In deze Big data Hadoop-tutorial , gaan we u een gedetailleerde beschrijving geven van het Hadoop HDFS-gegevensblok. Allereerst zullen we bespreken wat een datablok is in Hadoop, wat hun belang is, waarom de grootte van HDFS-datablokken 128 MB is.
We zullen ook het voorbeeld van datablokken in Hadoop en verschillende voordelen van HDFS in Hadoop bespreken.
Inleiding tot HDFS-gegevensblok
Hadoop HDFS splits grote bestanden in kleine stukjes die bekend staan als Blocks . Blok is de fysieke representatie van gegevens. Het bevat een minimale hoeveelheid gegevens die kan worden gelezen of geschreven. HDFS slaat elk bestand op als blokken. HDFS-client heeft geen controle over het blok, zoals de locatie van het blok, Namenode beslist over al dergelijke dingen.
Standaard is de HDFS-blokgrootte 128 MB die u volgens uw vereiste kunt wijzigen. Alle HDFS-blokken hebben dezelfde grootte, behalve het laatste blok, dat even groot of kleiner kan zijn.
Hadoop-framework breekt bestanden op in blokken van 128 MB en slaat ze vervolgens op in het Hadoop-bestandssysteem. Apache Hadoop-applicatie is verantwoordelijk voor het distribueren van het datablok over meerdere nodes.
Voorbeeld-
Stel dat de bestandsgrootte 513 MB is, en we gebruiken de standaardconfiguratie van blokgrootte 128 MB. Vervolgens zal het Hadoop-framework 5 blokken maken, de eerste vier blokken van 128 MB, maar het laatste blok is slechts 1 MB.
Vandaar dat uit het voorbeeld duidelijk is dat het niet nodig is dat in HDFS elk bestand dat wordt opgeslagen een exact veelvoud is van de geconfigureerde blokgrootte 128 MB, 256 MB enz. Daarom gebruikt het laatste blok voor bestanden slechts zoveel ruimte als nodig is.
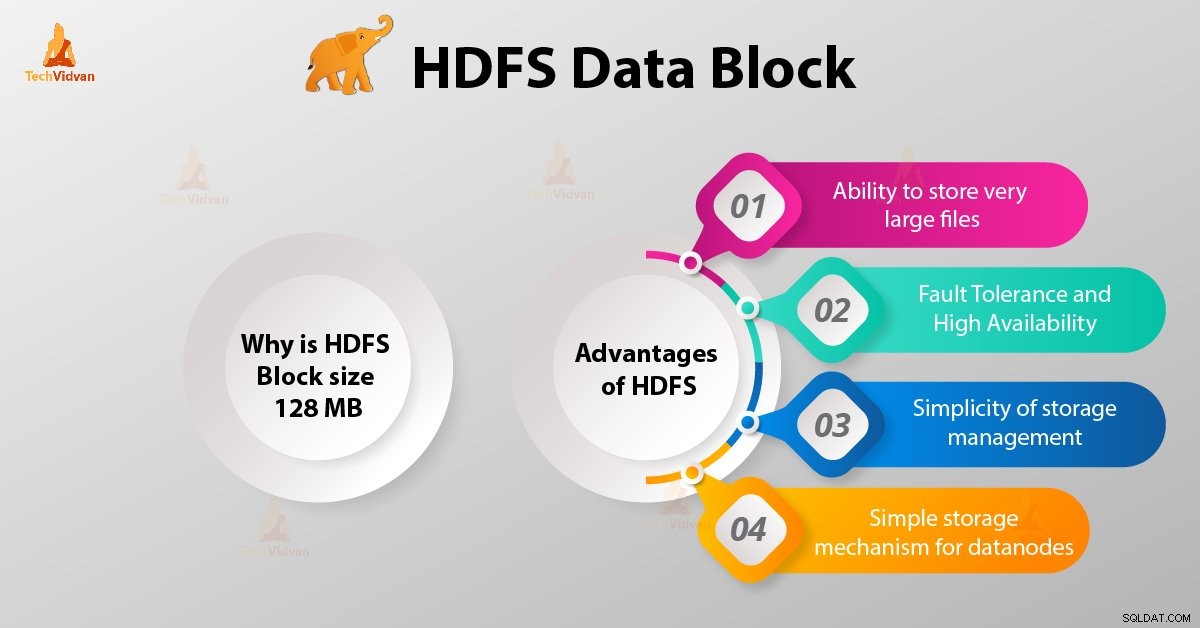
Waarom is HDFS-blokgrootte 128 MB?
HDFS slaat terabytes en petabytes aan gegevens op. Als de HDFS-blokgrootte 4 kb is, zoals het Linux-bestandssysteem, dan hebben we te veel datablokken in Hadoop HDFS, dus te veel metadata.
Dus het onderhouden en beheren van dit enorme aantal blokken en metadata zal enorme overhead en verkeer veroorzaken, iets wat we niet willen.
De blokgrootte kan niet zo groot zijn dat het systeem heel lang wacht op een laatste eenheid gegevensverwerking om zijn werk te voltooien.
Voordelen van HDFS
Laten we, nadat we hebben geleerd wat HDFS-gegevensblok is, de voordelen van Hadoop HDFS bespreken.
1. Mogelijkheid om zeer grote bestanden op te slaan
Hadoop HDFS slaat zeer grote bestanden op die zelfs groter zijn dan de grootte van een enkele schijf, aangezien het Hadoop-framework het bestand in blokken opdeelt en over verschillende knooppunten distribueert.
2. Fouttolerantie en hoge beschikbaarheid van HDFS
Het Hadoop-framework kan eenvoudig blokken repliceren tussen de datanodes. Zorg dus voor fouttolerantie en hoge beschikbaarheid HDFS.
3. Eenvoud van opslagbeheer
Aangezien HDFS een vaste blokgrootte (128 MB) heeft, is het heel eenvoudig om het aantal blokken te berekenen dat op de schijf kan worden opgeslagen.
4. Eenvoudig opslagmechanisme voor datanodes
Blokkeren in HDFS vereenvoudigt de opslag van deDatanodes . Namenode onderhoudt metadata van alle blokken. HDFS Datanode hoeft zich geen zorgen te maken over de blokmetadata zoals bestandspermissies enz.
Conclusie
Daarom is het HDFS-gegevensblok de kleinste gegevenseenheid in een bestandssysteem. De standaardgrootte van het HDFS-blok is 128 MB, die u naar wens kunt configureren. HDFS-blokken zijn eenvoudig te repliceren tussen de datanodes. Zorg daarom voor fouttolerantie en hoge beschikbaarheid van HDFS.
Voor elke vraag of suggestie met betrekking tot Hadoop HDFS-gegevensblokken, laat het ons weten door een opmerking achter te laten in een sectie hieronder.