Als je alles wilt weten over Hadoop MapReduce, ben je op de juiste plek beland. Deze MapReduce-zelfstudie biedt u de complete gids over alles en nog wat in Hadoop MapReduce.
In deze MapReduce-introductie onderzoekt u wat Hadoop MapReduce is, hoe het MapReduce-framework werkt. Het artikel behandelt ook MapReduce DataFlow, verschillende fasen in MapReduce, Mapper, Reducer, Partitioner, Cominer, Shuffling, Sorting, Data Locality en nog veel meer.
We hebben ook gebruik gemaakt van de voordelen van het MapReduce-framework.
Laten we eerst onderzoeken waarom we Hadoop MapReduce nodig hebben.
Waarom MapReduce?
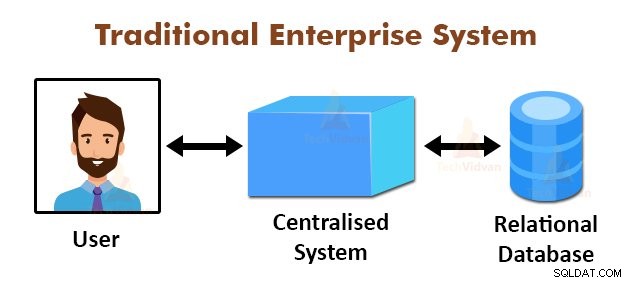
De bovenstaande afbeelding toont het schematische aanzicht van de traditionele bedrijfssystemen. De traditionele systemen hebben normaal gesproken een gecentraliseerde server voor het opslaan en verwerken van gegevens. Dit model is niet geschikt voor het verwerken van enorme hoeveelheden schaalbare gegevens.
Ook kon dit model niet worden geaccommodeerd door de standaard databaseservers. Bovendien creëert het gecentraliseerde systeem te veel knelpunten bij het gelijktijdig verwerken van meerdere bestanden.
Door het MapReduce-algoritme te gebruiken, loste Google dit knelpuntprobleem op. Het MapReduce-framework verdeelt de taak in kleine delen en wijst taken toe aan veel computers.
Later worden de resultaten verzameld op een gemeenplaats en vervolgens geïntegreerd om de resultaatdataset te vormen.
Inleiding tot MapReduce Framework
MapReduce is de verwerkingslaag in Hadoop. Het is een softwareframework dat is ontworpen voor het parallel verwerken van enorme hoeveelheden gegevens door de taak op te delen in een reeks onafhankelijke taken.
We hoeven alleen de bedrijfslogica in de manier waarop MapReduce werkt te plaatsen, en het raamwerk zorgt voor de rest. Het MapReduce-framework werkt door de taak op te delen in kleine taken en deze taken toe te wijzen aan de slaven.
De MapReduce-programma's zijn geschreven in een bepaalde stijl die wordt beïnvloed door de functionele programmeerconstructies, specifieke idiomen voor het verwerken van de lijsten met gegevens.
In MapReduce zijn de inputs in de vorm van een lijst en de output van het framework ook in de vorm van een lijst. MapReduce is het hart van Hadoop. De efficiëntie en kracht van Hadoop zijn te danken aan de parallelle verwerking van het MapReduce-framework.
Laten we nu onderzoeken hoe Hadoop MapReduce werkt.
Hoe werkt Hadoop MapReduce?
Het Hadoop MapReduce-framework werkt door een taak te verdelen in onafhankelijke taken en deze taken uit te voeren op slave-machines. De MapReduce-taak wordt uitgevoerd in twee fasen, namelijk de kaartfase en de reductiefase.
De invoer naar en uitvoer van beide fasen zijn sleutel-waardeparen. Het MapReduce-framework is gebaseerd op het gegevenslokaliteitsprincipe (later besproken), wat betekent dat het de berekening naar de knooppunten stuurt waar de gegevens zich bevinden.
- Kaartfase − In de kaartfase verwerkt de door de gebruiker gedefinieerde kaartfunctie de invoergegevens. In de kaartfunctie plaatst de gebruiker de bedrijfslogica. De uitvoer van de kaartfase is de tussenliggende uitvoer en wordt opgeslagen op de lokale schijf.
