Evalueren welk streaming-architectuurpatroon het beste past bij uw gebruik, is een voorwaarde voor een succesvolle productie-implementatie.
Het Apache Hadoop-ecosysteem is een voorkeursplatform geworden voor ondernemingen die grootschalige gegevens in realtime willen verwerken en begrijpen. Technologieën zoals Apache Kafka, Apache Flume, Apache Spark, Apache Storm en Apache Samza verleggen steeds meer de grenzen van wat mogelijk is. Het is vaak verleidelijk om grootschalige gebruiksscenario's voor streaming samen te voegen, maar in werkelijkheid hebben ze de neiging om uiteen te vallen in een paar verschillende architecturale patronen, waarbij verschillende componenten van het ecosysteem beter geschikt zijn voor verschillende problemen.
In dit bericht zal ik de vier belangrijkste streamingpatronen schetsen die we zijn tegengekomen bij klanten die enterprise datahubs in productie hebben, en uitleggen hoe deze patronen architectonisch op Hadoop kunnen worden geïmplementeerd.
Stroompatronen
De vier basisstreamingpatronen (vaak samen gebruikt) zijn:
- Stroomopname: Betreft het aanhouden van gebeurtenissen met lage latentie voor HDFS, Apache HBase en Apache Solr.
- Near Real-Time (NRT) gebeurtenisverwerking met externe context: Onderneemt acties zoals het waarschuwen, markeren, transformeren en filteren van gebeurtenissen zodra ze binnenkomen. Er kunnen acties worden ondernomen op basis van geavanceerde criteria, zoals anomaliedetectiemodellen. Veelvoorkomende use-cases, zoals NRT-fraudedetectie en -aanbeveling, vereisen vaak lage latenties van minder dan 100 milliseconden.
- NRT-gepartitioneerde verwerking: Vergelijkbaar met NRT-gebeurtenisverwerking, maar profiteert van het partitioneren van de gegevens, zoals het opslaan van meer relevante externe informatie in het geheugen. Dit patroon vereist ook verwerkingsvertragingen van minder dan 100 milliseconden.
- Complexe topologie voor aggregaties of ML: De heilige graal van streamverwerking:krijgt realtime antwoorden uit gegevens met een complexe en flexibele reeks bewerkingen. Omdat resultaten vaak afhankelijk zijn van berekeningen in vensters en actievere gegevens vereisen, verschuift de focus van ultralage latentie naar functionaliteit en nauwkeurigheid.
In de volgende secties gaan we in op aanbevolen manieren om dergelijke patronen op een geteste, bewezen en onderhoudbare manier te implementeren.
Stroomopname
Van oudsher is Flume het aanbevolen systeem voor streaming-opname. De grote bibliotheek met bronnen en putten dekt alle basis van wat te consumeren en waar te schrijven. (Voor details over het configureren en beheren van Flume, Fluime gebruiken , het O'Reilly Media-boek van Cloudera Software Engineer/Flume PMC-lid Hari Shreedharan, is een geweldige bron.)
In het afgelopen jaar is Kafka ook populair geworden vanwege krachtige functies zoals afspelen en replicatie. Vanwege de overlap tussen de doelen van Flume en Kafka, is hun relatie vaak verwarrend. Hoe passen ze bij elkaar? Het antwoord is simpel:Kafka is een pijp vergelijkbaar met Flume's Channel-abstractie, zij het een betere pijp vanwege zijn ondersteuning voor de bovengenoemde functies. Een veelgebruikte benadering is om Flume te gebruiken voor de bron en gootsteen, en Kafka voor de pijp ertussen.
Het onderstaande diagram illustreert hoe Kafka kan dienen als de UpStream-gegevensbron voor Flume, de DownStream-bestemming van Flume of het Flume-kanaal.
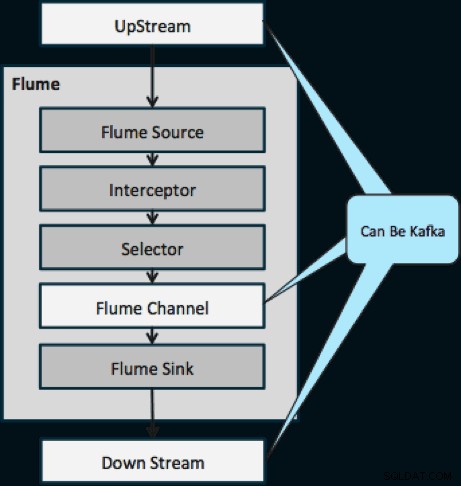
Het hieronder geïllustreerde ontwerp is enorm schaalbaar, gehard in de strijd, centraal bewaakt via Cloudera Manager, fouttolerant en ondersteunt opnieuw afspelen.
