Wilt u alles weten over het Hadoop-cluster?
Hadoop is een softwareraamwerk voor het analyseren en opslaan van enorme hoeveelheden gegevens in clusters van standaardhardware. In dit artikel zullen we een Hadoop-cluster bestuderen.
Laten we eerst beginnen met een inleiding tot Cluster.
Wat is een cluster?
Een cluster is een verzameling knooppunten. Knooppunten zijn niets anders dan een verbindingspunt/kruispunt binnen een netwerk.
Een computercluster is een verzameling computers die met een netwerk zijn verbonden, met elkaar kunnen communiceren en als één systeem werken.
Wat is Hadoop-cluster?
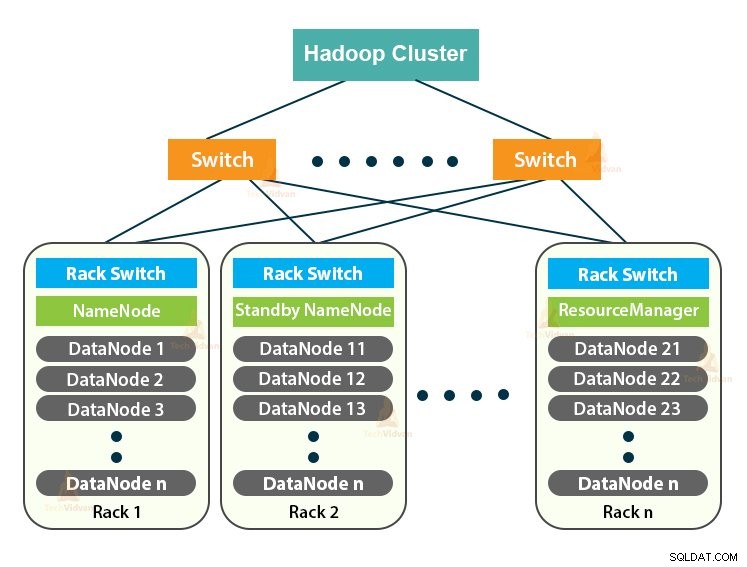
Hadoop Cluster is slechts een computercluster dat wordt gebruikt om een enorme hoeveelheid gegevens op een gedistribueerde manier te verwerken.
Het is een rekencluster dat is ontworpen voor het opslaan en analyseren van enorme hoeveelheden ongestructureerde of gestructureerde gegevens in een gedistribueerde computeromgeving.
Hadoop-clusters staan ook bekend als Shared-nothing-systemen omdat er niets wordt gedeeld tussen de knooppunten in het cluster, behalve de netwerkbandbreedte. Dit vermindert de verwerkingslatentie.
Als er dus vragen moeten worden verwerkt over de enorme hoeveelheid gegevens, wordt de clusterbrede latentie geminimaliseerd.
Laten we nu de architectuur van Hadoop-cluster bestuderen.
Architectuur van Hadoop-cluster
De Hadoop Cluster volgt een meester-slaaf architectuur. Het bestaat uit de master node, slave nodes en de client node.
1. Meester in Hadoop-cluster
Master in the Hadoop Cluster is een krachtige machine met een hoge configuratie van geheugen en CPU. De twee daemons NameNode en de ResourceManager draaien op het hoofdknooppunt.
a. Functies van NameNode
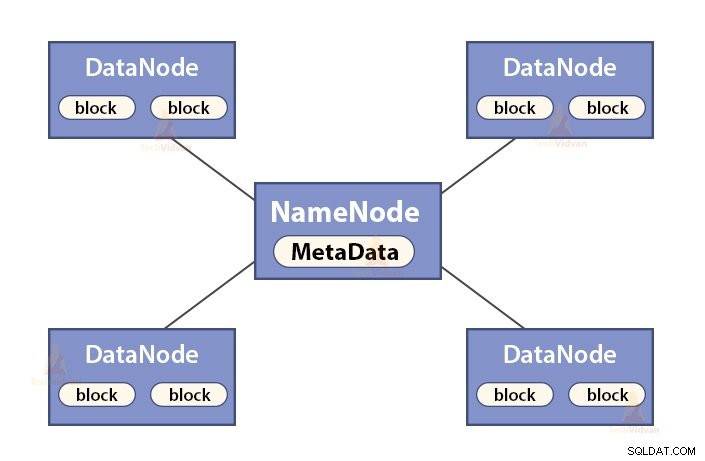
NameNode is een hoofdknooppunt in de Hadoop HDFS . NameNode beheert de naamruimte van het bestandssysteem. Het slaat metagegevens van het bestandssysteem op in het geheugen om ze snel op te halen. Daarom moet het worden geconfigureerd op geavanceerde machines.