- Verminder fase – Deze fase is de combinatie van de shuffle-fase en de reduceerfase. In de verkleiningsfase wordt de uitvoer van de kaartfase doorgegeven aan de verkleiner waar ze worden geaggregeerd. De output van de reduceerfase is de uiteindelijke output. In de Reduce-fase verwerkt de door de gebruiker gedefinieerde reduce-functie de uitvoer van Mappers en genereert de uiteindelijke resultaten.
Tijdens de MapReduce-taak stuurt het Hadoop-framework de kaarttaken en de Reduce-taken naar de juiste machines in het cluster.
Het framework zelf beheert alle details van de gegevensoverdracht, zoals het uitgeven van taken, het verifiëren van de taakvoltooiing en het kopiëren van gegevens tussen de knooppunten rond het cluster. De taken vinden plaats op de knooppunten waar de gegevens zich bevinden om het netwerkverkeer te verminderen.
MapReduce-gegevensstroom
U wilt misschien allemaal weten hoe deze sleutelwaardeparen worden gegenereerd en hoe MapReduce de invoergegevens verwerkt. Dit gedeelte beantwoordt al deze vragen.
Laten we eens kijken hoe gegevens uit verschillende fasen in Hadoop MapReduce moeten stromen om aankomende gegevens op een parallelle en gedistribueerde manier te verwerken.
1. InputFiles
De invoergegevensset, die door het MapReduce-programma moet worden verwerkt, wordt opgeslagen in het InputFile. Het InputFile wordt opgeslagen in het Hadoop Distributed File System.
2. InputSplit
Het record in de InputFiles wordt opgesplitst in het logische model. De gesplitste grootte is over het algemeen gelijk aan de HDFS-blokgrootte. Elke splitsing wordt verwerkt door de individuele Mapper.
3. Invoerformaat
InputFormat specificeert de bestandsinvoerspecificatie. Het definieert de weg naar de RecordReader waarin het record uit het InputFile wordt omgezet in de sleutel-waardeparen.
4. RecordReader
RecordReader leest de gegevens van de InputSplit en converteert records naar de sleutel-, waardeparen en presenteert deze aan de Mappers.
5. Mappers
Mappers nemen sleutel-, waardeparen als invoer van de RecordReader en verwerken deze door een door de gebruiker gedefinieerde kaartfunctie te implementeren. In elke Mapper wordt tegelijk een enkele splitsing verwerkt.
De ontwikkelaar heeft de bedrijfslogica in de kaartfunctie gezet. De uitvoer van alle mappers is de tussenuitvoer, die ook de vorm heeft van een sleutel, waardeparen.
6. Shuffle en sorteer
De tussentijdse output die door Mappers wordt gegenereerd, wordt gesorteerd voordat deze naar de Reducer gaat om de netwerkcongestie te verminderen. De gesorteerde tussenuitgangen worden vervolgens via het netwerk geschud naar de Reducer.
7. Verloopstuk
Het Reducer-proces en aggregeert de Mapper-outputs door een door de gebruiker gedefinieerde reduceerfunctie te implementeren. De uitvoer van de Reducers is de uiteindelijke uitvoer en wordt opgeslagen in het Hadoop Distributed File System (HDFS).
Laten we nu enkele terminologieën en geavanceerde concepten van het Hadoop MapReduce-framework bestuderen.
Sleutel-waardeparen in MapReduce
Het MapReduce-framework werkt op de sleutel-waardeparen omdat het zich bezighoudt met het niet-statische schema. Het neemt gegevens in de vorm van een sleutel, waardepaar en gegenereerde output is ook in de vorm van een sleutel, waardeparen.
Het MapReduce-sleutelwaardepaar is een recordentiteit die door de MapReduce-taak wordt ontvangen voor de uitvoering. In een sleutel/waarde-paar:
- Sleutel is de lijnverschuiving vanaf het begin van de lijn in het bestand.
- Waarde is de regelinhoud, exclusief de regelafsluitingen.
