In deze blog geven we je de volledige introductie van Hadoop Mapper . ik
In deze blog zullen we antwoorden op wat Mapper is in Hadoop MapReduce, hoe hadoop mapper werkt, wat het proces van mapper in Mapreduce is, hoe Hadoop een sleutel-waardepaar genereert in MapReduce.
Inleiding tot Hadoop Mapper
Hadoop Mapper verwerkt invoerrecord geproduceerd door de RecordReader en genereert tussenliggende sleutel-waardeparen. De tussenuitgang is compleet anders dan het ingangspaar.
De uitvoer van de mapper is de volledige verzameling sleutel-waardeparen. Alvorens de uitvoer voor elke mappertaak te schrijven, vindt partitionering van de uitvoer plaats op basis van de sleutel. Dus partitionering specificeert dat alle waarden voor elke sleutel bij elkaar zijn gegroepeerd.
Hadoop MapReduce genereert één kaarttaak voor elke InputSplit.
Hadoop MapReduce begrijpt alleen sleutel-waardeparen van gegevens. Dus voordat gegevens naar de mapper worden verzonden, moet het Hadoop-framework gegevens verbergen in het sleutel-waardepaar.
Hoe wordt een sleutel/waarde-paar gegenereerd in Hadoop?
Omdat we hebben begrepen wat mapper is in hadoop, zullen we nu bespreken hoe Hadoop een sleutel-waardepaar genereert?
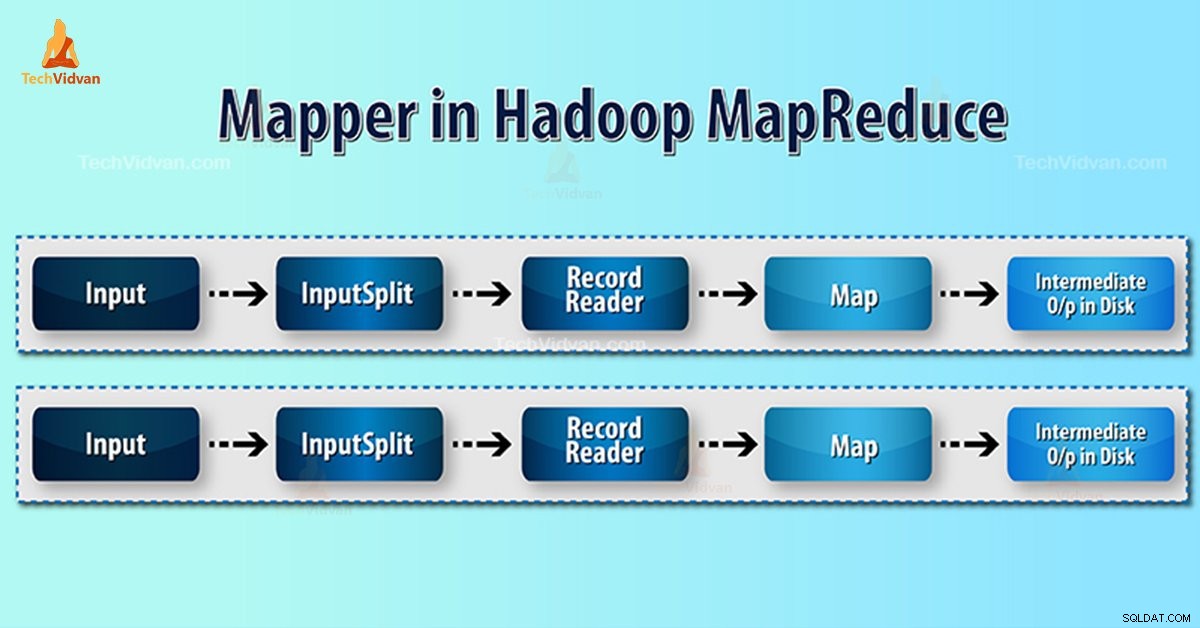
- InputSplit – Het is de logische weergave van gegevens die zijn gegenereerd door het InputFormat. In het MapReduce-programma beschrijft het een werkeenheid die een enkele kaarttaak bevat.
- RecordReader- Het communiceert met de inputSplit. En zet de gegevens vervolgens om in sleutel-waardeparen die geschikt zijn om door de Mapper te worden gelezen. RecordReader gebruikt standaard TextInputFormat om gegevens om te zetten in het sleutel-waardepaar.
Mapper-proces in Hadoop MapReduce
InputSplit zet de fysieke weergave van de blokken om in logisch voor de Mapper. Om bijvoorbeeld het bestand van 100 MB te lezen, heeft het 2 InputSplit nodig. Voor elk blok creëert het framework één InputSplit. Elke InputSplit maakt één mapper.
MapReduce InputSplit is niet altijd afhankelijk van het aantal datablokken . We kunnen het nummer van een splitsing wijzigen door de eigenschap mapred.max.split.size in te stellen tijdens het uitvoeren van de taak.
MapReduce RecordReader is verantwoordelijk voor het lezen/converteren van gegevens in sleutel-waardeparen tot het einde van het bestand. RecordReader wijst Byte-offset toe aan elke regel in het bestand.
Vervolgens ontvangt Mapper dit sleutelpaar. Mapper produceert de tussenliggende output (sleutel-waardeparen die begrijpelijk zijn te verminderen).
Hoeveel kaarttaken in Hadoop?
Het aantal kaarttaken hangt af van het totale aantal blokken van de invoerbestanden. In MapReduce-kaart lijkt het juiste niveau van parallellisme ongeveer 10-100 kaarten / knooppunt te zijn. Maar er zijn 300 kaarten voor CPU-lichtkaarttaken.
We hebben bijvoorbeeld een blokgrootte van 128 MB. En we verwachten 10 TB aan invoergegevens. Zo produceert het 82.000 kaarten. Het aantal kaarten hangt dus af van InputFormat.
Mapper =(totale gegevensgrootte)/ (gesplitste invoergrootte)
Voorbeeld – gegevensgrootte is 1 TB. Gesplitste invoergrootte is 100 MB.
Mapper =(1000*1000)/100 =10.000
Conclusie
Daarom neemt Mapper in Hadoop een set gegevens en converteert deze naar een andere set gegevens. Het verdeelt dus individuele elementen in tuples (sleutel/waarde-paren).
Ik hoop dat je dit blok leuk vindt, als je een vraag hebt over Hadoop-mapper, laat dan een reactie achter in een gedeelte hieronder. We lossen ze graag op.