De functies van NameNode zijn:
- Beheert de naamruimte van het bestandssysteem
- Slaat metagegevens op over blokken van een bestand, blokkeert locatie, machtigingen, enz.
- Het voert de naamruimtebewerkingen van het bestandssysteem uit, zoals openen, sluiten, hernoemen van bestanden en mappen, enz.
- Het onderhoudt en beheert de DataNode.
b. Functies van Resource Manager
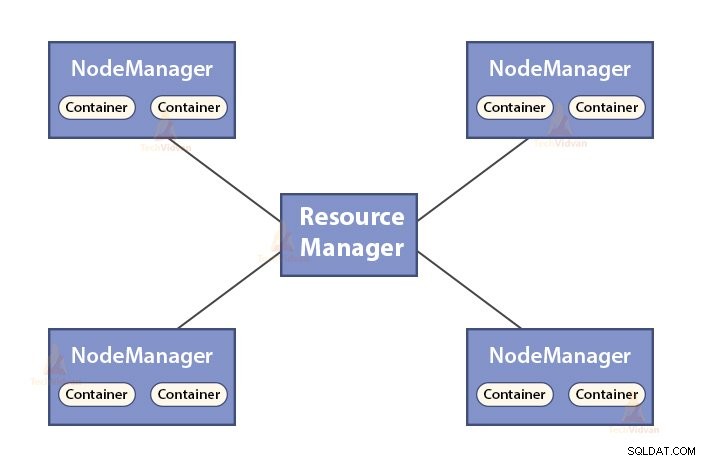
- ResourceManager is de hoofddaemon van YARN.
- De ResourceManager bemiddelt tussen alle applicaties in het systeem.
- Het houdt live en dode nodes in het cluster bij.
2. Slaven in het Hadoop-cluster
Slaven in het Hadoop-cluster zijn goedkope basishardware. De twee daemons die DataNodes zijn en de YARN NodeManagers draaien op de slave-nodes.
a. Functies van DataNodes
- DataNodes slaat de feitelijke bedrijfsgegevens op. Het slaat de blokken van een bestand op.
- Het voert blokcreatie, verwijdering en replicatie uit op basis van de instructies van NameNode.
- DataNode is verantwoordelijk voor de lees-/schrijfbewerkingen van de client.
b. Functies van NodeManager
- NodeManager is de slave-daemon van YARN.
- Het is verantwoordelijk voor containers, het monitoren van hun resourcegebruik (zoals CPU, schijf, geheugen, netwerk) en rapporteren dit aan de ResourceManager.
- De NodeManager controleert ook de gezondheid van het knooppunt waarop het draait.
3. Clientknooppunt in Hadoop-cluster
Client Nodes in Hadoop zijn geen master nodes of slave nodes. Ze hebben Hadoop erop geïnstalleerd met alle clusterinstellingen.
Functies van Client-knooppunten
- Cliëntknooppunten laden gegevens in het Hadoop-cluster.
- Het verzendt MapReduce-taken en beschrijft hoe die gegevens moeten worden verwerkt.
- Haal de resultaten van de taak op nadat de verwerking is voltooid.
We kunnen het Hadoop-cluster uitschalen door meer knooppunten toe te voegen. Dit maakt Hadoop lineair schaalbaar . Met elke toevoeging van een knooppunt krijgen we een overeenkomstige boost in doorvoer. Als we 'n' nodes hebben, dan geeft het toevoegen van 1 node (1/n) extra rekenkracht.