MapReduce Partitioner
De Hadoop MapReduce Partitioner verdeelt de keyspace. Het partitioneren van keyspace in MapReduce geeft aan dat alle waarden van elke sleutel zijn gegroepeerd, en het zorgt ervoor dat alle waarden van de enkele sleutel naar dezelfde Reducer moeten gaan.
Deze partitionering maakt een gelijkmatige verdeling van de uitvoer van de mapper over Reducer mogelijk door ervoor te zorgen dat de juiste sleutel naar de juiste Reducer gaat.
De standaard MapReducer-partitioner is de Hash Partitioner, die de keyspaces partitioneert op basis van de hash-waarde.
MapReduce Combiner
De MapReduce Combiner is ook bekend als de "Semi-Reducer". Het speelt een belangrijke rol bij het verminderen van netwerkcongestie. Het MapReduce-framework biedt de functionaliteit om de Combiner te definiëren, die de tussentijdse uitvoer van Mappers combineert voordat ze aan Reducer worden doorgegeven.
De aggregatie van Mapper-outputs voordat ze worden doorgegeven aan Reducer, helpt het framework kleine hoeveelheden gegevens te schudden, wat leidt tot een lage netwerkcongestie.
De belangrijkste functie van de Combiner is om de output van de Mappers met dezelfde sleutel samen te vatten en door te geven aan de Reducer. De klasse Combiner wordt gebruikt tussen de klasse Mapper en de klasse Reducer.
Gegevenslocatie in MapReduce
Gegevenslocatie verwijst naar "Berekening dichter bij de gegevens brengen in plaats van gegevens naar de berekening te verplaatsen." Het is veel efficiënter als de door de toepassing gevraagde berekening wordt uitgevoerd op de machine waar de gevraagde gegevens zich bevinden.
Dit is zeer waar in het geval dat de gegevensomvang enorm is. Het is omdat het de netwerkcongestie minimaliseert en de algehele doorvoer van het systeem verhoogt.
De enige veronderstelling hierachter is dat het beter is om de berekening dichter bij de machine te plaatsen waar gegevens aanwezig zijn in plaats van gegevens te verplaatsen naar de machine waarop de applicatie draait.
Apache Hadoop werkt met een enorme hoeveelheid gegevens, dus het is niet efficiënt om zulke enorme gegevens over het netwerk te verplaatsen. Daarom kwam het raamwerk met het meest innovatieve principe, namelijk gegevenslokaliteit, die de berekeningslogica naar gegevens verplaatst in plaats van gegevens naar berekeningsalgoritmen te verplaatsen. Dit wordt datalocatie genoemd.
Voordelen van MapReduce
Gebruik van MapReduce
Telkens wanneer een webpagina in het logboek wordt gevonden, wordt een sleutel, een waardepaar doorgegeven aan de verkleiner waar de sleutel de webpagina is en de waarde "1" is. Na het verzenden van een sleutel, waardepaar naar Reducer, aggregeren de Reducers het aantal voor bepaalde webpagina's.
Het uiteindelijke resultaat is het totale aantal hits voor elke webpagina.
3. Google gebruikt MapReduce voor het berekenen van hun Pagerank.
De functie reduceert vervolgens de lijst van alle bron-URL's die zijn gekoppeld aan de opgegeven doel-URL en retourneert het doel en de lijst met bronnen.
Samenvatting
Dit gaat allemaal over de Hadoop MapReduce-zelfstudie. Het framework verwerkt enorme hoeveelheden gegevens parallel over het cluster van basishardware. Het verdeelt de taak in onafhankelijke taken en voert deze parallel uit op verschillende knooppunten in het cluster.
MapReduce overwint het knelpunt van het traditionele bedrijfssysteem. Het raamwerk werkt op de sleutel-waardeparen. De gebruiker definieert de twee functies die de kaartfunctie en de reductiefunctie zijn.
De bedrijfslogica wordt in de kaartfunctie gezet. In het artikel waren verschillende geavanceerde concepten van het MapReduce-framework uitgelegd.