
Wat is Couchbase
Couchbase Server is een open source, gedistribueerde JSON-documentdatabase. Het onthult een scale-out, key-value store met beheerde cache voor gegevensbewerkingen van minder dan milliseconden, speciaal gebouwde indexers voor efficiënte query's en een krachtige query-engine voor het uitvoeren van SQL-achtige query's. Voor mobiele en Internet of Things-omgevingen draait Couchbase ook native op het apparaat en beheert de synchronisatie met de server.
Waarom Couchbase?
Couchbase Server is een open source, gedistribueerde JSON-documentdatabase. Het onthult een scale-out, key-value store met beheerde cache voor gegevensbewerkingen van minder dan milliseconden, speciaal gebouwde indexers voor efficiënte query's en een krachtige query-engine voor het uitvoeren van SQL-achtige query's. Voor mobiele en Internet of Things-omgevingen draait Couchbase ook native op het apparaat en beheert de synchronisatie met de server.
Couchbase Server is gespecialiseerd in het bieden van gegevensbeheer met lage latentie voor grootschalige interactieve web-, mobiele en IoT-toepassingen. Veelvoorkomende vereisten waaraan Couchbase Server is ontworpen om te voldoen, zijn onder meer:
- Eengemaakte programmeerinterface
- Query
- Zoeken
- Mobiel en IoT
- Analyse
- Kerndatabase-engine
- Uitbreidingsarchitectuur
- Geheugen-eerst architectuur
- Big data en SQL-integraties
- Volledige beveiliging
- Container- en cloudimplementaties
- Hoge beschikbaarheid
Veel databases kunnen aan een of meer van deze vereisten voldoen, maar vereisen compromissen wanneer ze in productie worden uitgevoerd met bedrijfskritische toepassingen op internetschaal. Een oplossing kan bijvoorbeeld datamodelflexibiliteit bieden, maar kan de mogelijkheid missen om knooppunten toe te voegen of te verwijderen zonder invloed op de uptime of prestaties. Een andere oplossing zou een goede schrijfschaalbaarheid kunnen aantonen zonder het datamodel on-the-fly te kunnen indexeren of wijzigen. Couchbase Server is ontworpen om een productieve ontwikkelaars- en beheerervaring te bieden en tegelijkertijd prestaties op schaal te leveren, of het nu in de cloud, in een container, on-premise of op een edge-apparaat is.
Nosql-prestatiebenchmark
Nieuwe benchmark die MongoDB, DataStax en Couchbase-server vergelijkt, toont aan dat Couchbase de meest schaalbare, best presterende NoSQL-database is.
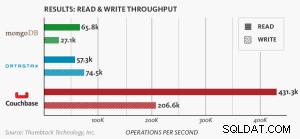
Node-gebaseerde benchmark .
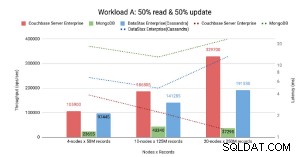
Volgens CAP Theorem Couchbase .
Cap-stelling

