Deze blogpost is een voortzetting van het vorige deel 1, waar we de basisprincipes van SNMP-integratie met ClusterControl hebben behandeld.
In deze blogpost gaan we ons concentreren op SNMP-traps en waarschuwingen. SNMP-traps zijn de meest gebruikte waarschuwingsberichten die worden verzonden vanaf een extern SNMP-apparaat (een agent) naar een centrale collector, de "SNMP-manager". In het geval van ClusterControl kan een trap een waarschuwing zijn nadat het kritieke alarm voor een cluster niet 0 is, wat aangeeft dat er iets ergs aan de hand is.
Zoals getoond in de vorige blogpost, hebben we voor deze proof-of-concept twee definities van SNMP trap-meldingen:
criticalAlarmNotification NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification if critical alarm is not 0"
::= { alarmNotification 1 }
criticalAlarmNotificationEnded NOTIFICATION-TYPE
OBJECTS { totalCritical, clusterId }
STATUS current
DESCRIPTION
"Notification ended - Critical alarm is 0"
::= { alarmNotification 2 }De meldingen (of traps) zijn criticalAlarmNotification en criticalAlarmNotificationEnded. Beide meldingsgebeurtenissen kunnen worden gebruikt om onze Nagios-service te signaleren, ongeacht of het cluster actief kritieke alarmen heeft of niet. In Nagios is de term hiervoor passieve controle, waarbij Nagios niet probeert te bepalen of host/service DOWN of ONREACHBAAR is. We zullen ook de actieve controles configureren, waarbij controles worden gestart door de controlelogica in de Nagios-daemon door de servicedefinitie te gebruiken om ook de kritieke/waarschuwingsalarmen te bewaken die door ons cluster worden gerapporteerd.
Houd er rekening mee dat voor deze blogpost de MIB- en SNMP-agent van Meerderenines correct moeten zijn geconfigureerd, zoals weergegeven in het eerste deel van deze blogserie.
Nagios Core installeren
Nagios Core is de gratis versie van de Nagios-bewakingssuite. Eerst en vooral moeten we het en alle benodigde pakketten installeren, gevolgd door de Nagios-plug-ins, snmptrapd en snmptt. Houd er rekening mee dat de instructies in deze blogpost ervan uitgaan dat alle knooppunten op CentOS 7 draaien.
Installeer de benodigde pakketten om Nagios uit te voeren:
$ yum -y install httpd php gcc glibc glibc-common wget perl gd gd-devel unzip zip sendmail net-snmp-utils net-snmp-perlMaak een nagios-gebruiker en nagcmd-groep om de externe opdrachten via de webinterface te laten uitvoeren, voeg de nagios- en apache-gebruiker toe om deel uit te maken van de nagcmd-groep:
$ useradd nagios
$ groupadd nagcmd
$ usermod -a -G nagcmd nagios
$ usermod -a -G nagcmd apacheDownload hier de nieuwste versie van Nagios Core, compileer en installeer deze:
$ cd ~
$ wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.6.tar.gz
$ tar -zxvf nagios-4.4.6.tar.gz
$ cd nagios-4.4.6
$ ./configure --with-nagios-group=nagios --with-command-group=nagcmd
$ make all
$ make install
$ make install-init
$ make install-config
$ make install-commandmodeInstalleer de Nagios-webconfiguratie:
$ make install-webconfInstalleer optioneel het Nagios-exfoliatiethema (of je kunt je aan het standaardthema houden):
$ make install-exfoliationMaak een gebruikersaccount (nagiosadmin) om in te loggen op de Nagios-webinterface. Onthoud het wachtwoord dat u aan deze gebruiker toewijst:
$ htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminHerstart de Apache-webserver om de nieuwe instellingen van kracht te laten worden:
$ systemctl restart httpd
$ systemctl enable httpdDownload de Nagios-plug-ins van hier, compileer en installeer deze:
$ cd ~
$ wget https://nagios-plugins.org/download/nagios-plugins-2.3.3.tar.gz
$ tar -zxvf nagios-plugins-2.3.3.tar.gz
$ cd nagios-plugins-2.3.3
$ ./configure --with-nagios-user=nagios --with-nagios-group=nagios
$ make
$ make installControleer de standaard Nagios-configuratiebestanden:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
Nagios Core 4.4.6
Copyright (c) 2009-present Nagios Core Development Team and Community Contributors
Copyright (c) 1999-2009 Ethan Galstad
Last Modified: 2020-04-28
License: GPL
Website: https://www.nagios.org
Reading configuration data...
