Apache Hadoop is een softwareframework dat big data verwerkt en opslaat in het cluster van standaardhardware. Hadoop is gebaseerd op het MapReduce-model voor het verwerken van enorme hoeveelheden gegevens op een gedistribueerde manier.
Deze MapReduce-zelfstudie maakte gebruik van verschillende functies van MapReduce. Na dit te hebben gelezen, zult u duidelijk begrijpen waarom MapReduce het beste geschikt is voor het verwerken van grote hoeveelheden gegevens.
Eerst zullen we een kleine introductie zien van het MapReduce-framework. Daarna zullen we verschillende functies van MapReduce verkennen.
Laten we beginnen met de inleiding tot het MapReduce-framework.
Inleiding tot MapReduce
MapReduce is een softwareframework voor het schrijven van applicaties die enorme hoeveelheden gegevens kunnen verwerken over de clusters van goedkope knooppunten. Hadoop MapReduce is het verwerkingsgedeelte van Apache Hadoop.
Het wordt ook wel het hart van Hadoop genoemd. Het is de meest geprefereerde toepassing voor gegevensverwerking. Verschillende spelers in de e-commercesector, zoals Amazon, Yahoo en Zuventus, enz. gebruiken het MapReduce-framework voor de verwerking van grote hoeveelheden gegevens.
Laten we nu de verschillende functies van Hadoop MapReduce bestuderen.
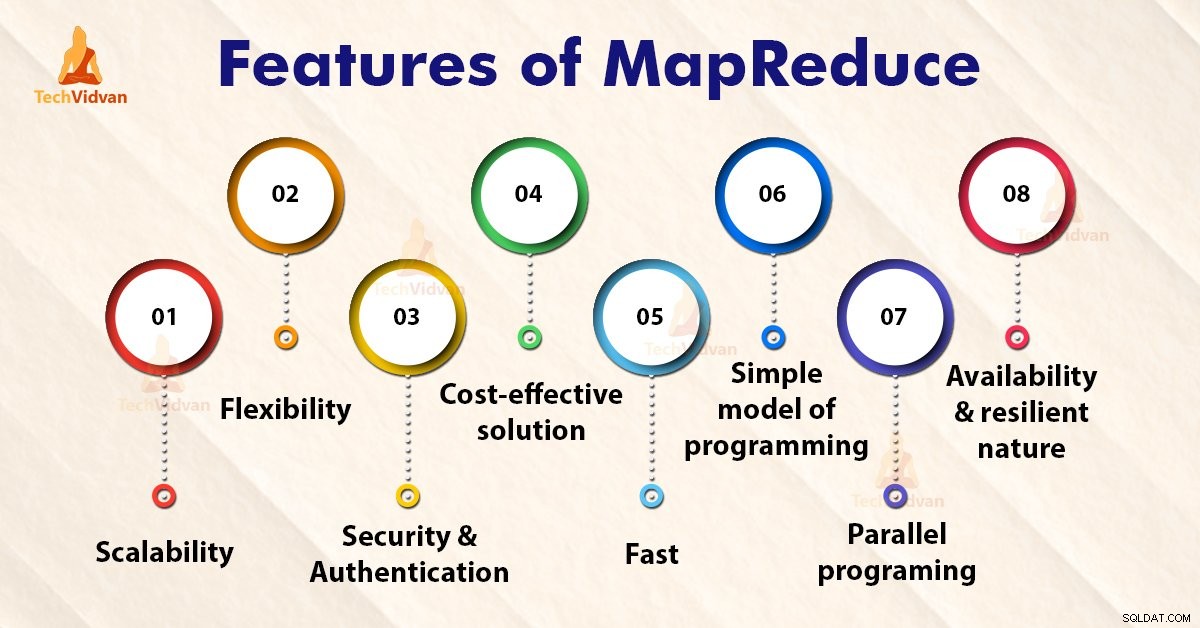
Kenmerken van MapReduce
1. Schaalbaarheid
Apache Hadoop is een zeer schaalbaar framework. Dit komt door het vermogen om enorme gegevens op te slaan en te distribueren over tal van servers. Al deze servers waren goedkoop en kunnen parallel werken. We kunnen de opslag- en rekenkracht eenvoudig opschalen door servers aan het cluster toe te voegen.
Met Hadoop MapReduce-programmering kunnen organisaties applicaties uitvoeren vanaf grote sets knooppunten, waarvoor duizenden terabytes aan gegevens nodig zijn.