Couchbase staat op CP- en AP-diagram.
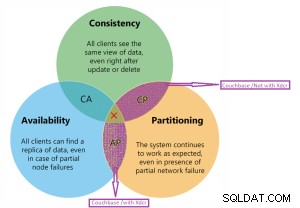
Couchbase CP- en AP-diagramdetails.
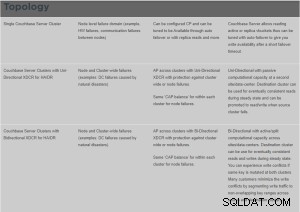
Wat is XDCR?
Cross Data Center Replication (XDCR) repliceert gegevens tussen clusters:dit biedt bescherming tegen datacenterstoringen en biedt ook hoogwaardige gegevenstoegang voor wereldwijd gedistribueerde, missiekritieke toepassingen.
XDCR repliceert gegevens van een specifieke bucket op het broncluster naar een specifieke bucket op het doelcluster. Gegevens van de bronbucket worden naar de doelbucket gepusht door middel van een XDCR-agent, die op het broncluster draait, met behulp van het Database Change Protocol. Elke bucket (Couchbase of Ephemeral) op een cluster kan worden gespecificeerd als een bron of een doel voor een of meer XDCR-definities.
Een volledige architectuurbeschrijving van XDCR vindt u in Cross Data Center Replication (XDCR). Misschien wilt u uzelf vertrouwd maken met de informatie die daar wordt gegeven, voordat u de routines in deze sectie uitvoert.
Xdcr basisstructuur;
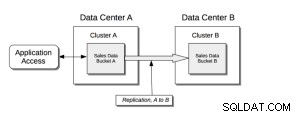
Vereisten;
- Controleer of uw cluster de juiste grootte heeft en nieuwe XDCR-streams kan verwerken. XDCR heeft bijvoorbeeld 1-2 extra CPU-kernen per stream nodig en in sommige gevallen zijn er ook meer RAM- en netwerkbronnen nodig. Als een cluster niet de juiste grootte heeft voor de bestaande werklast plus de nieuwe XDCR-streams, kan XDCR strijden om serverbronnen en een negatieve invloed hebben op de algehele prestaties.
- Couchbase Server gebruikt TCP/IP-poort 8091 om clusterconfiguratiegegevens uit te wisselen. Als u communiceert met een bestemmingscluster via een speciale verbinding of internet, moet u ervoor zorgen dat alle knooppunten in de bestemmings- en bronclusters met elkaar kunnen communiceren via poorten 8091 en 8092.
Poorten vermeld op communicatiepad
| XDCR (cluster-naar-cluster) |
|
Couchbase slaat gegevens zowel op schijf als in RAM op. Het standaardgedrag is om het document op een willekeurig tijdstip (meestal snel) naar de schijf te schrijven nadat het in het RAM is opgeslagen. Dit laat een kort venster over waarin een storing van een knooppunt kan leiden tot gegevensverlies.
In ieder geval, na het schrijven naar RAM, zal het document uiteindelijk naar de schijf worden geschreven. Couchbase houdt een wachtrij voor het schrijven van schijven bij die u kunt controleren op de pagina met het metrische rapport in de beheerconsole. Nu synchroniseert CB schrijfbewerkingen over het cluster, en ik geloof dat schrijven over een cluster wordt gesynchroniseerd voordat Couchbase zal erkennen dat het schrijven heeft plaatsgevonden (bijvoorbeeld voordat de schrijfmethode terugkeert naar de beller).
Als u meer documenten heeft dan het beschikbare RAM-geheugen, worden alleen de meest gebruikte documenten in het RAM opgeslagen zodat u ze snel kunt terugvinden, en alle andere worden "uitgezet" naar de schijf.
Advies;
Toen de grootte van de bucket werd teruggebracht van 200 GB naar 10 GB in de bron, werd replicatie sneller genoeg. Met andere woorden, als de bucketgrootte hoog is en hoewel alle gegevens in het RAM-geheugen zitten, heb ik gezien dat de replicatie 10 seconden tussenruimte had.
Bron en doel hebben dezelfde linux-instelling en dezelfde bronnen. Dit is slechts een advies.
Prod-bucket resident moet %100 zijn. Omdat replicatiesnelheid belangrijk is.
Bucket replication best settings ; XDCR Source Nozzles per Node: 2 --> 8 XDCR Target Nozzles per Node: 2 --> 24 (Nozzles=Channel=parallel , as cpu core) XDCR Checkpoint Interval (sn): 1800 --> 60 Control frequency is low, but not as much as waiting in the queue. The higher this value, the longer it takes for XDCR queues to grow. XDCR Batch Count: 500 --> 2000 It is beneficial to increase by 2.3 times. It also sends so many data groups at the same time. XDCR Batch Size (kB): 2048 --> 8192 It is beneficial to increase by 2.3 times. At the same time, it sends such a large amount of data. XDCR Failure Retry Interval: 10 --> 10 It is used for retry attempts in network errors. XDCR Optimistic Replication Threshold: 256 --> 1024 --> 256 --> 128 Increasing or decreasing this value appropriately can speed up replication, collect data above 1 mb and send it in bulk. But collection can be a waste of time and waiting in the queue. This is the compressed document size in bytes. 0 - 2097152 Bytes (20MB). Default is 256 Bytes. XDCR retrieves metadata for documents larger than this size at once before copying the uncompressed document to a destination set. This option improves XDCR latency. XDCR Statistics Collection Interval (ms): 1000 --> 1000 XDCR Logging Level: info --> info
Advies;
Ik raad aan dat bron en doel dezelfde instelling hebben en dezelfde bronnen hebben.
Dit zijn bucket-instelling, cluster-instelling, cpu, geheugen, schijfkwaliteit enz.
Xdcr-replicatie is gewoon datareplicatie. Voor replicatie moet u bucket-metadata maken.
Als u wilt, maakt u een gebruiker, index, weergave, gebeurtenis enz. aan.
Als aanvullende informatie;
U kunt xdcr-replicatie maken op de communityversie.
U kunt xdcr-replicatie maken op de enterprise-versie. Hiervoor is een extra licentie nodig. Als u stand-by niet als prikstok gebruikt, is dit geen hoge vergoeding.
Couchbase's andere connectoren voor XDCR; Elasticsearch, Hadoop, Kafka, Spark, Talend, SQL (ODBC / JDBC)
Couchbase-beheer kan via WEB UI, REST API en CLI. Met name de webgebruikersinterface is zeer eenvoudig en duidelijk te gebruiken. U kunt veel operationele transacties en vragen uitvoeren via de gebruikersinterface.
Replication Summary; Stby=Xdcr=Target=Remote same term. A different name xdcr cluster is established with the same features. The buckets with the same name with the same features are created in the xdcr cluster. In Prod, add remote server and xdcr information are entered in the xdcr tab. Prod in xdcr tab with add remote cluster; Cluster Name= Xdcr couchbase name IP/Hostname= Xdcr ip / hostname Username=Xdcr Admin username Password=Xdcr Admin user password Prod in xdcr tab with add bucket replication; Replicate From Bucket = Bucket name in the prod Remote Cluster = Added Xdcr name Remote Bucket = Bucket name added in Xdcr
Geheugeninstellingen voor Xdcr-clusterinstellingen worden gegeven volgens de servergeheugenwaarde.
Moet vrije grootte zijn voor servergeheugen.
Xdcr heeft extra geheugen nodig in het productcluster.
Replicatie van meerdere couchbase-buckets is mogelijk.
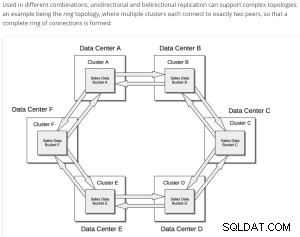
Voorbeeld XDCR-replicatie Eenvoudige bediening;
Xdcr-tabblad geselecteerd op de startpagina van couchbase.

