In onze vorige Hadoop-zelfstudie , we hebben Hadoop Partitioner . bestudeerd in detail. Nu gaan we InputSplit bespreken in Hadoop MapReduce.
Hier bespreken we wat Hadoop InputSplit is, de noodzaak van InputSplit in MapReduce. We zullen ook in detail bespreken hoe deze InputSplits worden gemaakt in Hadoop MapReduce.
Inleiding tot InputSplit in Hadoop
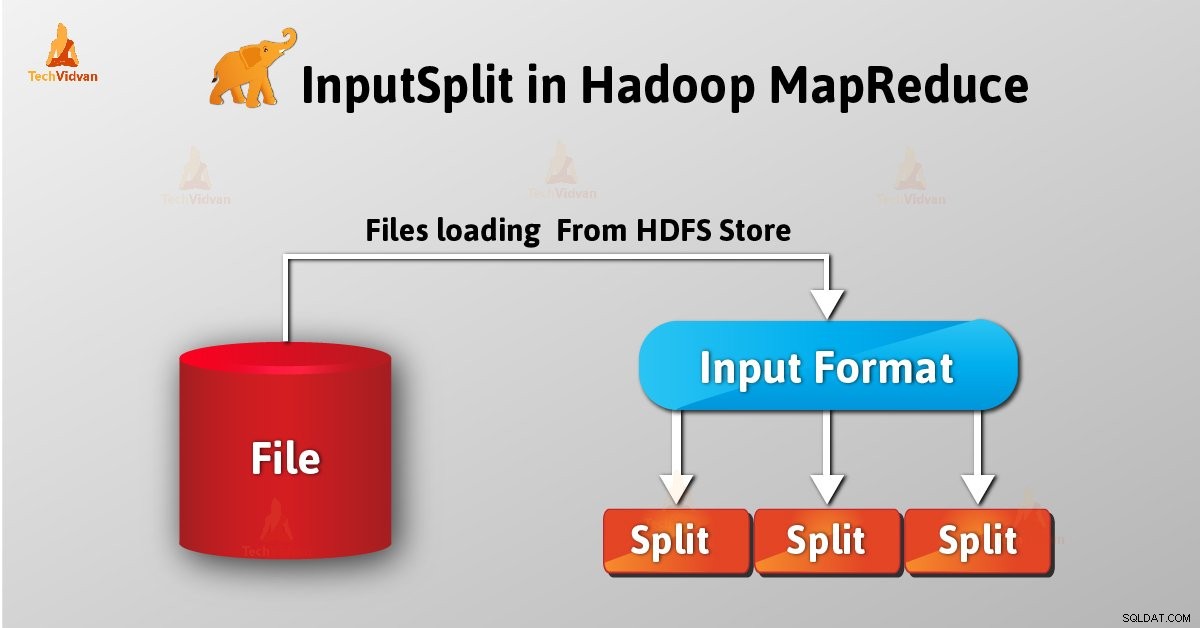
InputSplit is de logische weergave van gegevens in Hadoop MapReduce. Het vertegenwoordigt de gegevens die individuele mapper processen. Het aantal kaarttaken is dus gelijk aan het aantal InputSplits. Framework verdeelt opgesplitst in records, die mapper verwerkt.
De lengte van MapReduce InputSplit is gemeten in bytes. Elke InputSplit heeft opslaglocaties (hostnaamstrings). Het MapReduce-systeem plaatst kaarttaken zo dicht mogelijk bij de gegevens van de splitsing door gebruik te maken van opslaglocaties.
Kaderprocessen Map taken in de volgorde van de grootte van de splitsingen, zodat de grootste eerst wordt verwerkt (greedy benaderingsalgoritme). Dit minimaliseert de doorlooptijd van de taak.
Het belangrijkste om te focussen is dat Inputsplit de invoergegevens niet bevat; het is slechts een verwijzing naar de gegevens.
Hoe worden InputSplits gemaakt in Hadoop MapReduce?
Als gebruiker werken we niet rechtstreeks met InputSplit in Hadoop, als InputFormat (aangezien InputFormat verantwoordelijk is voor het maken van de Inputsplit en het verdelen in de records) maakt het. FileInputFormat verdeelt een bestand in stukken van 128 MB.
Ook door mapred . in te stellen .min .gesplitst .maat parameter in mapred-site .xml gebruiker kan de waarde per vereiste wijzigen. Hierdoor kunnen we ook de parameter in het Job-object overschrijven dat wordt gebruikt om een bepaalde MapReduce-job in te dienen.
Door een aangepast InputFormat te schrijven, kunnen we ook bepalen hoe het bestand in splitsingen wordt opgedeeld.
InputSplit is door de gebruiker gedefinieerd. De gebruiker kan ook de gesplitste grootte regelen op basis van de gegevensgrootte in het MapReduce-programma. Daarom is in een MapReduce-taakuitvoering het aantal kaarttaken gelijk aan het aantal InputSplits.
Door ‘getSplit()’ . aan te roepen , berekent de klant de splitsingen voor de baan. Vervolgens wordt het naar de applicatiemaster gestuurd, die hun opslaglocaties gebruikt om kaarttaken te plannen die ze op het cluster zullen verwerken.
Daarna geeft de kaarttaak de splitsing door aan de createRecordReader() methode. Daaruit haalt het RecordReader voor de splitsing. Vervolgens genereert RecordReader record (sleutel-waardepaar) , die het doorgeeft aan de kaartfunctie.
Conclusie
Concluderend kunnen we zeggen dat InputSplit de gegevens vertegenwoordigt die individuele mapper verwerkt. Voor elke splitsing wordt één kaarttaak gemaakt. Daarom creëert InputFormat de InputSplit.
Als je vragen hebt over InputSplit in MapReduce, laat dan een reactie achter in een sectie hieronder.