Read main config file okay...
Read object config files okay...
Running pre-flight check on configuration data...
Checking objects...
Checked 8 services.
Checked 1 hosts.
Checked 1 host groups.
Checked 0 service groups.
Checked 1 contacts.
Checked 1 contact groups.
Checked 24 commands.
Checked 5 time periods.
Checked 0 host escalations.
Checked 0 service escalations.
Checking for circular paths...
Checked 1 hosts
Checked 0 service dependencies
Checked 0 host dependencies
Checked 5 timeperiods
Checking global event handlers...
Checking obsessive compulsive processor commands...
Checking misc settings...
Total Warnings: 0
Total Errors: 0
Things look okay - No serious problems were detected during the pre-flight check
If everything looks okay, start Nagios and configure it to start on boot:
$ systemctl start nagios
$ systemctl enable nagiosOpen de browser en ga naar https://{IPaddress}/nagios en u zou een HTTP-basisverificatie moeten zien verschijnen waarin u de gebruikersnaam als nagiosadmin moet specificeren met het eerder gemaakte wachtwoord van uw keuze.
ClusterControl-server toevoegen aan Nagios
Maak een Nagios-hostdefinitiebestand voor ClusterControl:
$ vim /usr/local/nagios/etc/objects/clustercontrol.cfgEn voeg de volgende regels toe:
define host {
use linux-server
host_name clustercontrol.local
alias clustercontrol.mydomain.org
address 192.168.10.50
}
define service {
use generic-service
host_name clustercontrol.local
service_description Critical alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.2 -c0
}
define service {
use generic-service
host_name clustercontrol.local
service_description Warning alarms - ClusterID 23
check_command check_snmp! -H 192.168.10.50 -P 2c -C private -o .1.3.6.1.4.1.57397.1.1.1.3 -w0
}
define service {
use snmp_trap_template
host_name clustercontrol.local
service_description Critical alarm traps
check_interval 60 ; Don't clear for 1 hour
}
Enkele uitleg:
-
In de eerste sectie definiëren we onze host, met de hostnaam en het adres van de ClusterControl-server.
-
De servicesecties waar we onze servicedefinities plaatsen, worden gecontroleerd door de Nagios. De eerste twee vertellen de service in feite om de SNMP-uitvoer te controleren op een bepaald object-ID. De eerste service gaat over het kritieke alarm, daarom voegen we -c0 toe aan de opdracht check_snmp om aan te geven dat het een kritieke waarschuwing zou moeten zijn in Nagios als de waarde hoger is dan 0. Terwijl we voor de waarschuwingsalarmen dit aangeven met een waarschuwing als de waarde is 1 en hoger.
-
De laatste servicedefinitie gaat over de SNMP-traps die we zouden verwachten van de ClusterControl-server als het kritieke alarm verhoogd is hoger dan 0. Deze sectie gebruikt de snmp_trap_template-definitie, zoals weergegeven in de volgende stap.
