In deze Hadoop-zelfstudie , zullen we u een gedetailleerde beschrijving van Hadoop Combiner geven. Allereerst zullen we zien wat MapReduce Combiner is, wat de sleutelrol is van Combiner in MapReduce.
Daarna bespreken we het voorbeeld van het MapReduce-programma met en zonder combiner in Hadoop. Ten slotte zullen we ook enkele voor- en nadelen van Combiner in MapReduce zien.
Wat is Hadoop Combiner?
Combiner is ook bekend als "Mini-Reducer ” dat de Mapper . samenvat uitvoer record met dezelfde sleutel voordat u deze doorgeeft aan de Reducer .
Op een grote dataset wanneer we MapReduce-taak uitvoeren. Mapper genereert dus grote brokken intermediaire gegevens. Vervolgens geeft het framework deze tussentijdse gegevens door aan de Reducer voor verdere verwerking.
Dit leidt tot enorme netwerkcongestie. Het Hadoop-framework biedt een functie die bekend staat als Combiner dat een sleutelrol speelt bij het verminderen van netwerkcongestie.
De primaire taak van Combiner een "Mini-Reducer is om de uitvoergegevens van de Mapper te verwerken, voordat deze worden doorgegeven aan Reducer. Het loopt achter de mapper en vóór de Reducer. Het gebruik ervan is optioneel.
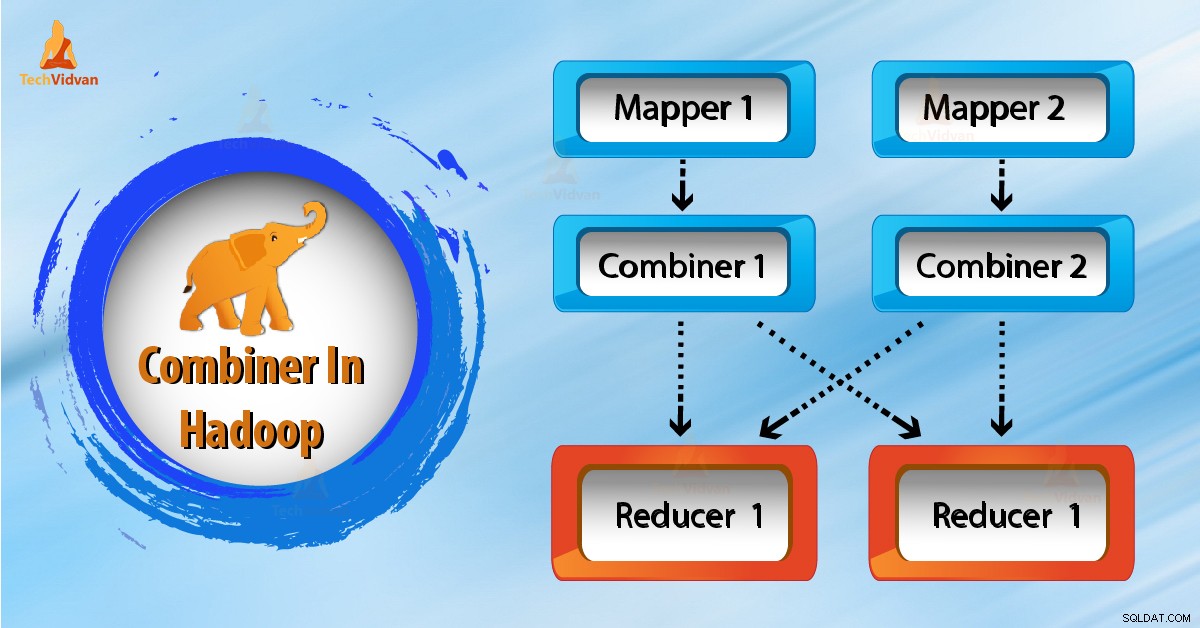
Hoe werkt Combiner in Hadoop?
Laten we nu eens kijken hoe dingen veranderen als we de combiner in MapReduce gebruiken?

Zoals we in het bovenstaande diagram zien, is er geen combiner. De invoer is opgesplitst in twee mappers. Het framework genereert 9 sleutels van de mappers.
Dus nu hebben we tussenliggende gegevens (9 sleutel/waarde). Verdere mapper stuurt deze sleutelwaarde rechtstreeks naar het verloopstuk. Tijdens het verzenden van gegevens naar het verloopstuk, verbruikt het wat netwerkbandbreedte. Het kost meer tijd om gegevens naar een reducer over te dragen als de gegevens groot zijn.

Nu uit het bovenstaande diagram, als we een combiner gebruiken tussen mapper en reducer. Vervolgens schudt de combiner 9 sleutels/waarden voordat deze naar de reducer wordt gestuurd. En genereert vervolgens 4 sleutel/waarde-paar als uitvoer.
Nu hoeft Reducer slechts 4 sleutel/waarde-paargegevens te verwerken die zijn gegenereerd uit 2 combiners. Daarom wordt reducer slechts 4 keer uitgevoerd om de uiteindelijke uitvoer te produceren. Dit verhoogt dus de algehele prestaties.
Voordelen van Combiner in MapReduce
Laten we het nu hebben over de voordelen van Hadoop Combiner in MapReduce.
- Gebruik van combiner vermindert de tijd die nodig is voor gegevensoverdracht tussen mapper en reducer.
- Combiner verbetert de algehele prestaties van de reducer.
- Het vermindert de hoeveelheid gegevens die reducer moet verwerken.
Nadelen van Combiner in MapReduce
Er zijn ook enkele nadelen van Hadoop Combiner. Laten we nu hetzelfde bespreken.
- In het lokale bestandssysteem, wanneer Hadoop de sleutel-waardeparen opslaat en de combiner later uitvoert, zal dit dure schijf-IO veroorzaken.
- MapReduce-taken kunnen niet afhankelijk zijn van de uitvoering van de combiner, aangezien er geen garantie is voor de uitvoering ervan.
Conclusie
Daarom speelt Hadoop Combiner een sleutelrol bij het verminderen van netwerkcongestie. Het verbetert de algehele prestaties van het verloopstuk door de uitvoer van Mapper samen te vatten.
Ik hoop dat je nu een duidelijk begrip hebt van Hadoop Combiner. Als je nog vragen hebt, laat het ons dan weten door een reactie achter te laten in een sectie hieronder.