Deze blogpost geeft een eenvoudig voorbeeld van een "hallo wereld" over hoe gegevens die zijn opgeslagen in S3 kunnen worden geïndexeerd en bediend door een Apache Solr-service die wordt gehost in een Data Discovery and Exploration-cluster in CDP. Voor de nieuwsgierigen:DDE is een vooraf getemperde, voor Solr geoptimaliseerde clusterimplementatieoptie in CDP, en onlangs uitgebracht in tech preview . In deze blog behandelen we alleen AWS- en S3-omgevingen. Implementatie-opties voor Azure en ADLS zijn ook beschikbaar in technische preview, maar zullen in een toekomstige blogpost worden behandeld.
We zullen het eenvoudigste scenario weergeven om het gemakkelijk te maken om te beginnen. Er zijn natuurlijk meer geavanceerde datapijplijnconfiguraties en uitgebreidere schema's mogelijk, maar dit is een goed startpunt voor een beginner.
Aannames:
- Je hebt al een CDP-account en hebt hoofdgebruikers- of beheerdersrechten voor de omgeving waarin je deze service wilt opstarten.
Als je geen CDP AWS-account hebt, neem dan contact op met je favoriete Cloudera-vertegenwoordiger of meld je hier aan voor een CDP-proefversie. - Je hebt omgevingen en identiteiten toegewezen en geconfigureerd. Meer expliciet, alles wat je nodig hebt is de toewijzing van de CDP-gebruiker aan een AWS-rol die toegang geeft tot de specifieke s3-bucket waaruit je wilt lezen (en schrijven naar).
- Je hebt al een werklast (FreeIPA) wachtwoord ingesteld.
- Je hebt een DDE-cluster actief. U kunt hier ook meer informatie vinden over het gebruik van sjablonen in CDP Data Hub.
- Je hebt CLI-toegang tot dat cluster.
- De SSH-poort is open op AWS wat betreft je IP-adres. U kunt het openbare IP-adres voor een van de Solr-knooppunten ophalen in de Datahub-clusterdetails. Leer hier hoe u SSH naar een AWS-cluster kunt sturen.
- Je hebt een logbestand in een S3-bucket dat toegankelijk is voor je gebruiker (
/sample.log in dit voorbeeld). Als je er geen hebt, is hier een link naar degene die we hebben gebruikt.
Werkstroom
In de volgende secties wordt u door de stappen geleid om gegevens te laten indexeren met behulp van de Crunch Indexer Tool die standaard bij DDE wordt geleverd.

Maak een verzameling voor uw index
In HUE is er een indexontwerper; zolang DDE zich echter in Tech Preview bevindt, zal het enigszins worden herbouwd en wordt dit op dit moment niet aanbevolen. Maar probeer het alsjeblieft nadat DDE GA is geworden, en laat ons weten wat je ervan vindt.
Voor nu kunt u uw Solr-schema en -configuraties maken met behulp van de CLI-tool 'solrctl'. Maak een configuratie met de naam 'my-own-logs-config' en een verzameling met de naam 'my-own-logs'. Hiervoor moet u CLI-toegang hebben.
1. SSH naar een van de werkknooppunten in uw cluster.
2. kinit als gebruiker met toestemming om de collectieconfiguratie aan te maken:
kinit
3. Zorg ervoor dat de SOLR_ZK_ENSEMBLE omgevingsvariabele is ingesteld in /etc/solr/conf/solr-env.sh. Sla de waarde op, aangezien dit nodig zal zijn in verdere stappen.
Druk op Enter en typ uw werklastwachtwoord (FreeIPA).
Bijvoorbeeld:
cat /etc/solr/conf/solr-env.sh
Verwachte output:
SOLR_ZK_ENSEMBLE=zk01.example.com:2181,zk02.example.com:2181,zk03.example.com:2181/solr
Dit wordt automatisch ingesteld op hosts met een Solr Server- of Gateway-rol in Cloudera Manager.
4. Voer de volgende opdracht uit om configuratiebestanden voor de verzameling te genereren:
solrctl config --create my-own-logs-config schemalessTemplate -p immutable=false
schemalessTemplate is een van de standaardsjablonen die bij Solr in CDP worden geleverd, maar omdat het een sjabloon is, is het onveranderlijk. Voor deze workflow moet je deze kopiëren en dus een nieuwe maken die veranderbaar is (dit is wat de immutable=false optie doet). Dit biedt u een flexibele, schemaloze configuratie. Het maken van een goed ontworpen schema is iets dat de moeite waard is om ontwerptijd in te investeren, maar is niet noodzakelijk voor verkennend gebruik. Om deze reden valt het buiten het bestek van deze blogpost. In een echte productieomgeving raden we echter ten zeerste het gebruik van goed ontworpen schema's aan - en we bieden graag deskundige hulp indien nodig!
5. Maak een nieuwe collectie met het volgende commando:
solrctl-verzameling --create my-own-logs -s 1 -c my-own-logs-config
Hiermee wordt de verzameling "my-own-logs" gemaakt op basis van de verzamelingsconfiguratie "my-own-logs-config" op één shard.
6. Om te valideren dat de collectie is aangemaakt, kunt u navigeren naar de Solr Admin UI. De verzameling voor "mijn-eigen-logboeken" is beschikbaar via de vervolgkeuzelijst in de linkernavigatie.