Configureer de snmp_trap_template door de volgende regels toe te voegen aan /usr/local/nagios/etc/objects/templates.cfg:
define service {
name snmp_trap_template
service_description SNMP Trap Template
active_checks_enabled 1 ; Active service checks are enabled
passive_checks_enabled 1 ; Passive service checks are enabled/accepted
parallelize_check 1 ; Active service checks should be parallelized
process_perf_data 0
obsess_over_service 0 ; We should obsess over this service (if necessary)
check_freshness 0 ; Default is to NOT check service 'freshness'
notifications_enabled 1 ; Service notifications are enabled
event_handler_enabled 1 ; Service event handler is enabled
flap_detection_enabled 1 ; Flap detection is enabled
process_perf_data 1 ; Process performance data
retain_status_information 1 ; Retain status information across program restarts
retain_nonstatus_information 1 ; Retain non-status information across program restarts
check_command check-host-alive ; This will be used to reset the service to "OK"
is_volatile 1
check_period 24x7
max_check_attempts 1
normal_check_interval 1
retry_check_interval 1
notification_interval 60
notification_period 24x7
notification_options w,u,c,r
contact_groups admins ; Modify this to match your Nagios contactgroup definitions
register 0
}
Voeg het ClusterControl-configuratiebestand toe aan Nagios door de volgende regel toe te voegen aan
/usr/local/nagios/etc/nagios.cfg:
cfg_file=/usr/local/nagios/etc/objects/clustercontrol.cfgVoer een pre-flight configuratiecontrole uit:
$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgZorg ervoor dat u de volgende regel aan het einde van de uitvoer krijgt:
"Things look okay - No serious problems were detected during the pre-flight check"Start Nagios opnieuw om de wijziging te laden:
$ systemctl restart nagiosAls we nu naar de Nagios-pagina onder het gedeelte Service (menu aan de linkerkant) kijken, zien we zoiets als dit:
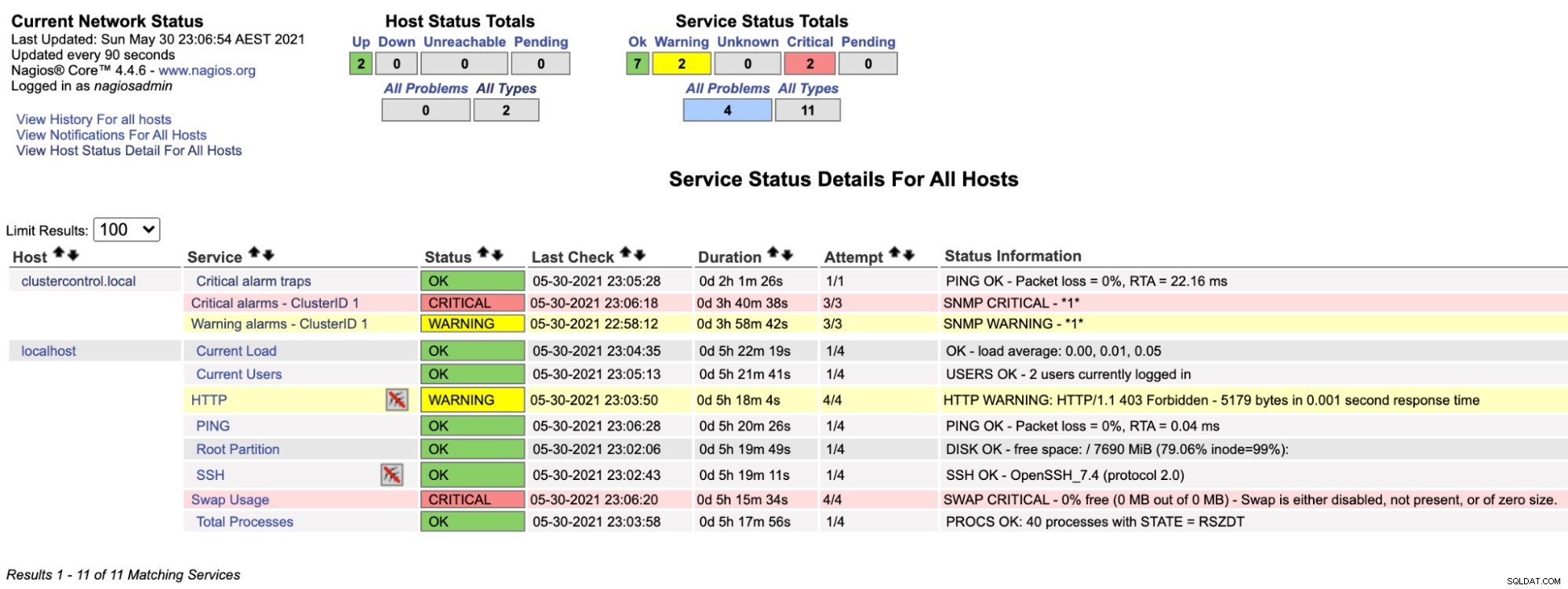
Merk op dat de rij "Kritieke alarmen - ClusterID 1" rood wordt als de door ClusterControl gerapporteerde kritieke alarmwaarde groter is dan 0, terwijl de rij "Waarschuwingsalarmen - ClusterID 1" geel is, wat aangeeft dat er een waarschuwingsalarm is gegenereerd. Als er niets interessants gebeurt, ziet u dat alles groen is voor clustercontrol.local.
