Deze Hadoop-zelfstudie draait alles om MapReduce Shuffelen en sorteren. Hier geven we u een gedetailleerde beschrijving van de Hadoop-shuffling- en sorteerfase.
Eerst bespreken we wat MapReduce Shuffing is, vervolgens met MapReduce Sorting, en daarna bespreken we de secundaire sorteerfase van MapReduce in detail.
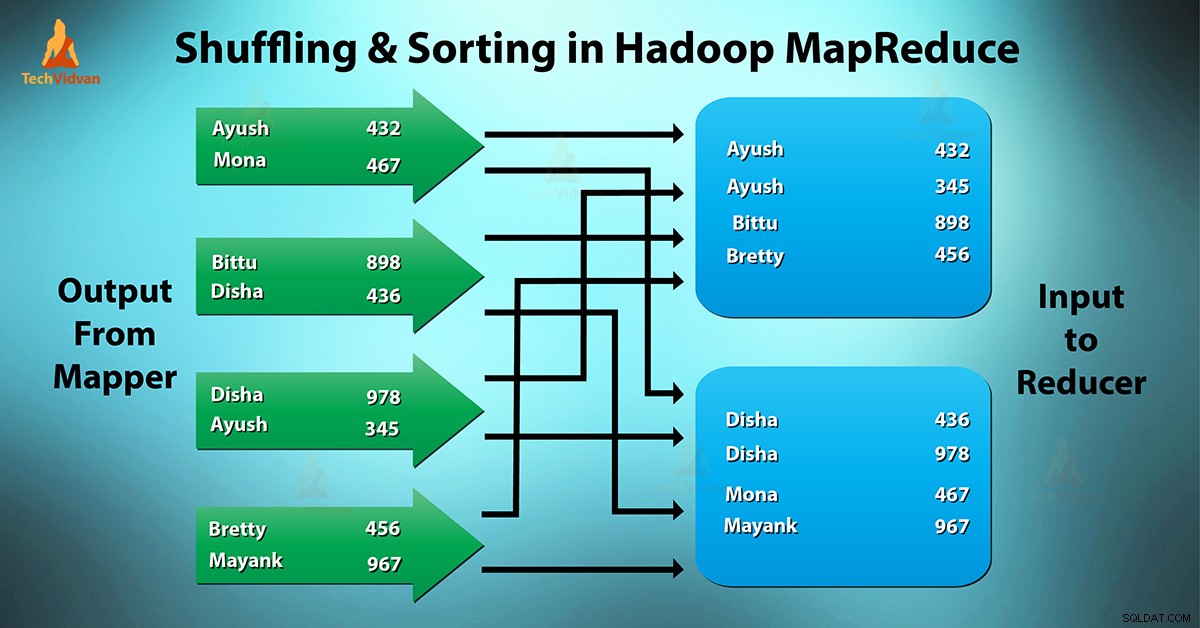
Wat is MapReduce shuffelen en sorteren?
Schudden is het proces waarmee het mappers . overdraagt tussenuitgang naar de reductor. Reducer krijgt 1 of meerdere sleutels en bijbehorende waarden op basis van reducers.
De tussenliggende sleutel - waarde gegenereerd door mapper wordt automatisch gesorteerd op sleutel. In de sorteerfase vindt het samenvoegen en sorteren van kaartuitvoer plaats.
Shuffelen en sorteren in Hadoop gebeurt gelijktijdig.
Schuddelen in MapReduce
Het proces van het overbrengen van gegevens van de mappers naar reducers is schuifelend. Het is ook het proces waarmee het systeem de sortering uitvoert. Vervolgens draagt het de kaartuitvoer over naar het verloopstuk als invoer. Dit is de reden waarom de shuffle-fase nodig is voor de verloopstukken.
Anders zouden ze geen invoer (of invoer van elke mapper) hebben. Omdat het shuffelen al kan beginnen voordat de kaartfase is afgelopen. Dit bespaart dus wat tijd en voltooit de taken in minder tijd.
Sorteren in MapReduce
MapReduce Framework sorteert automatisch de sleutels die door de mapper zijn gegenereerd. Dus voordat het verloopstuk wordt gestart, worden alle tussenliggende sleutel-waardeparen gesorteerd op sleutel en niet op waarde. Het sorteert geen waarden die aan elk verloopstuk worden doorgegeven. Ze kunnen in elke volgorde staan.
Sorteren in een MapReduce-taak helpt verkleiner om gemakkelijk te onderscheiden wanneer een nieuwe verkleiningstaak moet beginnen.
Dit bespaart tijd voor de reducer. Reducer in MapReduce start een nieuwe reduceertaak wanneer de volgende sleutel in de gesorteerde invoergegevens anders is dan de vorige. Elke verminderingstaak neemt sleutelwaardeparen als invoer en genereert sleutelwaardepaar als uitvoer.
Het belangrijkste om op te merken is dat shuffelen en sorteren in Hadoop MapReduce helemaal niet zal plaatsvinden als u nul-reducers opgeeft (setNumReduceTasks(0)).
Als reducer nul is, stopt de MapReduce-taak bij de kaartfase. En de kaartfase bevat geen enkele vorm van sorteren (zelfs de kaartfase is sneller).
Secundaire sortering in MapReduce
Als we reducerwaarden willen sorteren, gebruiken we een secundaire sorteertechniek. Deze techniek stelt ons in staat om de waarden te sorteren (in oplopende of aflopende volgorde) die aan elk verloopstuk zijn doorgegeven.
Conclusie
Concluderend, MapReduce Shuffling en Sorting vindt gelijktijdig plaats om de tussenliggende uitvoer van Mapper samen te vatten. Hadoop Shuffling-Sorting vindt niet plaats als u nul-reducers opgeeft (setNumReduceTasks (0)).
Framework sorteert alle tussenliggende sleutel-waardeparen op sleutel, niet op waarde. Het maakt gebruik van secundaire sortering voor het sorteren op waarde. Als je een suggestie of vraag hebt met betrekking tot de MapReduce Shuffle and Sorting-fase, laat dan een reactie achter in een opmerkingenveld.
We lossen ze graag op.