Met Hadoop MapReduce-programmering kunnen bedrijfsorganisaties applicaties uitvoeren vanaf grote sets knooppunten. Dit kan duizenden terabytes aan gegevens gebruiken.
2. Flexibiliteit
MapReduce-programmering stelt bedrijven in staat toegang te krijgen tot nieuwe gegevensbronnen. Het stelt bedrijven in staat om met verschillende soorten data te werken. Het stelt ondernemingen in staat toegang te krijgen tot zowel gestructureerde als ongestructureerde gegevens, en aanzienlijke waarde te ontlenen aan inzichten uit meerdere gegevensbronnen.
Daarnaast biedt het MapReduce-framework ook ondersteuning voor de meerdere talen en gegevens uit bronnen variërend van e-mail, sociale media tot clickstream.
De MapReduce verwerkt gegevens in eenvoudige sleutel-waardeparen en ondersteunt dus het gegevenstype inclusief metagegevens, afbeeldingen en grote bestanden. Daarom is MapReduce flexibel om met gegevens om te gaan in plaats van traditionele DBMS.
3. Beveiliging en authenticatie
Het MapReduce-programmeermodel maakt gebruik van het HBase- en HDFS-beveiligingsplatform dat alleen toegang geeft aan de geverifieerde gebruikers om met de gegevens te werken. Zo beschermt het ongeoorloofde toegang tot systeemgegevens en verbetert het de systeembeveiliging.
4. Kosteneffectieve oplossing
De schaalbare architectuur van Hadoop met het MapReduce-programmeerframework maakt de opslag en verwerking van grote datasets op een zeer betaalbare manier mogelijk.
5. Snel
Hadoop gebruikt een gedistribueerde opslagmethode die Hadoop Distributed File System wordt genoemd en die in feite een kaartsysteem implementeert voor het lokaliseren van gegevens in een cluster.
De tools die worden gebruikt voor gegevensverwerking, zoals MapReduce-programmering, bevinden zich over het algemeen op dezelfde servers die een snellere verwerking van gegevens mogelijk maken.
Dus zelfs als we te maken hebben met grote hoeveelheden ongestructureerde gegevens, kost Hadoop MapReduce slechts enkele minuten om terabytes aan gegevens te verwerken. Het kan petabytes aan gegevens in slechts een uur verwerken.
6. Eenvoudig programmeermodel
Een van de belangrijkste kenmerken van Hadoop MapReduce is dat het gebaseerd is op een eenvoudig programmeermodel. Kortom, dit stelt programmeurs in staat om de MapReduce-programma's te ontwikkelen die taken gemakkelijk en efficiënt kunnen afhandelen.
De MapReduce-programma's kunnen in Java worden geschreven, wat niet erg moeilijk is om op te pikken en ook veel wordt gebruikt. Iedereen kan dus gemakkelijk MapReduce-programma's leren en schrijven en aan hun behoeften op het gebied van gegevensverwerking voldoen.
7. Parallel programmeren
Een van de belangrijkste aspecten van de werking van MapReduce-programmering is de parallelle verwerking. Het verdeelt de taken zodanig dat ze parallel kunnen worden uitgevoerd.
Door de parallelle verwerking kunnen meerdere processors deze verdeelde taken uitvoeren. Dus het hele programma wordt in minder tijd uitgevoerd.
8. Beschikbaarheid en veerkrachtig karakter
Telkens wanneer de gegevens naar een afzonderlijk knooppunt worden verzonden, wordt dezelfde set gegevens doorgestuurd naar enkele andere knooppunten in een cluster. Dus als een bepaald knooppunt een storing heeft, zijn er altijd andere kopieën aanwezig op andere knooppunten die nog steeds toegankelijk zijn wanneer dat nodig is. Dit zorgt voor een hoge beschikbaarheid van gegevens.
Een van de belangrijkste functies van Apache Hadoop is de fouttolerantie. Het Hadoop MapReduce-framework heeft de mogelijkheid om snel optredende fouten te herkennen.
Het past dan een snelle en automatische hersteloplossing toe. Deze functie maakt het een game-changer in de wereld van big data-verwerking.
Samenvatting
Ik hoop dat je na het lezen van dit artikel de verschillende functies van Hadoop MapReduce duidelijk hebt begrepen. Het artikel maakte gebruik van verschillende functies van MapReduce. Het MapReduce-framework is een schaalbaar, flexibel, kosteneffectief en snel verwerkingssysteem.
Het biedt beveiliging, fouttolerantie en authenticatie. MapReduce is een eenvoudig programmeermodel en biedt parallel programmeren.