Nagios configureren om een valstrik te ontvangen
Traps worden door externe apparaten naar de Nagios-server gestuurd, dit wordt een passieve controle genoemd. In het ideale geval weten we niet wanneer een trap wordt verzonden, omdat het afhangt van het verzendende apparaat dat beslist dat het een trap zal sturen. Bijvoorbeeld met een UPS (back-up batterij), zodra het apparaat stroom verliest, zal het een val sturen om te zeggen "hey, ik verloor stroom". Zo is Nagios direct op de hoogte.
Om SNMP-traps te kunnen ontvangen, moeten we de Nagios-server configureren met de volgende dingen:
-
snmptrapd (SNMP trap-ontvanger-daemon)
-
snmptt (SNMP Trap Translator, de trap-handler-daemon)
Nadat de snmptrapd een trap heeft ontvangen, zal deze deze doorgeven aan snmptt waar we hem zullen configureren om het Nagios-systeem bij te werken en vervolgens zal Nagios de waarschuwing verzenden volgens de configuratie van de contactgroep.
Installeer EPEL-repository, gevolgd door de benodigde pakketten:
$ yum -y install epel-release
$ yum -y install net-snmp snmptt net-snmp-perl perl-Sys-SyslogConfigureer de SNMP trap-daemon op /etc/snmp/snmptrapd.conf en stel de volgende regels in:
disableAuthorization yes
traphandle default /usr/sbin/snmptthandlerHet bovenstaande betekent eenvoudigweg dat vallen die door de snmptrapd-daemon worden ontvangen, worden doorgegeven aan /usr/sbin/snmptthandler.
Voeg de SEVERALNINES-CLUSTERCONTROL-MIB.txt toe aan /usr/share/snmp/mibs door /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt te maken:
$ ll /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt
-rw-r--r-- 1 root root 4029 May 30 20:08 /usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txtMaak /etc/snmp/snmp.conf (let op zonder de "d") en voeg daar onze aangepaste MIB toe:
mibs +SEVERALNINES-CLUSTERCONTROL-MIBStart de snmptrapd-service:
$ systemctl start snmptrapd
$ systemctl enable snmptrapdVervolgens moeten we de volgende configuratieregels configureren in /etc/snmp/snmptt.ini:
net_snmp_perl_enable = 1
snmptt_conf_files = <<END
/etc/snmp/snmptt.conf
/etc/snmp/snmptt-cc.conf
ENDMerk op dat we de module net_snmp_perl hebben ingeschakeld en een ander configuratiepad hebben toegevoegd, /etc/snmp/snmptt-cc.conf binnen snmptt.ini. We moeten ClusterControl snmptt-gebeurtenissen hier definiëren, zodat ze kunnen worden doorgegeven aan Nagios. Maak een nieuw bestand in /etc/snmp/snmptt-cc.conf en voeg de volgende regels toe:
MIB: SEVERALNINES-CLUSTERCONTROL-MIB (file:/usr/share/snmp/mibs/SEVERALNINES-CLUSTERCONTROL-MIB.txt) converted on Sun May 30 19:17:33 2021 using snmpttconvertmib v1.4.2
EVENT criticalAlarmNotification .1.3.6.1.4.1.57397.1.1.3.1 "Status Events" Critical
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 2 "Critical - Critical alarm is $1 for cluster ID $2"
SDESC
Notification if critical alarm is not 0
Variables:
1: totalCritical
2: clusterId
EDESC
EVENT criticalAlarmNotificationEnded .1.3.6.1.4.1.57397.1.1.3.2 "Status Events" Normal
FORMAT Notification if the critical alarm is not 0
EXEC /usr/local/nagios/share/eventhandlers/submit_check_result $aA "Critical alarm traps" 0 "Normal - Critical alarm is $1 for cluster ID $2"
SDESC
Notification ended - critical alarm is 0
Variables:
1: totalCritical
2: clusterId
EDESCEnkele uitleg:
-
We hebben twee vallen gedefinieerd:criticalAlarmNotification en criticalAlarmNotificationEnded.
