Dit is de geschreven versie van mijn nieuwe YouTube-video ✍️ 🙂
In deze Redis-zelfstudie leert u over Redis en hoe Redis kan worden gebruikt als primaire database voor complexe toepassingen die gegevens in meerdere formaten moeten opslaan.
Overzicht 📝
- Wat Redis is en het gebruik ervan en waarom het geschikt is voor moderne complexe microservicetoepassingen?
- Hoe Redis het opslaan van meerdere gegevensformaten voor verschillende doeleinden ondersteunt via zijn modules ?
- Hoe Redis als in-memory database gegevens kan behouden en gegevensverlies kan herstellen ?
- Hoe Redis te schalen en te repliceren ?
- Ten slotte, aangezien Kubernetes een van de meest populaire platforms voor het uitvoeren van microservices is en aangezien het uitvoeren van stateful-applicaties in Kubernetes een beetje uitdagend is, zullen we zien hoe u gemakkelijk Redis in Kubernetes kunt uitvoeren
Wat is Redis?
Redis staat voor re mote dic tionele s erver
Redis is een in-memory database . Dus veel mensen hebben het gebruikt als een cache bovenop andere databases om de prestaties van de applicatie te verbeteren.
Wat veel mensen echter niet weten, is dat Redis een volwaardige primaire database is die kan worden gebruikt om meerdere gegevensindelingen voor complexe toepassingen op te slaan en te bewaren.
Dus laten we de use-cases daarvoor bekijken.
Waarom een database met meerdere modellen?
Laten we eens kijken naar een algemene setup voor een microservices-toepassing.
Laten we zeggen dat we een complexe sociale-mediatoepassing hebben met miljoenen gebruikers. Hiervoor moeten we mogelijk verschillende gegevensformaten in verschillende databases opslaan:
- Relationele database , zoals Mysql, om onze gegevens op te slaan
- ElasticSearch voor snel zoeken en filteren
- Grafische database om de connecties van de gebruikers weer te geven
- Documentendatabase , zoals MongoDB om media-inhoud op te slaan die dagelijks door onze gebruikers wordt gedeeld
- Cache-service voor een betere prestatie voor de applicatie
Het is duidelijk dat dit een behoorlijk complexe opstelling is.
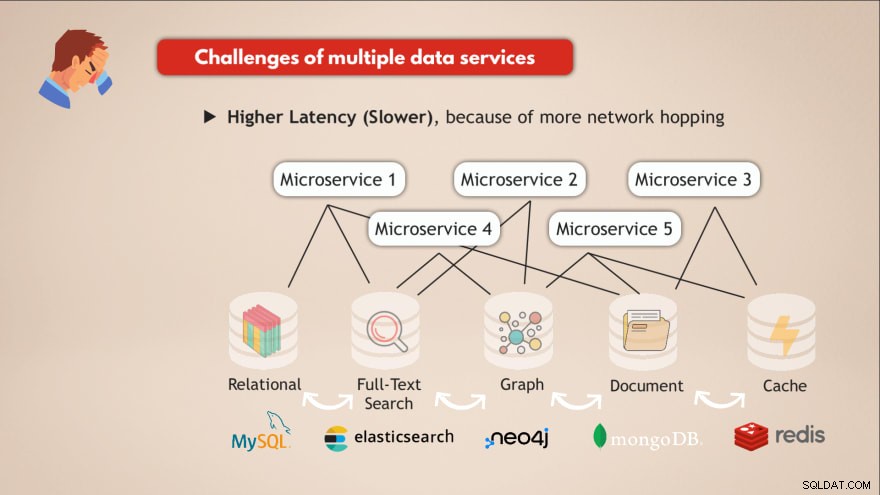
Uitdagingen bij het hebben van meerdere datadiensten
- ❌ Elke dataservice moet worden geïmplementeerd en onderhouden
- ❌ Kennis nodig voor elke dataservice
- ❌ Verschillende schaal- en infrastructuurvereisten
- ❌ Complexere applicatiecode voor interactie met al deze verschillende DB's
- ❌ Hogere latentie (langzamer), vanwege meer netwerkhoppen