Single Node Hadoop Cluster VS Multi-Node Hadoop Cluster
1. Hadoop-cluster met één knooppunt
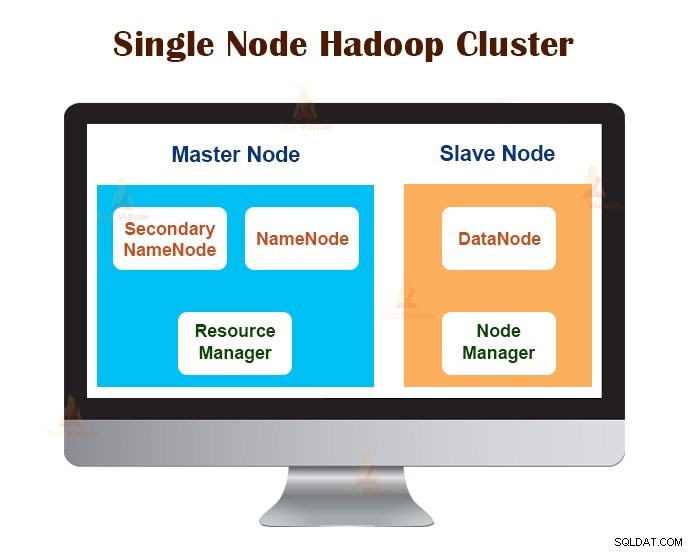
Single Node Hadoop Cluster wordt geïmplementeerd op één enkele machine. Alle daemons zoals NameNode, DataNode, ResourceManager en NodeManager draaien op dezelfde machine/host.
In een clusterconfiguratie met één knooppunt draait alles op één JVM-instantie. De Hadoop-gebruiker hoefde geen configuratie-instellingen te maken, behalve het instellen van de JAVA_HOME-variabele.
De standaard replicatiefactor voor een Hadoop-cluster met één knooppunt is altijd 1.
2. Multi-Node Hadoop-cluster
Multi-Node Hadoop Cluster wordt op meerdere machines geïmplementeerd. Alle daemons in het Hadoop-cluster met meerdere knooppunten zijn actief op verschillende machines/hosts.
Een Hadoop-cluster met meerdere knooppunten volgt de master-slave-architectuur. De daemons Namenode en ResourceManager draaien op de hoofdknooppunten, dit zijn geavanceerde computermachines.
De daemons DataNodes en NodeManagers draaien op de slave-nodes (worker-nodes), die goedkope basishardware zijn.
In het Hadoop-cluster met meerdere knooppunten kunnen slave-machines op elke locatie aanwezig zijn, ongeacht de locatie van de fysieke locatie van de masterserver.
Communicatieprotocollen gebruikt in Hadoop-cluster
De HDFS-communicatieprotocollen zijn gelaagd bovenop het TCP/IP-protocol. Een client brengt een verbinding tot stand met de NameNode via de configureerbare TCP-poort op de NameNode-machine.
Het Hadoop Cluster brengt een verbinding tot stand met de klant via het ClientProtocol. Bovendien praat de DataNode met de NameNode via het DataNode-protocol.
De Remote Procedure Call (RPC)-abstractie omvat het Client Protocol en het DataNode-protocol. Door het ontwerp initieert NameNode geen RPC's. Het reageert alleen op de RPC-verzoeken van klanten of DataNodes.
Beste praktijken voor het bouwen van Hadoop-cluster
De prestaties van een Hadoop-cluster zijn afhankelijk van verschillende factoren, gebaseerd op de goed gedimensioneerde hardwarebronnen die CPU, geheugen, netwerkbandbreedte, harde schijf en andere goed geconfigureerde softwarelagen gebruiken.
Het bouwen van een Hadoop-cluster is een niet-triviale klus. Het vereist aandacht voor verschillende factoren, zoals het kiezen van de juiste hardware, de grootte van de Hadoop-clusters en het configureren van de Hadoop-cluster.
Laten we ze nu allemaal in detail bekijken.