Het tabblad Externe cluster toevoegen is geselecteerd op het geselecteerde xdcr-tabblad.

Externe clusterbewerking toevoegen gaat als volgt.
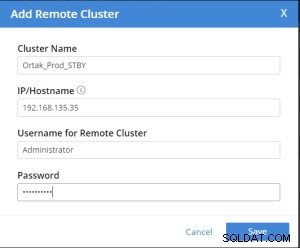
Tabblad Replicatie toevoegen is geselecteerd op het geselecteerde xdcr-tabblad.
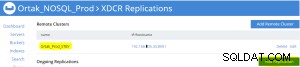
Replicatiebewerking voor buckets toevoegen gaat als volgt.
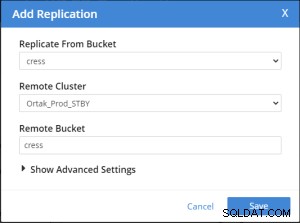
Beste parameters voor xdcr-prestaties . Maar het kan opnieuw worden ingesteld voor uw systeem.

Replicatiestatus op xdcr-tabblad van bron (prod)
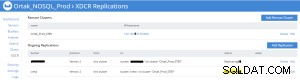
Bucket-replicatiestatistieken
Replicatieprestaties op doel;

Replicatieprestaties op bron;

Referenties;
1-) https://resources.couchbase.com/nosql_comparison_web/altoros-nosql-performance-benchmark
2-) https://docs.couchbase.com/
3-) https://www.businesswire.com/news/home/20140625005778/en/Couchbase-Blows-Past-Competition-in-NoSQL-Performance-Benchmark
4-) https://www.quora.com/What-is-the-relation-between-SQL-NoSQL-the-CAP-theorem-and-ACID
Fatih Gençali – Couchbase-certificeringen