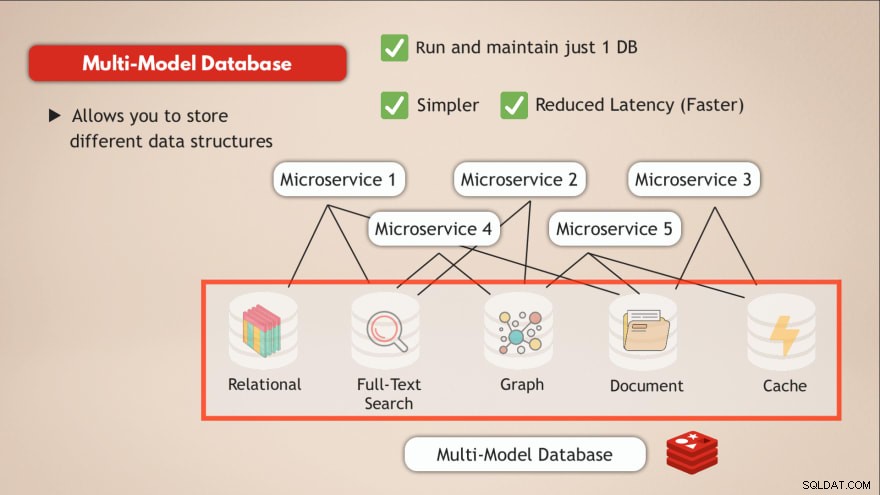
Een database met meerdere modellen hebben
In vergelijking met een database met meerdere modellen lost u de meeste van deze uitdagingen op. Allereerst gebruik en onderhoud je slechts 1 dataservice . Je applicatie moet dus ook met één datastore kunnen praten en dat vereist slechts één programmatische interface voor die dataservice.
Bovendien wordt de latentie verminderd door naar één enkel data-eindpunt te gaan en meerdere interne netwerkhubs te elimineren.
Dus het hebben van één database, zoals Redis, waarmee u verschillende soorten gegevens kunt opslaan of in feite meerdere typen databases in één kunt hebben en als een cache kunt fungeren, lost dergelijke uitdagingen op.
- ✅ Slechts 1 database uitvoeren en onderhouden
- ✅ Eenvoudiger
- ✅ Verminderde latentie (sneller)
Hoe Redis werkt?
Redis-modules
De manier waarop het werkt, is dat je Redis Core hebt, wat een sleutelwaarde-winkel is dat al ondersteuning biedt voor het opslaan van meerdere soorten gegevens en dan kunt u die kern uitbreiden met zogenaamde modules voor verschillende gegevenstypen , die uw toepassing nodig heeft voor verschillende doeleinden. Dus bijvoorbeeld RediSearch voor zoekfunctionaliteit zoals ElasticSearch of Redis Graph voor opslag van grafische gegevens enzovoort:

En het mooie hiervan is dat het modulair . is . Deze verschillende soorten databasefunctionaliteiten zijn dus niet strak geïntegreerd in één database, maar u kunt precies kiezen welke dataservicefunctionaliteit u voor uw toepassing nodig heeft en vervolgens die module in feite toevoegen.
Out-of-the-box cache ️
Als je Redis als primaire database gebruikt, heb je natuurlijk geen extra cache nodig, want die heb je bij Redis automatisch uit de doos. Dat betekent weer minder complexiteit in uw applicatie, omdat u de logica voor het beheren van het vullen en ongeldig maken van de cache niet hoeft te implementeren.
Redis is snel
Als een in-memory (gegevens worden opgeslagen in RAM) database, is Redis supersnel en performant, wat natuurlijk de applicatie zelf sneller maakt.
Maar op dit punt vraag je je misschien af:
Hoe kan een in-memory database gegevens bewaren?
Hoe kan Redis gegevens bewaren en herstellen van gegevensverlies?
Als het Redis-proces of de server waarop Redis draait faalt, zijn alle gegevens in het geheugen dan toch weg? Dus hoe worden de gegevens bewaard en hoe kan ik er in principe op vertrouwen dat mijn gegevens veilig zijn?