1. De juiste hardware kiezen voor Hadoop-cluster
Veel organisaties bevinden zich bij het opzetten van de Hadoop-infrastructuur in een hachelijke situatie, omdat ze zich niet bewust zijn van het soort machines dat ze moeten aanschaffen voor het opzetten van een geoptimaliseerde Hadoop-omgeving en de ideale configuratie die ze moeten gebruiken.
Om de juiste hardware voor het Hadoop-cluster te kiezen, moet men rekening houden met de volgende punten:
- Het gegevensvolume dat de cluster gaat verwerken.
- Het type workloads waarmee het cluster te maken krijgt (CPU-gebonden, I/O-gebonden).
- Methodologie voor gegevensopslag zoals gegevenscontainers, eventueel gebruikte technieken voor gegevenscompressie.
- Een beleid voor het bewaren van gegevens, dat wil zeggen hoe lang we de gegevens willen bewaren voordat ze worden gewist.
2. Het Hadoop-cluster dimensioneren
Voor het bepalen van de grootte van het Hadoop-cluster moet het datavolume dat de Hadoop-gebruikers zullen verwerken op het Hadoop-cluster een belangrijke overweging zijn.
Door de hoeveelheid te verwerken gegevens te kennen, helpt het bij het beslissen hoeveel knooppunten nodig zijn om de gegevens efficiënt te verwerken en geheugencapaciteit die nodig is voor elk knooppunt. Er moet een evenwicht zijn tussen de prestaties en de kosten van de goedgekeurde hardware.
3. Hadoop-cluster configureren
Het vinden van de ideale configuratie voor het Hadoop-cluster is geen gemakkelijke klus. Het Hadoop-framework moet worden aangepast aan het cluster dat wordt uitgevoerd en ook aan de taak.
De beste manier om de ideale configuratie voor het Hadoop-cluster te bepalen, is door de Hadoop-taken uit te voeren met de standaardconfiguratie die beschikbaar is om een basislijn te krijgen. Daarna kunnen we de logbestanden van de taakgeschiedenis analyseren om te zien of er een zwakte in de bronnen is of dat de tijd die nodig is om de taken uit te voeren, langer is dan verwacht.
Als dit het geval is, wijzigt u de configuratie. Door hetzelfde proces te herhalen, kan de Hadoop-clusterconfiguratie worden afgestemd op de zakelijke vereisten.
De prestaties van het Hadoop-cluster zijn sterk afhankelijk van de middelen die aan de daemons zijn toegewezen. Voor kleine tot middelgrote gegevenscontext reserveert Hadoop één CPU-kern op elke DataNode, terwijl het voor de lange datasets 2 CPU-kernen toewijst op elke DataNode voor HDFS- en MapReduce-daemons.
Hadoop-clusterbeheer
Bij het inzetten van het Hadoop-cluster in productie, is het duidelijk dat het moet schalen langs alle dimensies die volume, variëteit en snelheid zijn.
Verschillende functies die het zou moeten hebben om klaar te zijn voor productie zijn:24-uurs beschikbaarheid, robuustheid, beheersbaarheid en prestaties. Hadoop-clusterbeheer is het belangrijkste facet van het big data-initiatief.
De beste tool voor Hadoop-clusterbeheer zou de volgende kenmerken moeten hebben:-
- Het moet 24×7 hoge beschikbaarheid, resourcevoorziening, diverse beveiliging, werklastbeheer, gezondheidsmonitoring en prestatie-optimalisatie garanderen. Het moet ook taakplanning, beleidsbeheer, back-up en herstel bieden op een of meer knooppunten.
- Implementeer redundante HDFS NameNode hoge beschikbaarheid met taakverdeling, hot standbys, hersynchronisatie en auto-failover.
- Het afdwingen van op beleid gebaseerde controles die voorkomen dat een toepassing een onevenredig deel van de middelen in beslag neemt op een reeds maximaal benut Hadoop-cluster.
- Regressietesten uitvoeren voor het beheren van de implementatie van softwarelagen over Hadoop-clusters. Dit is om ervoor te zorgen dat taken of gegevens niet crashen of knelpunten tegenkomen in de dagelijkse werkzaamheden.
