Tot nu toe hebben we de Hadoop-introductie behandeld en Hadoop HDFS in detail. In deze tutorial geven we je een gedetailleerde beschrijving van Hadoop Reducer.
Hier wordt besproken wat Reducer is in MapReduce, hoe Reducer werkt in Hadoop MapReduce, verschillende fasen van Hadoop Reducer en hoe we het aantal Reducer in Hadoop MapReduce kunnen veranderen.
Wat is Hadoop Reducer?
Verloopstuk in Hadoop reduceert MapReduce een reeks tussenliggende waarden die een sleutel delen tot een kleinere reeks waarden.
In de MapReduce-taakuitvoeringsstroom neemt Reducer een set van een tussenliggend sleutelwaardepaar geproduceerd door de mapper als de ingang. Vervolgens verzamelt, filtert en combineert Reducer sleutel-waardeparen en dit vereist een breed scala aan verwerkingen.
Een-een-toewijzing vindt plaats tussen sleutels en reducers in MapReduce-taakuitvoering. Ze lopen parallel omdat ze onafhankelijk van elkaar zijn. De gebruiker bepaalt het aantal verloopstukken in MapReduce.
Fasen van Hadoop Reducer
Drie fasen van Reducer zijn als volgt:
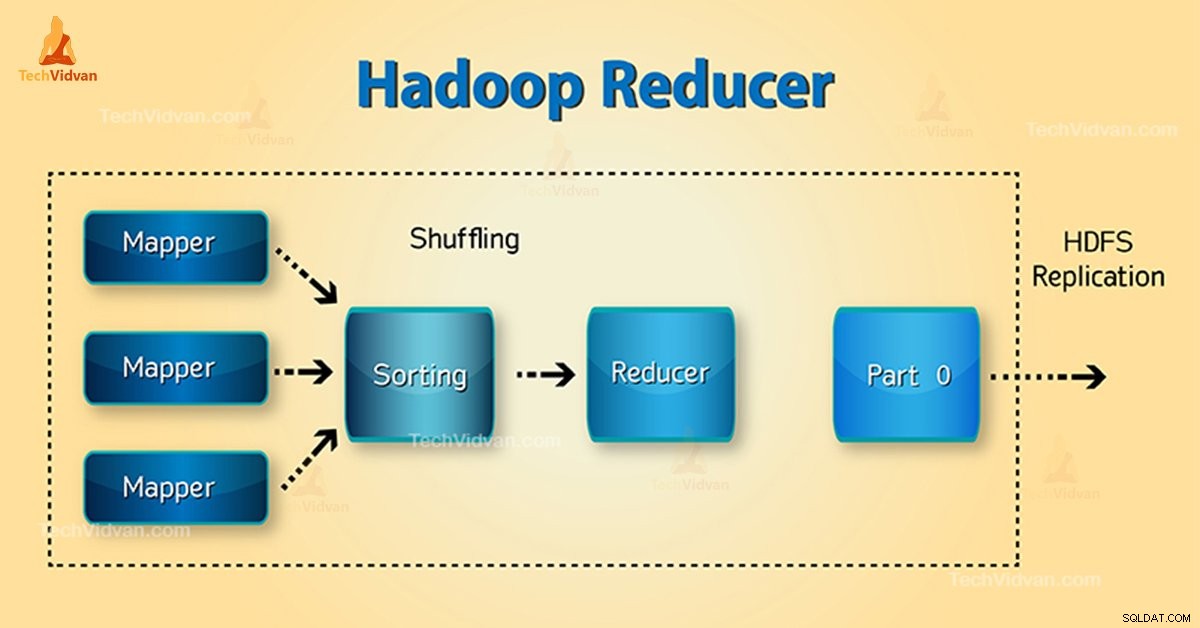
1. Shuffle-fase
Dit is de fase waarin de gesorteerde output van de mapper de input is voor de reducer. Het framework haalt met behulp van HTTP de relevante partitie van de output van alle mappers in deze fase.Sorteerfase
2. Sorteerfase
Dit is de fase waarin de invoer van verschillende mappers opnieuw wordt gesorteerd op basis van de vergelijkbare sleutels in verschillende mappers.
Zowel Shuffle als Sorteren vinden gelijktijdig plaats.
3. Fase verkleinen
Deze fase vindt plaats na het schudden en sorteren. Taak verkleinen aggregeert de sleutel-waardeparen. Met de OutputCollector.collect() eigenschap, wordt de uitvoer van de taak verkleinen naar het bestandssysteem geschreven. De output van de reducer is niet gesorteerd.
Aantal reducers in Hadoop MapReduce
Gebruiker stelt het aantal reducers in met behulp van Job.setNumreduceTasks(int) eigendom. Dus het juiste aantal verloopstukken volgens de formule:
0,95 of 1,75 vermenigvuldigd met (
Dus met 0,95 worden alle verloopstukken onmiddellijk gelanceerd. Begin dan met het overzetten van kaartuitvoer zodra de kaarten klaar zijn.
Faster node beëindigt de eerste ronde van verloopstukken met 1,75. Dan lanceert het de tweede golf van reducer die veel beter werk doet bij load balancing.
Met de toename van het aantal verloopstukken:
- De overhead van het kader neemt toe.
- Loadbalancering neemt toe.
- Kosten van storingen nemen af.
Conclusie
Daarom neemt Reducer de uitvoer van mappers als invoer. Verwerk vervolgens de sleutel-waardeparen en produceer de uitvoer. De output van de reducer is de uiteindelijke output. Als je deze blog leuk vindt of als je een vraag hebt over Hadoop Reducer, deel deze dan met ons door een reactie achter te laten.
Ik hoop dat we je kunnen helpen.