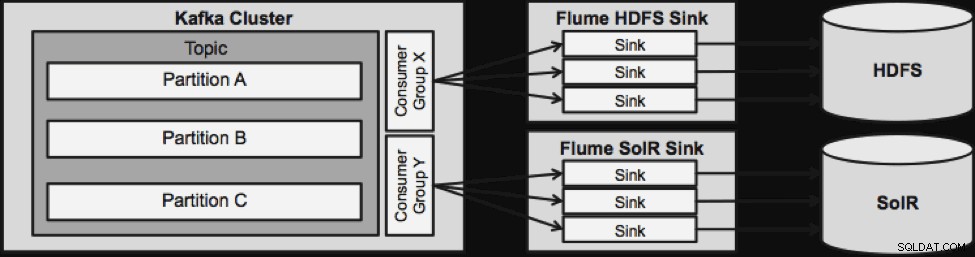
Een ding om op te merken voordat we naar de volgende streaming-architectuur gaan, is hoe dit ontwerp op een elegante manier omgaat met falen. De Flume Sinks komen uit een Kafka Consumer Group. De Consumer-groep houdt de offset van het onderwerp bij met hulp van Apache ZooKeeper. Als een Flume Sink verloren gaat, zal de Kafka Consumer de lading herverdelen over de overige putten. Wanneer de Flume Sink weer omhoog komt, zal de Consumentengroep opnieuw herverdelen.
NRT-gebeurtenisverwerking met externe context
Nogmaals, een veelvoorkomend gebruik van dit patroon is om te kijken naar gebeurtenissen die binnenstromen en onmiddellijke beslissingen te nemen, ofwel om de gegevens te transformeren of om een soort van externe actie te ondernemen. De beslissingslogica is vaak afhankelijk van externe profielen of metadata. Een gemakkelijke en schaalbare manier om deze aanpak te implementeren, is door een Source- of Sink Flume-interceptor toe te voegen aan uw Kafka/Flume-architectuur. Met een bescheiden afstemming is het niet moeilijk om latenties in de lage milliseconden te bereiken.
Flume Interceptors nemen gebeurtenissen of batches van gebeurtenissen en stellen gebruikerscode in staat om deze te wijzigen of acties op basis daarvan uit te voeren. De gebruikerscode kan communiceren met het lokale geheugen of een extern opslagsysteem zoals HBase om profielinformatie te krijgen die nodig is voor beslissingen. HBase kan ons onze informatie meestal in ongeveer 4-25 milliseconden geven, afhankelijk van het netwerk, het schemaontwerp en de configuratie. U kunt HBase ook zo instellen dat het nooit uitvalt of onderbroken wordt, zelfs niet in het geval van een storing.
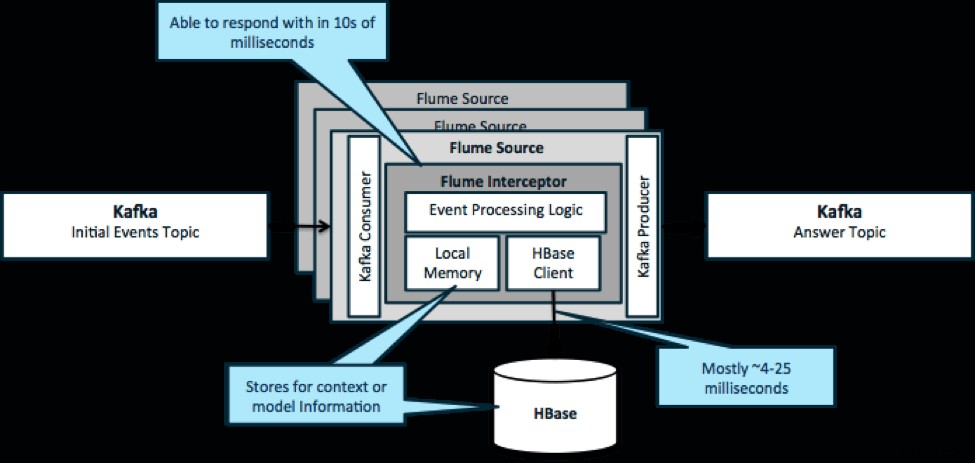
Implementatie vereist bijna geen codering buiten de toepassingsspecifieke logica in de interceptor. Cloudera Manager biedt een intuïtieve gebruikersinterface voor het implementeren van deze logica via pakketten en voor het aansluiten, configureren en bewaken van de services.
NRT-gepartitioneerde gebeurtenisverwerking met externe context
In de hieronder geïllustreerde architectuur (niet-gepartitioneerde oplossing), zou u regelmatig naar HBase moeten roepen omdat de externe context die relevant is voor bepaalde gebeurtenissen niet past in het lokale geheugen op de Flume-interceptors.