Voordelen van Hadoop-cluster
De verschillende voordelen van het Hadoop-cluster zijn:
1. Schaalbaar
Hadoop-clusters zijn schaalbaar. We kunnen een willekeurig aantal nodes aan het Hadoop-cluster toevoegen zonder enige downtime en zonder extra inspanningen. Met elke toevoeging van een knoop krijgen we een overeenkomstige boost in doorvoer.
2. Robuustheid
Het Hadoop Cluster staat vooral bekend om zijn betrouwbare opslag. Het kan gegevens betrouwbaar opslaan, zelfs in gevallen zoals DataNode-fout, NameNode-fout en netwerkpartitie. De DataNode stuurt periodiek een hartslagsignaal naar de NameNode.
In netwerkpartitie wordt een set DataNodes losgekoppeld van de NameNode waardoor NameNode geen hartslag ontvangt van deze DataNodes. NameNode beschouwt deze DataNodes dan als dood en stuurt geen I/O-verzoeken naar hen door.
Ook valt de replicatiefactor van de blokken die zijn opgeslagen in deze DataNodes onder hun opgegeven waarde. Als resultaat initieert NameNode vervolgens de replicatie van deze blokken en herstelt het van de storing.
3. Cluster opnieuw in evenwicht brengen
De Hadoop HDFS-architectuur voert automatisch clusterherbalancering uit. Als de vrije ruimte in de DataNode onder het drempelniveau valt, verplaatst de HDFS-architectuur automatisch enkele gegevens naar andere DataNode waar voldoende ruimte beschikbaar is.
4. Kosteneffectief
Het opzetten van het Hadoop-cluster is kosteneffectief omdat het goedkope standaardhardware omvat. Elke organisatie kan eenvoudig een krachtig Hadoop-cluster opzetten zonder veel uit te geven aan dure serverhardware.
Bovendien overwinnen Hadoop Clusters met zijn gedistribueerde opslagtopologie de beperkingen van het traditionele systeem. De beperkte opslagruimte kan worden uitgebreid door eenvoudig extra goedkope opslageenheden aan het systeem toe te voegen.
5. Flexibel
Hadoop-clusters zijn zeer flexibel omdat ze gegevens van elk type kunnen verwerken, gestructureerd, semi-gestructureerd of ongestructureerd en van elke grootte, variërend van gigabytes tot petabytes.
6. Snelle verwerking
In Hadoop Cluster kunnen gegevens parallel worden verwerkt in een gedistribueerde omgeving. Dit biedt snelle gegevensverwerkingsmogelijkheden voor Hadoop. Hadoop-clusters kunnen binnen een fractie van seconden Terabytes of Petabytes aan gegevens verwerken.
7. Gegevensintegriteit
Om te controleren op corruptie in gegevensblokken als gevolg van software met fouten, fouten in een opslagapparaat, enz. implementeert het Hadoop-cluster een controlesom op elk blok van het bestand. Als het een beschadigd blok vindt, zoekt het het uit een andere DataNode die de replica van hetzelfde blok bevat. Zo behoudt het Hadoop-cluster de gegevensintegriteit.
Samenvatting
Na het lezen van dit artikel kunnen we stellen dat het Hadoop-cluster een speciaal rekencluster is dat is ontworpen voor het analyseren en opslaan van big data. Hadoop Cluster volgt master-slave-architectuur.
Het hoofdknooppunt is de geavanceerde computermachine en de slaafknooppunten zijn machines met een normale CPU- en geheugenconfiguratie. We hebben ook gezien dat de Hadoop-cluster kan worden ingesteld op een enkele machine genaamd Hadoop-cluster met één knooppunt of op meerdere machines die Hadoop-cluster met meerdere knooppunten wordt genoemd.
In dit artikel hebben we ook de best practices behandeld die moeten worden gevolgd bij het bouwen van een Hadoop-cluster. We hadden ook veel voordelen van het Hadoop-cluster gezien, waaronder schaalbaarheid, flexibiliteit, kosteneffectiviteit, enz.