Het hoofddoel van deze Hadoop-zelfstudie is om u een gedetailleerde beschrijving te geven van elk onderdeel dat wordt gebruikt bij het werken met Hadoop. In deze tutorial gaan we de Partitioner in Hadoop behandelen.
Wat is Hadoop Partitioner, wat is de behoefte van Partitioner in Hadoop, Wat is de standaard Partitioner in MapReduce, Hoeveel MapReduce Partitioners worden er gebruikt in Hadoop?
We zullen al deze vragen beantwoorden in deze MapReduce-zelfstudie.
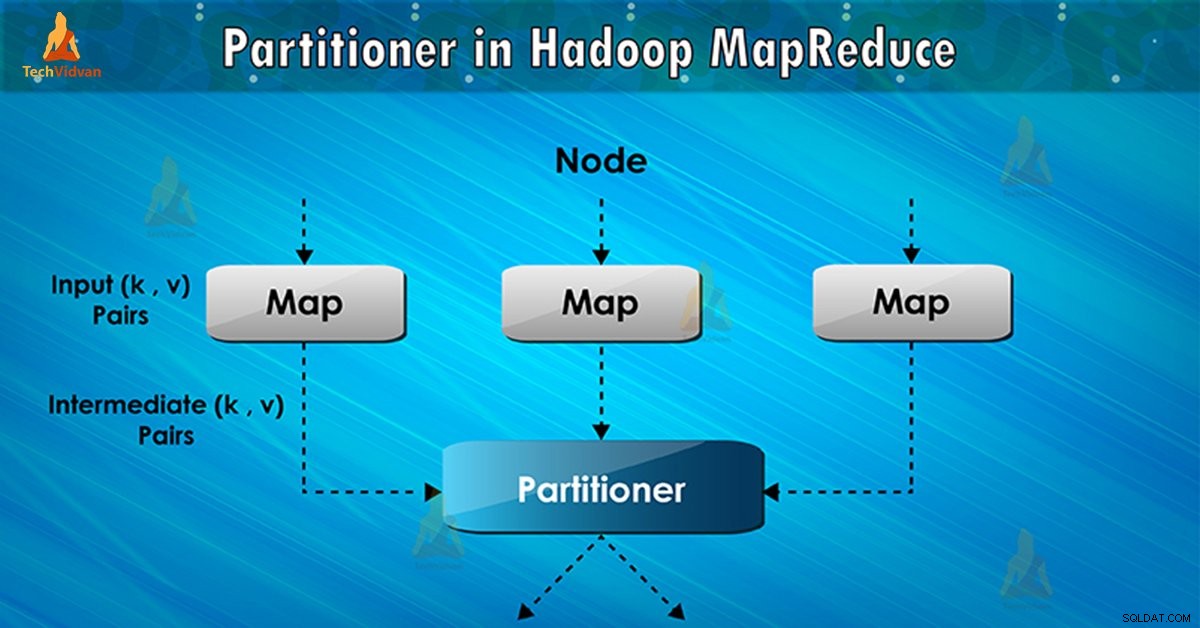
Wat is Hadoop Partitioner?
Partitioner in MapReduce-taakuitvoering bestuurt de partitionering van de sleutels van de tussenliggende map-outputs. Met behulp van de hash-functie leidt de sleutel (of een subset van de sleutel) de partitie af. Het totale aantal partities is gelijk aan het aantal reduceertaken.
Op basis van sleutelwaarde , raamwerkpartities, elke mapper uitvoer. Records met dezelfde sleutelwaarde gaan naar dezelfde partitie (binnen elke mapper). Vervolgens wordt elke partitie naar een reducer . gestuurd .
Partitieklasse beslist naar welke partitie een bepaald (sleutel, waarde) paar zal gaan. De partitiefase in MapReduce-gegevensstroom vindt plaats na de kaartfase en vóór de reductiefase.
MapReduce Partitioner nodig in Hadoop
In MapReduce-taakuitvoering is een invoergegevensset nodig en wordt de lijst met sleutelwaardepaar geproduceerd. Dit sleutel-waardepaar is het resultaat van de kaartfase. In welke invoergegevens worden gesplitst en elke taak de splitsing verwerkt en elke kaart de lijst met sleutelwaardeparen uitvoert.
Vervolgens stuurt Framework de kaartuitvoer om de taak te verminderen. Reduce verwerkt de door de gebruiker gedefinieerde reduceerfunctie op kaartuitgangen. Vóór de reductiefase vindt partitionering van de kaartuitvoer plaats op basis van de sleutel.
Hadoop Partitioning geeft aan dat alle waarden voor elke sleutel bij elkaar worden gegroepeerd. Het zorgt er ook voor dat alle waarden van een enkele sleutel naar hetzelfde verloopstuk gaan. Dit maakt een gelijkmatige verdeling van de kaartuitvoer over het verloopstuk mogelijk.
Partitioner in een MapReduce-taak leidt de uitvoer van de mapper om naar de reducer door te bepalen welke reducer de specifieke sleutel verwerkt.
Hadoop-standaardpartitioner
Hash-partitioner is de standaard Partitioner. Het berekent een hash-waarde voor de sleutel. Het wijst ook de partitie toe op basis van dit resultaat.
Hoeveel Partitioners in Hadoop?
Het totale aantal Partitioners is afhankelijk van het aantal verloopstukken. Hadoop Partitioner verdeelt de gegevens op basis van het aantal reducers. Het wordt ingesteld door JobConf.setNumReduceTasks() methode.
Dus de enkele reducer verwerkt de gegevens van de enkele partitioner. Het belangrijkste om op te merken is dat het raamwerk alleen een partitie maakt als er veel verloopstukken zijn.
Slechte partitionering in Hadoop MapReduce
Als bij gegevensinvoer in MapReduce-taak één sleutel meer verschijnt dan elke andere sleutel. In dat geval gebruiken we twee mechanismen om gegevens naar de partitie te sturen, namelijk:
- De sleutel die vaker voorkomt, wordt naar één partitie verzonden.
- Alle andere sleutels worden naar partities gestuurd op basis van hun hashCode() .
Als hashCode() methode distribueert geen andere sleutelgegevens over het partitiebereik. Er worden dan geen gegevens naar de verloopstukken verzonden.
Slechte partitionering van gegevens betekent dat sommige reducers meer gegevensinvoer zullen hebben in vergelijking met andere. Ze zullen meer werk te doen hebben dan andere verloopstukken. De hele klus moet dus wachten tot één verloopstuk zijn extra grote deel van de lading heeft voltooid.
Hoe slechte partitionering in MapReduce te verhelpen?
Om een slechte partitie in Hadoop MapReduce te overwinnen, kunnen we een aangepaste partitie maken. Dit maakt het mogelijk om de werklast over verschillende reducers te verdelen.
Conclusie
Concluderend maakt Partitioner een uniforme verdeling van de kaartuitvoer over het verloopstuk mogelijk. In MapReducer Partitioner vindt partitionering van kaartuitvoer plaats op basis van sleutel en waarde.
Daarom hebben we het volledige overzicht van Partitioner in deze blog behandeld. Ik hoop dat je het leuk vind. Als er enige twijfel in je opkomt over Hadoop Partitioner, vergeet het dan niet met ons te delen.