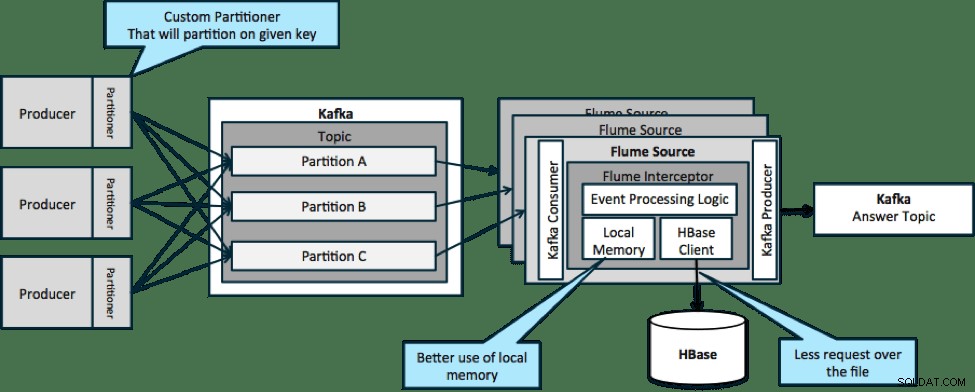
Als u echter een sleutel definieert om uw gegevens te partitioneren, kunt u binnenkomende gegevens afstemmen op de subset van de contextgegevens die daarvoor relevant is. Als u de gegevens 10 keer partitioneert, hoeft u slechts 1/10e van de profielen in het geheugen te bewaren. HBase is snel, maar het lokale geheugen is sneller. Met Kafka kun je een aangepaste partitionering definiëren die het gebruikt om je gegevens op te splitsen.
Merk op dat Flume hier niet strikt noodzakelijk is; de root-oplossing hier gewoon een Kafka-consument. U kunt dus alleen een consument in YARN gebruiken of een MapReduce-toepassing die alleen op Map is gericht.
Complexe topologie voor aggregaties of ML
Tot nu toe hebben we activiteiten op gebeurtenisniveau onderzocht. Soms hebt u echter complexere bewerkingen nodig, zoals tellingen, gemiddelden, sessionization of machine learning-modelbouw die werken op batches met gegevens. In dit geval is Spark Streaming om verschillende redenen de ideale tool:
- Het is gemakkelijk te ontwikkelen in vergelijking met andere tools. De uitgebreide en beknopte API's van Spark maken het bouwen van complexe topologieën eenvoudig.
- Vergelijkbare code voor streaming en batchverwerking. Met een paar wijzigingen kan de code voor kleine batches in realtime worden gebruikt voor enorme batches offline. Naast het verkleinen van de codegrootte, vermindert deze aanpak de tijd die nodig is voor testen en integratie.
- Er is één engine die je moet kennen. Er zijn kosten verbonden aan het opleiden van personeel over de eigenaardigheden en interne onderdelen van gedistribueerde verwerkingsengines. Standaardisatie op Spark consolideert deze kosten voor zowel streaming als batch.
- Microbatching helpt u betrouwbaar te schalen. Erkenning op batchniveau zorgt voor meer doorvoer en maakt oplossingen mogelijk zonder de angst voor een dubbele verzending. Microbatching helpt ook bij het verzenden van wijzigingen naar HDFS of HBase in termen van prestaties op schaal.
- Hadoop-ecosysteemintegratie is ingebakken. Spark heeft een diepe integratie met HDFS, HBase en Kafka.
- Geen risico op gegevensverlies. Dankzij de WAL en Kafka vermijdt Spark Streaming gegevensverlies in geval van storing.
- Het is gemakkelijk te debuggen en uit te voeren. U kunt fouten opsporen en door uw code Spark Streaming stappen in een lokale IDE zonder cluster. Bovendien ziet de code eruit als normale functionele programmeercode, dus het kost een Java- of Scala-ontwikkelaar niet veel tijd om de sprong te maken. (Python wordt ook ondersteund.)
- Streaming is native stateful. In Spark Streaming is de staat een eersteklas burger, wat betekent dat het gemakkelijk is om stateful streaming-applicaties te schrijven die bestand zijn tegen node-storingen.
- Als de de facto standaard krijgt Spark langetermijninvesteringen uit het hele ecosysteem.
Op het moment van schrijven waren er in de afgelopen 30 dagen ongeveer 700 commits voor Spark als geheel, vergeleken met andere streamingframeworks zoals Storm, met 15 commits in dezelfde tijd. - U heeft toegang tot ML-bibliotheken.
Spark's MLlib wordt enorm populair en de functionaliteit zal alleen maar toenemen. - U kunt waar nodig SQL gebruiken.
Met Spark SQL kunt u SQL-logica toevoegen aan uw streamingtoepassing om de complexiteit van de code te verminderen.
Conclusie
Er zit veel kracht in streaming en verschillende mogelijke patronen, maar zoals je in dit bericht hebt geleerd, kun je echt krachtige dingen doen met minimale codering als je weet welk patroon het beste past bij je gebruiksscenario.
Ted Malaska is Solutions Architect bij Cloudera, levert een bijdrage aan Spark, Flume en HBase, en is co-auteur van het O'Reilly-boek, Hadoop Applications Architecture.