Indexeer uw gegevens
Hier beschrijven we aan de hand van een eenvoudig voorbeeld hoe de ingebouwde Crunch Indexer Tool moet worden geconfigureerd en uitgevoerd om snel gegevens in S3 te indexeren en via Solr in DDE te dienen. Aangezien het beveiligen van het cluster CM Auto TLS, Knox, Kerberos en Ranger kan gebruiken, kan 'Spark-indienen' afhankelijk zijn van aspecten die niet in dit bericht worden behandeld.
Het indexeren van gegevens van S3 is precies hetzelfde als het indexeren van HDFS.
Voer deze stappen uit op het Yarn worker-knooppunt (aangeduid als "Yarnworker" op de webUI van de Management Console).
1. SSH naar het speciale Yarn worker-knooppunt van het DDE-cluster als een Solr-beheerder.
Klik op de Hardware om het IP-adres van het Yarn worker-knooppunt te weten te komen. tabblad op de pagina met clusterdetails en scrol vervolgens naar het knooppunt "Yarnworker".

2. Ga naar je bronnenmap (of maak er een aan als je die nog niet hebt:
cd
Gebruik de thuismap van de admin-gebruiker als de bronnenmap (
3. Kinit uw gebruiker:
kinit
Druk op Enter en typ uw werklastwachtwoord (FreeIPA).
4. Voer de volgende curl-opdracht uit en vervang
curl --negotiate -u:"https://: /solr/admin?op=GETDELEGATIONTOKEN" --insecure> tokenFile.txt
5. Maak een Morphline-configuratiebestand voor de Crunch Indexer Tool, read-log-morphline.conf in dit voorbeeld. Vervang
SOLR_LOCATOR :{ # Naam van solr collection collection :my-own-logs #zk ensemble zkHost :
Deze Morphline leest de stacktraces uit het gegeven logbestand, schrijft dan een debug entry log en laadt het naar de gespecificeerde Solr.
6. Maak een log4j.properties-bestand voor logconfiguratie:
log4j.rootLogger=INFO, A1# A1 is ingesteld als ConsoleAppender.log4j.appender.A1=org.apache.log4j.ConsoleAppender# A1 gebruikt PatternLayout.log4j.appender.A1.layout=org.apache.log4j .PatternLayoutlog4j.appender.A1.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
7. Controleer of het bestand dat je wilt lezen bestaat op S3 (als je er geen hebt, hier is een link naar degene die we voor dit eenvoudige voorbeeld hebben gebruikt:
aws s3 ls s3://
8. Voer de opdracht spark-submit uit:
Vervang tijdelijke aanduidingen in en met de waarden die u heeft ingesteld.
export myDriverJarDir=/opt/cloudera/parcels/CDH/lib/solr/contrib/crunchexport myDependencyJarDir=/opt/cloudera/parcels/CDH/lib/search/lib/search-crunchexport myDriverJar=$(find $myDriverJarDir - maxdepth 1 -name 'search-crunch-*.jar' -name '*-job.jar'! -name '*-sources.jar')export myDependencyJarFiles=$(vind $myDependencyJarDir -name '*.jar' | sort | tr '\n' ',' | head -c -1)export myDependencyJarPaths=$(find $myDependencyJarDir -name '*.jar' | sort | tr '\n' ':' | head -c -1) export myJVMOptions="-DmaxConnectionsPerHost=10000 -DmaxConnections=10000 -Djava.io.tmpdir=/tmp/dir/ "export myResourcesDir="
Als u een soortgelijk bericht tegenkomt, kunt u dit negeren:
WARN-metadata.Hive:kan niet alle functies registreren.org.apache.hadoop.hive.ql.metadata.HiveException:org.apache.thrift.transport.TTransportException
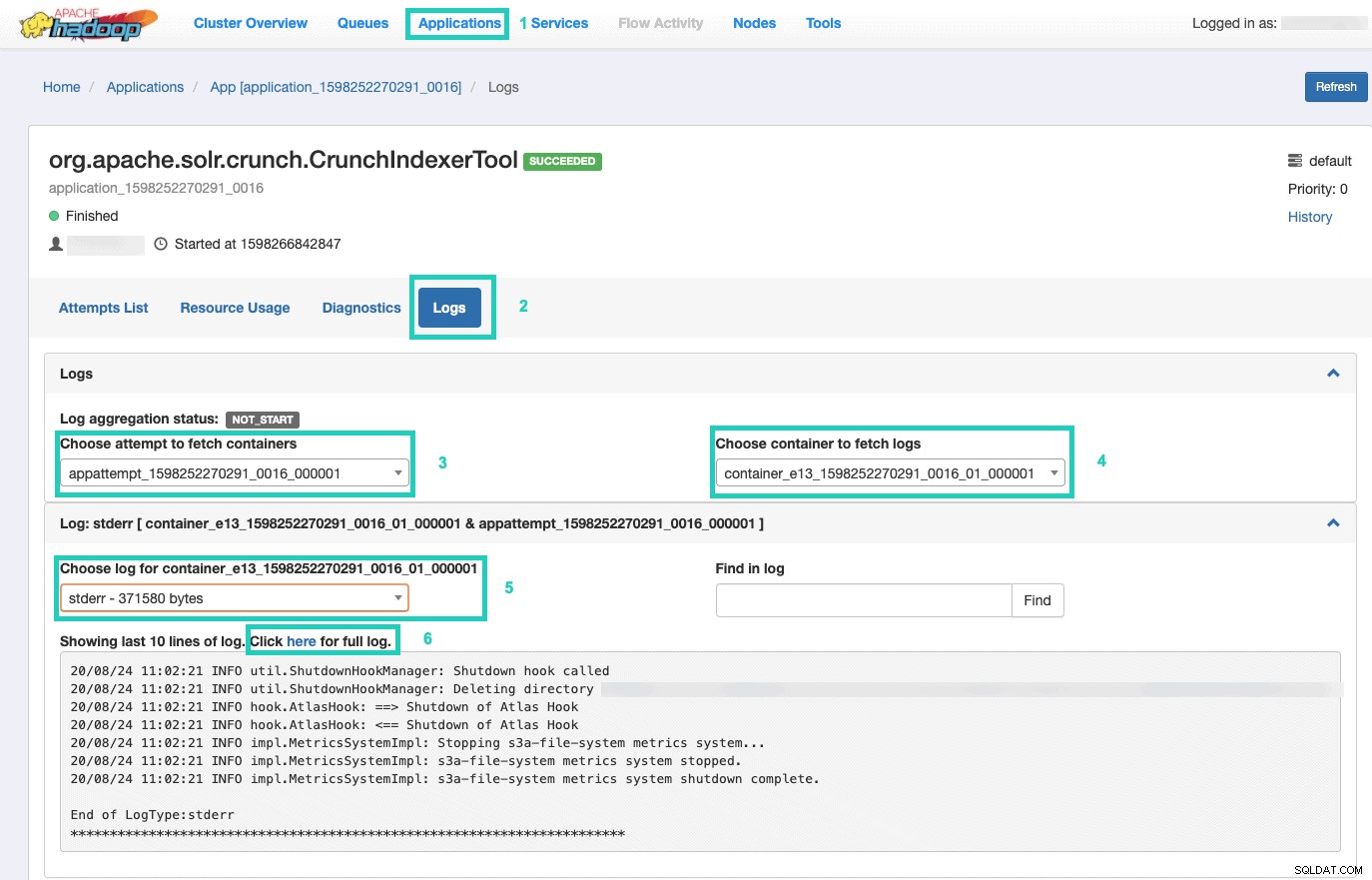
9. Ga naar Resource Manager om de uitvoering van de opdracht te controleren.

