In deze Hadoop-zelfstudie , gaan we u een volledige introductie geven van HDFS Federation. In deze tutorial bespreken we HDFS-architectuur, beperkingen van de huidige architectuur van HDFS.
Daarna zullen we de HDFS Federation-architectuur in detail bespreken, samen met hun voordelen in het Hadoop-framework.
Wat is HDFS-federatie?
Federatie verbetert een bestaande Hadoop HDFS architectuur. Voorafgaande HDFS-architectuur maakt een enkele naamruimte voor het hele cluster mogelijk. In die architectuur beheert enkele NameNode de naamruimte.
Als NameNode mislukt, is het hele cluster buiten dienst. En het cluster zal niet beschikbaar zijn totdat de NameNode opnieuw is opgestart of op een aparte machine is geplaatst.
HDFS Federation is geïntroduceerd om deze beperking te verhelpen. Het lost dit op door ondersteuning voor veel NameNode/Namespaces toe te voegen aan HDFS.
Huidige HDFS-architectuur
HDFS heeft twee hoofdlagen die hieronder worden gegeven:
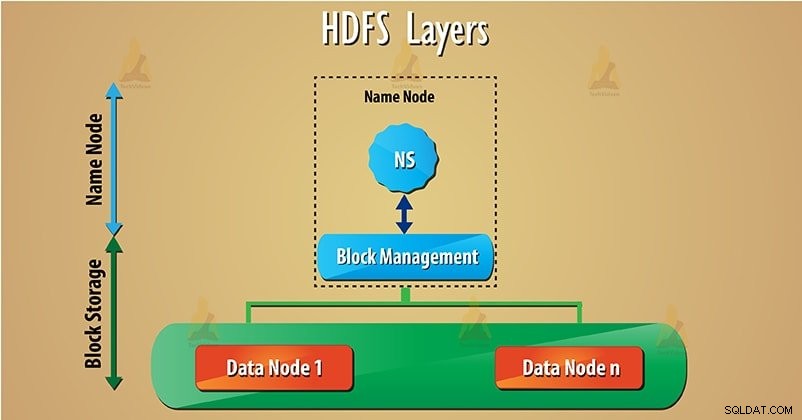
a) Naamruimte – Deze laag beheert bestanden, mappen en blokken . Deze laag ondersteunt de basisbewerkingen van het bestandssysteem, zoals het maken en verwijderen van bestanden.
b) Opslag blokkeren – Het bestaat uit twee delen-
- Beheer van blokkades – Het ondersteunt blokgerelateerde bewerkingen, zoals het maken en verwijderen van de blokken. Het beheert gegevensknooppunten in het cluster en zorgt voor replicatiebeheer.
- Fysieke opslag – Dit slaat de blokken op het lokale bestandssysteem op en geeft toegang tot lees- of schrijfbewerkingen. Volg deze link om te leren lezen en schrijven van HDFS-gegevens.
Deze huidige HDFS werkt prima voor kleinere opstellingen. Maar voor grote organisaties waar we voor de enorme hoeveelheid gegevens moeten zorgen, is er een beperking. Hadoop-federatie behandelt deze beperkingen.
Beperking van de huidige HDFS-architectuur
Beperking van de huidige HDFS-architectuur wordt hieronder gegeven:
1. Nauw gekoppelde blokopslag en naamruimte
Naamruimtelaag en opslaglaag zijn strak aan elkaar gekoppeld. Het maakt alternatieve implementatie van namenode moeilijk. En het beperkt andere services om blokopslag te gebruiken.
2. Schaalbaarheid naamruimte
De naamruimte is niet schaalbaar zoals datanode. Schalen in HDFS-cluster gebeurt horizontaal door datanodes toe te voegen. Maar we kunnen niet meer naamruimte toevoegen aan een bestaand cluster. We kunnen de naamruimte verticaal schalen op een enkele namenode.
3. Prestaties
De volledige prestatie van Hadoop hangt af van de doorvoer van de namenode. Een bewerking van het huidige bestandssysteem is afhankelijk van de doorvoer van een enkele namenode. NameNode ondersteunt momenteel 60.000 gelijktijdige taken.
Aanstaande MapReduce zal ondersteuning bieden voor meer dan 100.000 gelijktijdige taken. En dit heeft meer namenode nodig.