Redis repliceren?
Welnu, de eenvoudigste manier om gegevensback-ups te maken, is door Redis te repliceren . Dus als de Redis-hoofdinstantie uitvalt, blijven de replica's actief en hebben ze alle gegevens. Dus als je een gerepliceerde Redis hebt, hebben de replica's de gegevens.
Maar als alle Redis-instanties uitvallen, verliest u natuurlijk de gegevens, omdat er geen replica meer over is. 🤯Dus we hebben echt doorzettingsvermogen nodig .
Momentopname &AOF
Redis heeft meerdere mechanismen om de gegevens te bewaren en de gegevens veilig te houden.
Momentopnamen
Ten eerste:de snapshots, die u kunt configureren op basis van tijd, aantal verzoeken enz. Dus snapshots van uw gegevens worden opgeslagen op een schijf , die u kunt gebruiken om uw gegevens te herstellen als de hele Redis-database is verdwenen.
Houd er echter rekening mee dat u de laatste minuten aan gegevens verliest , omdat u gewoonlijk elke vijf minuten of een uur snapshots maakt, afhankelijk van uw behoeften.
AOF
Dus als alternatief gebruikt Redis iets genaamd AOF , wat staat voor A pend O alleen F iel.
In dit geval wordt elke wijziging continu op de schijf opgeslagen voor persistentie . En bij het herstarten van Redis of na een storing, zal Redis de logboeken voor alleen toevoegen van bestanden opnieuw afspelen om de status opnieuw op te bouwen.
Dus AOF is duurzamer , maar kan langzamer zijn dan snapshots maken.
Beste optie 💡 :Gebruik een combinatie van zowel AOF als snapshots, waarbij de AOF continu gegevens van het geheugen naar de schijf bewaart, plus je hebt regelmatig snapshots tussendoor om de gegevensstatus op te slaan voor het geval je het moet herstellen:

Hoe een Redis-database schalen?
Laten we zeggen dat mijn 1 Redis-instantie onvoldoende geheugen heeft, dus de gegevens worden te groot om in het geheugen te bewaren of Redis wordt een knelpunt en kan geen verzoeken meer aan. Hoe kan ik in dat geval de capaciteit en het geheugen vergroten voor mijn Redis-database?
Daar hebben we verschillende opties voor:
1. Clustering
Allereerst ondersteunt Redis clustering . Dit betekent dat u een primaire of master Redis-instantie kunt hebben, die kan worden gebruikt om gegevens te lezen en te schrijven, en u kunt meerdere replica's van die primaire instantie hebben om de gegevens te lezen :
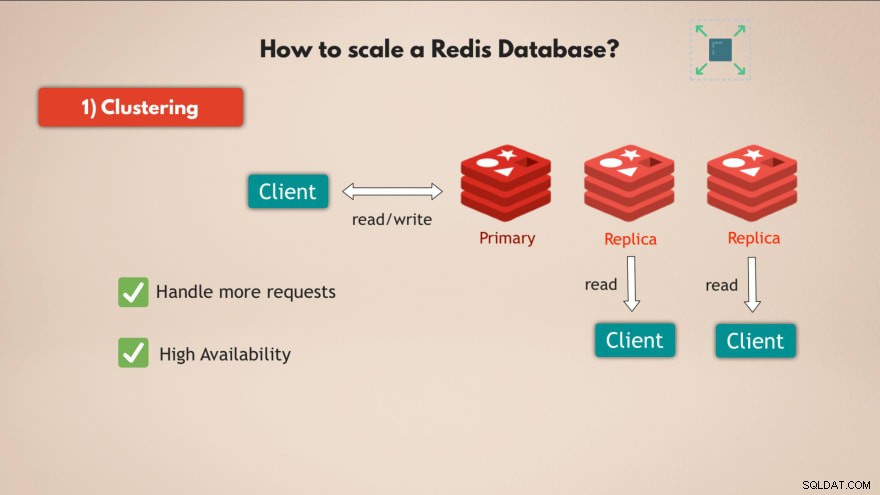
Op deze manier kunt u Redis schalen om meer verzoeken te verwerken en bovendien de hoge beschikbaarheid verhogen van uw database, want als de master faalt, kan 1 van de replica's het overnemen en kan uw Redis-database in principe probleemloos blijven functioneren.