-
De criticalAlarmNotification genereert eenvoudig een kritieke waarschuwing en geeft deze door aan de "Critical alarm traps"-service die is gedefinieerd in Nagios. De $aA betekent om het IP-adres van de trap-agent te retourneren. De waarde 2 is de waarde van het controleresultaat die in dit geval kritiek is (0=OK, 1=WAARSCHUWING, 2=KRITIEK, 3=ONBEKEND).
-
CriticalAlarmNotificationEnded geeft eenvoudig een OK-waarschuwing en geeft deze door aan de service "Critical alarm traps" om de vorige val nadat alles weer normaal is geworden. De $aA betekent om het IP-adres van de trap-agent te retourneren. De waarde 0 is de waarde van het controleresultaat die in dit geval OK is. Raadpleeg dit artikel onder de sectie "FORMAT" voor meer informatie over tekenreeksvervangingen die worden herkend door snmptt.
-
U kunt snmpttconvertmib gebruiken om een snmptt-gebeurtenishandlerbestand voor een bepaalde MIB te genereren.
Merk op dat het pad van de eventhandlers standaard niet wordt geleverd door de Nagios Core. Daarom moeten we die eventhandlers-map kopiëren van de Nagios-bron onder de contrib-map, zoals hieronder weergegeven:
$ cp -Rf nagios-4.4.6/contrib/eventhandlers /usr/local/nagios/share/
$ chown -Rf nagios:nagios /usr/local/nagios/share/eventhandlersWe moeten ook de snmptt-groep toewijzen als onderdeel van de nagcmd-groep, zodat het de nagios.cmd kan uitvoeren in het submit_check_result-script:
$ usermod -a -G nagcmd snmpttStart de snmptt-service:
$ systemctl start snmptt
$ systemctl enable snmpttDe SNMP Manager (Nagios-server) is nu klaar om onze inkomende SNMP-traps te accepteren en te verwerken.
Een trap verzenden vanaf de ClusterControl-server
Stel dat men een SNMP-trap naar de SNMP-manager, 192.168.10.11 (Nagios-server) wil sturen omdat het totale aantal kritieke alarmen 2 heeft bereikt voor cluster-ID 1, dan zou men de volgende opdracht uitvoeren op de ClusterControl-server (client-side), 192.168.10.50:
$ snmptrap -v2c -c private 192.168.10.11 '' SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification \
SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical i 2 \
SEVERALNINES-CLUSTERCONTROL-MIB::clusterId i 1Of, in OID-formaat (aanbevolen):
$ snmptrap -v2c -c private 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.1 \
.1.3.6.1.4.1.57397.1.1.1.2 i 2 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Waarbij .1.3.6.1.4.1.57397.1.1.3.1 gelijk is aan criticalAlarmNotification trap-gebeurtenis, en de daaropvolgende OID's representaties zijn van respectievelijk het totale aantal huidige kritieke alarmen en de cluster-ID .
