld voor een andere lokale winkelimplementatie, maar in dit geval was het perfect geschikt voor Santander's use case.
De aangepaste Flume-verrijking Interceptor-implementatie verwerkt gebeurtenissen van het upstream "getransformeerde" onderwerp, bevraagt de lokale winkel om ze te verrijken en schrijft de resultaten naar downstream Kafka-onderwerpen, afhankelijk van het resultaat. Dit proces wordt hieronder in meer detail geïllustreerd.
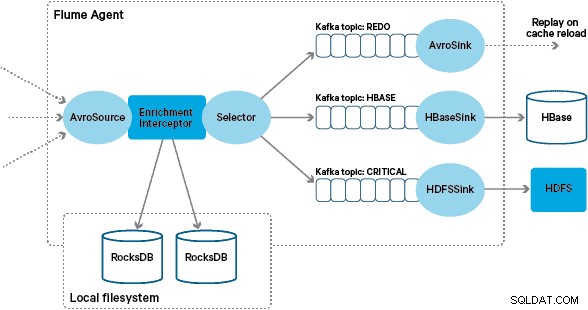
Op dit punt vraagt u zich misschien af:hoe worden lokale winkels gegenereerd zonder door HBase geleverde persistentie? De referentiegegevens bestaan uit een aantal verschillende datasets die moeten worden samengevoegd. Deze datasets worden dagelijks ververst in HDFS en vormen de input voor een geplande Apache Spark-applicatie, die de RocksDB-stores genereert. Nieuw gegenereerde RocksDB-winkels worden geënsceneerd in HDFS totdat ze worden gedownload door de Flume-agenten om ervoor te zorgen dat de gebeurtenisstroom wordt verrijkt met de nieuwste informatie.
Idealiter zouden we niet hoeven te wachten tot deze datasets allemaal beschikbaar zijn in HDFS voordat ze kunnen worden verwerkt. Als dit het geval zou zijn, zouden updates van referentiegegevens via de Flafka-pijplijn kunnen worden gestreamd om de status van lokale referentiegegevens continu te behouden.
In ons oorspronkelijke ontwerp hadden we gepland om via cron een script te schrijven en in te plannen om HDFS te pollen om te controleren op nieuwe versies van de RocksDB-winkels, en deze indien beschikbaar te downloaden van HDFS. Hoewel dit mechanisme vanwege de interne controles en het beheer van de productieomgevingen van Santander moest worden ingebouwd in dezelfde Flume Interceptor die wordt gebruikt om de verrijking uit te voeren (het controleert één keer per uur op updates, dus het is geen dure operatie). Wanneer een nieuwe versie van de winkel beschikbaar is, wordt een taak verzonden naar een werkthread om de nieuwe winkel van HDFS te downloaden en in RocksDB te laden. Dit proces gebeurt op de achtergrond terwijl de verrijkingsinterceptor de stream blijft verwerken. Zodra de nieuwe versie van de winkel in RocksDB is geladen, schakelt de Interceptor over naar de nieuwste versie en wordt de verlopen winkel verwijderd. Hetzelfde mechanisme wordt gebruikt om de RocksDB-winkels op te starten vanaf een koude start voordat de Interceptor begint te proberen gebeurtenissen te verrijken.
Met succes verrijkte berichten worden naar een Kafka-onderwerp geschreven om idempotent naar HBase te worden geschreven met behulp van de HBaseEventSerializer.
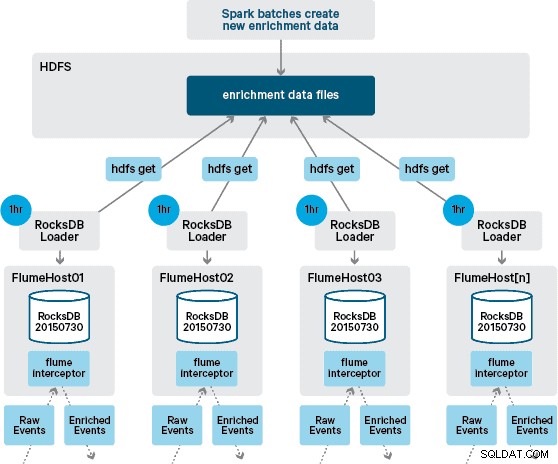
Hoewel de gebeurtenisstroom continu wordt verwerkt, kunnen nieuwe versies van de lokale winkel alleen dagelijks worden gegenereerd. Onmiddellijk nadat een nieuwe versie van de lokale winkel door Flume is geladen, wordt deze als vers beschouwd", hoewel deze steeds meer oud wordt voordat een nieuwe versie beschikbaar is. Bijgevolg neemt het aantal "cachemissers" toe totdat er een nieuwere versie van de lokale winkel beschikbaar is. Er kan bijvoorbeeld nieuwe en bijgewerkte merk- en handelaarinformatie worden toegevoegd aan de referentiegegevens, maar totdat deze beschikbaar wordt gesteld aan Flume's verrijking kunnen Interceptor-transacties niet worden verrijkt, of worden verrijkt met verouderde informatie die later moet worden verzoend nadat het is bewaard in HBase.
Om dit geval af te handelen, worden cachemissers (gebeurtenissen die niet worden verrijkt) geschreven naar een "opnieuw" Kafka-onderwerp met behulp van een Flume Selector. Het opnieuw-onderwerp wordt vervolgens opnieuw afgespeeld in het brononderwerp van de verrijking Interceptor wanneer er een nieuwe lokale winkel beschikbaar is.
Om "gifberichten" (gebeurtenissen die voortdurend niet verrijken) te voorkomen, hebben we besloten om een teller toe te voegen aan de kop van een gebeurtenis voordat deze wordt toegevoegd aan het opnieuw-onderwerp. Gebeurtenissen die herhaaldelijk over dat onderwerp verschijnen, worden uiteindelijk omgeleid naar een "kritiek" onderwerp, dat naar HDFS wordt geschreven voor latere inspectie en herstel. Deze benadering wordt geïllustreerd in het eerste diagram.
Conclusie
Om de belangrijkste afhaalpunten uit dit bericht samen te vatten:
- Het is een effectief patroon om een reeks Kafka-onderwerpen te gebruiken om tussentijdse gedeelde gegevens op te slaan als onderdeel van uw ingest-pipeline.
- U hebt meerdere opties voor het bewaren en opvragen van status- of referentiegegevens in uw NRT-opnamepijplijn. Geef voor dit doel de voorkeur aan HBase als het gebruikelijke patroon wanneer de aanvullende gegevens groot zijn, maar overweeg het gebruik van embedded lokale winkels (zoals RocksDB) of JVM-geheugen voor wanneer het gebruik van HBase niet praktisch is.
- Foutafhandeling is belangrijk. (Zie #1 voor hulp daarbij.)
In een vervolgbericht zullen we beschrijven hoe we gebruik maken van HBase-coprocessors om per klant aggregaties van historische inkooptrends te bieden, en hoe offline transacties batchgewijs worden verwerkt met (Cloudera Labs-project) SparkOnHBase (dat onlangs is vastgelegd in de HBase koffer). We zullen ook beschrijven hoe de oplossing is ontworpen om te voldoen aan de eisen van de klant over meerdere datacenters en hoge beschikbaarheid.
James Kinley, Ian Buss en Rob Siwicki zijn Solution Architects bij Cloudera.