2. Sharden
Nou, dat lijkt goed genoeg, maar wat als
- uw dataset wordt te groot om in een geheugen op een enkele server te passen .
- Bovendien hebben we de uitlezingen in de database geschaald, dus alle verzoeken die in feite alleen de gegevens opvragen. Maar onze hoofdinstantie is nog steeds alleen en moet nog steeds alle schrijfbewerkingen afhandelen .
Dus wat is hier de oplossing?
Daarvoor gebruiken we het concept van sharding , wat een algemeen concept is in databases en dat Redis ook ondersteunt.
Dus sharden betekent in feite dat u uw volledige dataset neemt en deze opdeelt in kleinere brokken of subsets van gegevens , waarbij elke shard verantwoordelijk is voor zijn eigen subset van gegevens.
Dat betekent dus dat in plaats van één hoofdinstantie te hebben die alle schrijfbewerkingen naar de volledige dataset afhandelt, u deze opsplitsen in bijvoorbeeld 4 shards, die elk verantwoordelijk zijn voor lees- en schrijfbewerkingen naar een subset van de gegevens .
En elke shard heeft ook minder geheugencapaciteit . nodig , omdat ze slechts een vierde van de gegevens hebben. Dit betekent dat u shards op kleinere knooppunten kunt distribueren en uitvoeren en uw cluster in principe horizontaal kunt schalen:
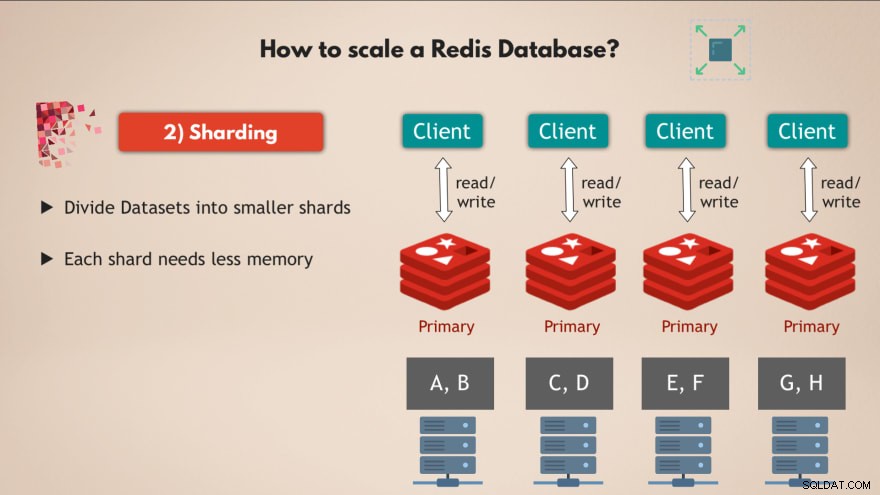
Dus met meerdere knooppunten , die meerdere replica's uitvoeren van Redis die allemaal geshard zijn geeft u een zeer performante Redis-database met hoge beschikbaarheid die veel meer verzoeken aankan zonder knelpunten te creëren 👍
Meer onderwerpen...
Bekijk mijn video hieronder voor de laatste 2 onderwerpen en scenario's:
- Applicaties die een nog hogere beschikbaarheid en prestatie nodig hebben op meerdere geografische locaties
- De nieuwe standaard voor het uitvoeren van microservices is het Kubernetes-platform, dus Redis draaien in Kubernetes is een zeer interessante en veelvoorkomende use case
De volledige video is hier beschikbaar:
Ik hoop dat dit nuttig en interessant was voor sommigen van jullie!
Like, deel en volg mij 😍 voor meer inhoud:
- Instagram - Post veel dingen achter de schermen
- Privé FB-groep