Op de Nagios-server zou je moeten opmerken dat de trap-service rood is geworden:
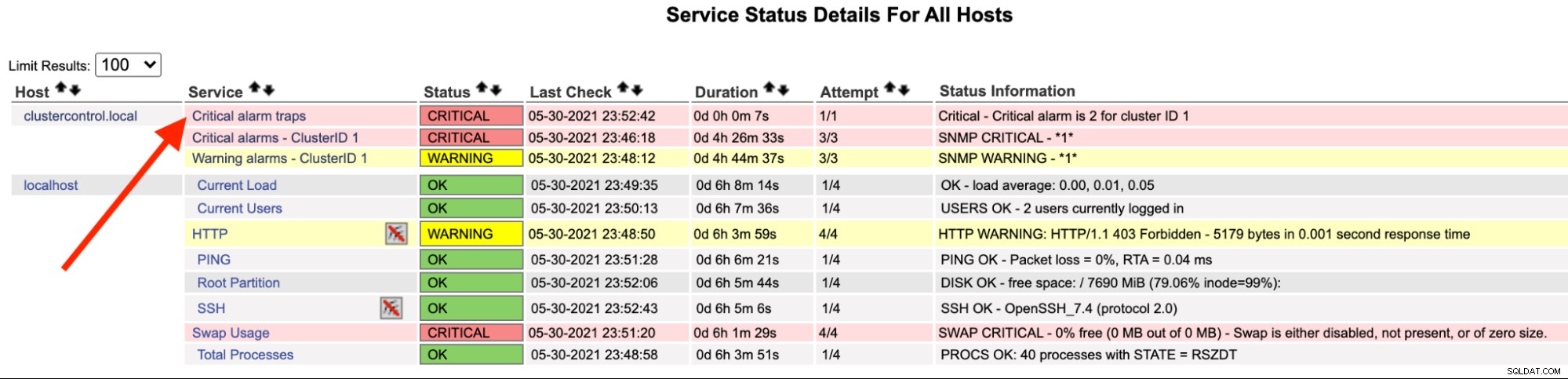
Je kunt het ook zien in de /var/log/messages van de volgende regel:
May 30 23:52:39 ip-10-15-2-148 snmptrapd[27080]: 2021-05-30 23:52:39 UDP: [192.168.10.50]:33151->[192.168.10.11]:162 [UDP: [192.168.10.50]:33151->[192.168.10.11]:162]:#012DISMAN-EVENT-MIB::sysUpTimeInstance = Timeticks: (2423020) 6:43:50.20#011SNMPv2-MIB::snmpTrapOID.0 = OID: SEVERALNINES-CLUSTERCONTROL-MIB::criticalAlarmNotification#011SEVERALNINES-CLUSTERCONTROL-MIB::totalCritical = INTEGER: 2#011SEVERALNINES-CLUSTERCONTROL-MIB::clusterId = INTEGER: 1
May 30 23:52:42 nagios.local snmptt[29557]: .1.3.6.1.4.1.57397.1.1.3.1 Critical "Status Events" UDP192.168.10.5033151-192.168.10.11162 - Notification if critical alarm is not 0
May 30 23:52:42 nagios.local nagios: EXTERNAL COMMAND: PROCESS_SERVICE_CHECK_RESULT;192.168.10.50;Critical alarm traps;2;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: PASSIVE SERVICE CHECK: clustercontrol.local;Critical alarm traps;0;PING OK - Packet loss = 0%, RTA = 22.16 ms
May 30 23:52:42 nagios.local nagios: SERVICE NOTIFICATION: nagiosadmin;clustercontrol.local;Critical alarm traps;CRITICAL;notify-service-by-email;Critical - Critical alarm is 2 for cluster ID 1
May 30 23:52:42 nagios.local nagios: SERVICE ALERT: clustercontrol.local;Critical alarm traps;CRITICAL;HARD;1;Critical - Critical alarm is 2 for cluster ID 1Zodra het alarm is opgelost, kunnen we, om een normale trap te sturen, het volgende commando uitvoeren:
$ snmptrap -c private -v2c 192.168.10.11 '' .1.3.6.1.4.1.57397.1.1.3.2 \
.1.3.6.1.4.1.57397.1.1.1.2 i 0 \
.1.3.6.1.4.1.57397.1.1.1.4 i 1Waarbij .1.3.6.1.4.1.57397.1.1.3.2 gelijk is aan de gebeurtenis criticalAlarmNotificationEnded, en de daaropvolgende OID's representaties zijn van het totale aantal huidige kritieke alarmen (moet in dit geval 0 zijn ) en de cluster-ID, respectievelijk.