Selecteer daar de Applicaties tabblad > Klik op de Applicatie-ID van de toepassingspoging die u wilt controleren > Selecteer Logs> Kies poging om containers op te halen> Kies container om logs op te halen> Kies log voor container> Selecteer de stderr log> Klik op Klik hier voor het volledige log .
Bedien uw index
U hebt veel opties om de doorzoekbare geïndexeerde gegevens aan eindgebruikers te leveren. U kunt uw eigen rijke applicatie bouwen op basis van de rijke API's van Solr (heel gebruikelijk). U kunt uw favoriete tool van derden, zoals Qlik, Tableau, enz. verbinden via hun gecertificeerde Solr-verbindingen. Je kunt het eenvoudige solr-dashboard van Hue gebruiken om prototype-applicaties te bouwen.
Om het laatste te doen:
1. Ga naar Tint.

2. Navigeer in de dashboardweergave naar het indexbestand van uw keuze (bijvoorbeeld het bestand dat u zojuist hebt gemaakt).
3. Begin met het slepen en neerzetten van verschillende dashboardelementen en selecteer de velden uit de index om de gegevens voor de betreffende visual in te vullen.
Een korte instructievideo over het dashboard uit het verleden is hier te vinden ter inspiratie.
We zullen een diepere duik achterlaten voor een toekomstige blogpost.
Samenvatting
We hopen dat je veel hebt geleerd van deze blogpost over hoe je gegevens in S3 kunt laten indexeren door Solr in een DDE met behulp van de Crunch Indexer Tool. Natuurlijk zijn er veel andere manieren (Spark in de Data Engineering-ervaring, Nifi in de Data Flow-ervaring, Kafka in de Stream Management-ervaring, enzovoort), maar die zullen in toekomstige blogposts worden behandeld. We hopen dat u zeer succesvol zult zijn in uw verdere reis naar het bouwen van krachtige inzichttoepassingen met tekst en andere ongestructureerde gegevens. Als je besluit om DDE in CDP uit te proberen, laat ons dan weten hoe het allemaal ging!