4. Isolatie
Er is geen scheiding van de naamruimte. Er is dus geen isolatie tussen de huurdersorganisatie die het cluster gebruikt.
HDFS Federatie-architectuur
Federation gebruikt veel onafhankelijke Namenode/namespaces om de naamservice horizontaal te schalen. In HDFS Federation Architecture zijn onderaan datanodes aanwezig. En datanodes worden door alle namenodes gebruikt als een gemeenschappelijke opslag voor blokken.
Elke datanodes registreert zich bij alle namenodes in het cluster. Deze datanodes sturen periodieke hartslagen, blokkeren, rapporteren en verwerken commando's van de namenodes.
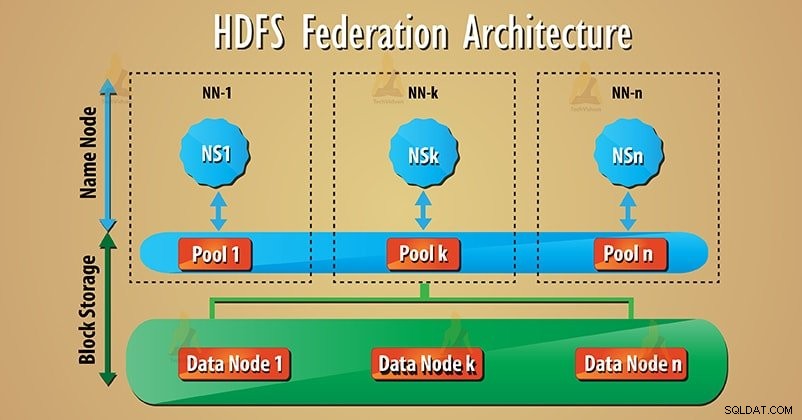
Veel namenodes (NN1, NN2..., NNn) beheren respectievelijk veel naamruimten (NS1, NS2..., NSn). Elke naamruimte heeft zijn eigen blokpool (NS1 heeft pool 1 enzovoort). Blokkering van pool 1 wordt opgeslagen op datanode 1 enzovoort.
1. Blokkeer pool
Set blokken is Blockpool die tot een enkele naamruimte behoort. Er is een verzameling pools in HDFS-federatiearchitectuur. En elk blok wordt vanuit het andere beheerd.
Hierdoor kan een naamruimte een blok-ID maken voor nieuwe blokken zonder coördinatie met een andere naamruimte. Alle Datanodes slaan datablokken op die aanwezig zijn in alle blokpools.
2. Naamruimtevolume
Naamruimte samen met de blokpool is Namespace-volume . Veel naamruimtevolumes zijn aanwezig in HDFS-federatie. Elk naamruimtevolume werkt dus onafhankelijk. Wanneer we namenode of namespace verwijderen, wordt de bijbehorende blokpool die aanwezig is op de datanodes ook verwijderd.
Voordelen van HDFS-federatie
HDFS Federation overwint de beperkingen van eerdere HDFS-architectuur. Daarom biedt het:
- Isolatie – Er is geen isolatie in enkele namenode in een omgeving met meerdere gebruikers. In HDFS-federatie kunnen verschillende categorieën van toepassingen en gebruikers worden geïsoleerd in verschillende naamruimten door veel namenodes te gebruiken.
- Schaalbaarheid naamruimte – In federatie schalen veel namenodes horizontaal op in de naamruimte van het bestandssysteem.
- Prestaties – We kunnen de lees-/schrijfsnelheid verbeteren door meer namenodes toe te voegen.
Conclusie
Tot besluit van HDFS Federation kunnen we zeggen dat het de beperking van HDFS-architectuur met één knooppunt overwint. In eerdere HDFS-architectuur is voor een volledig cluster slechts één naamruimte toegestaan. Terwijl Federation veel onafhankelijke Namenode/namespaces gebruikt om de naamservice horizontaal te schalen.
Het scheidt ook de naamruimtelaag en de opslag laag. Biedt daarom isolatie, schaalbaarheid en een eenvoudig ontwerp.
Als je een vraag of suggestie hebt met betrekking tot de Federatie in Hadoop HDFS, laat het ons dan weten door een reactie achter te laten.