Op de Nagios-server zou je moeten zien dat de trap-service weer groen is:
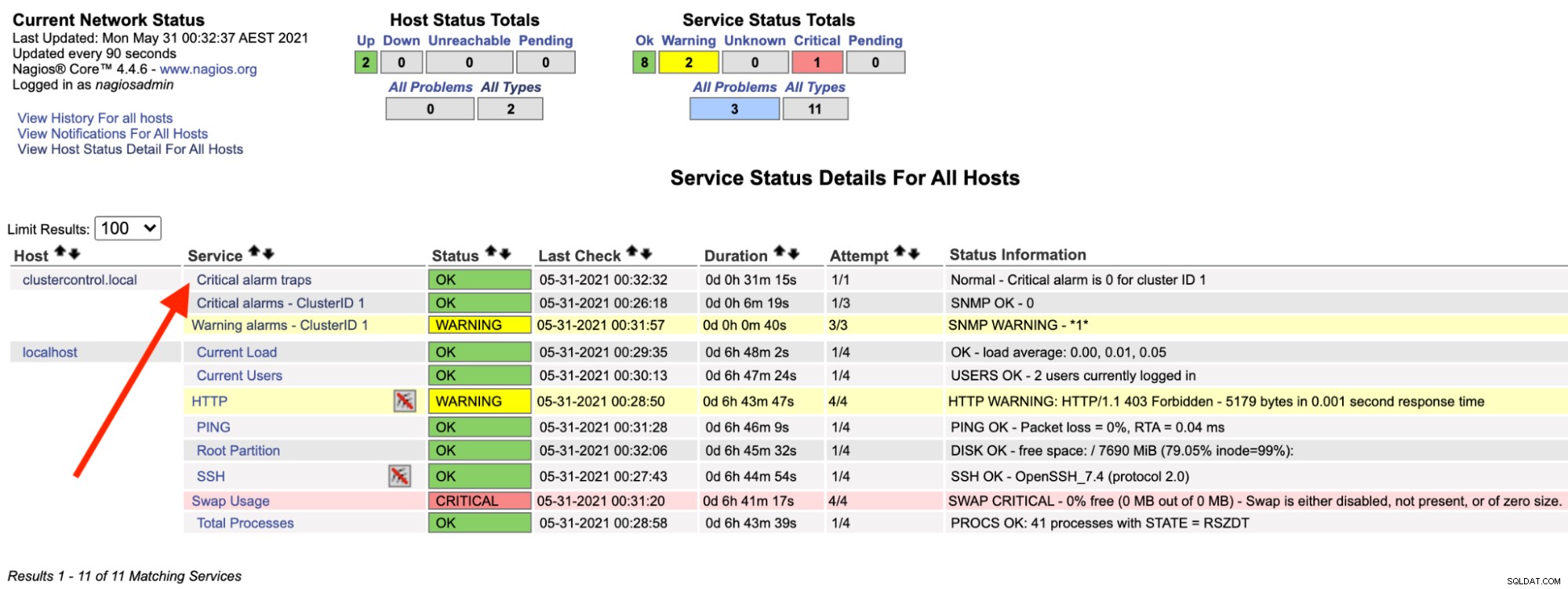
Het bovenstaande kan worden geautomatiseerd met een eenvoudig bash-script:
#!/bin/bash
# alarmtrapper.bash - SNMP trapper for ClusterControl alarms
CLUSTER_ID=1
SNMP_MANAGER=192.168.10.11
INTERVAL=10
send_critical_snmp_trap() {
# send critical trap
local val=$1
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.1 .1.3.6.1.4.1.57397.1.1.1.1 i ${val} .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
send_zero_critical_snmp_trap() {
# send OK trap
snmptrap -v2c -c private ${SNMP_MANAGER} '' .1.3.6.1.4.1.57397.1.1.3.2 .1.3.6.1.4.1.57397.1.1.1.1 i 0 .1.3.6.1.4.1.57397.1.1.1.4 i ${CLUSTER_ID}
}
while true; do
count=$(s9s alarm --list --long --cluster-id=${CLUSTER_ID} --batch | grep CRITICAL | wc -l)
[ $count -ne 0 ] && send_critical_snmp_trap $count || send_zero_critical_snmp_trap
sleep $INTERVAL
doneAls u het script op de achtergrond wilt uitvoeren, doet u het volgende:
$ bash alarmtrapper.bash &Op dit moment zouden we Nagios' service "Critical alarm traps" in actie moeten kunnen zien als er automatisch een storing in ons cluster optreedt.
Laatste gedachten
In deze blogserie hebben we een proof-of-concept laten zien van hoe ClusterControl kan worden geconfigureerd voor monitoring, het genereren/verwerken van traps en waarschuwingen met behulp van het SNMP-protocol. Dit markeert ook het begin van onze reis om SNMP op te nemen in onze toekomstige releases. Houd ons in de gaten, want we zullen meer updates brengen over deze geweldige functie.