Wat is indexeren?
Indexering is een belangrijk concept in de databasewereld. Het belangrijkste voordeel van het maken van een index op elk veld is een snellere toegang tot gegevens. Het optimaliseert het proces van het zoeken en openen van databases. Overweeg dit voorbeeld om dit te begrijpen.
Wat zal het databasesysteem doen als een gebruiker om een specifieke rij uit de database vraagt? Het begint vanaf de eerste rij en controleert of dit de rij is die de gebruiker wil? Zo ja, retourneer dan die rij, anders blijf zoeken naar de rij tot het einde.
Wanneer u een index voor een bepaald veld definieert, zal het databasesysteem over het algemeen een geordende lijst van de waarde van dat veld maken en deze in een andere tabel opslaan. Elke invoer van deze tabel verwijst naar de overeenkomstige waarden in de oorspronkelijke tabel. Dus wanneer de gebruiker naar een rij probeert te zoeken, zoekt deze eerst naar de waarde in de indextabel met behulp van een binair zoekalgoritme en retourneert de overeenkomstige waarde uit de oorspronkelijke tabel. Dit proces kost minder tijd omdat we binair zoeken gebruiken in plaats van lineair zoeken.
In dit artikel zullen we ons concentreren op MongoDB Indexing en begrijpen hoe indexen in MongoDB kunnen worden gemaakt en gebruikt.
Hoe maak je een index in MongoDB Collection?
Om een index te maken met de Mongo-shell, kun je deze syntaxis gebruiken:
db.collection.createIndex( <key and index type specification>, <options> )Voorbeeld:
Om index op naamveld in myColl-verzameling te maken:
db.myColl.createIndex( { name: -1 } )Soorten MongoDB-indexen
-
Standaard _id-index
Dit is de standaardindex die door MongoDB wordt gemaakt wanneer u een nieuwe verzameling maakt. Als u geen waarde voor dit veld opgeeft, is _id standaard de primaire sleutel voor uw verzameling, zodat een gebruiker niet twee documenten met dezelfde veldwaarden voor _id kan invoegen. U kunt deze index niet verwijderen uit het veld _id.
-
Enkel veldindex
U kunt dit indextype gebruiken wanneer u een nieuwe index wilt maken op een ander veld dan het _id-veld.
Voorbeeld:
db.myColl.createIndex( { name: 1 } )Hiermee wordt een oplopende index met één sleutel in het naamveld in de myColl-verzameling gemaakt
-
Samengestelde index
U kunt ook een index maken op meerdere velden met behulp van samengestelde indexen. Voor deze index is de volgorde van de velden waarin ze zijn gedefinieerd in de index van belang. Beschouw dit voorbeeld:
db.myColl.createIndex({ name: 1, score: -1 })Deze index sorteert de collectie eerst op naam in oplopende volgorde en vervolgens voor elke naamwaarde sorteert het op scorewaarden in aflopende volgorde.
-
Multikey-index
Deze index kan worden gebruikt om arraygegevens te indexeren. Als een veld in een verzameling een array als waarde heeft, kunt u deze index gebruiken die afzonderlijke indexitems maakt voor elk element in de array. Als het geïndexeerde veld een array is, zal MongoDB er automatisch een Multikey-index op maken.
Beschouw dit voorbeeld:
{ ‘userid’: 1, ‘name’: ‘mongo’, ‘addr’: [ {zip: 12345, ...}, {zip: 34567, ...} ] }U kunt een Multikey-index maken in het veld addr door deze opdracht in de Mongo-shell uit te voeren.
db.myColl.createIndex({ addr.zip: 1 }) -
Geospatiale index
Stel dat u enkele coördinaten hebt opgeslagen in de MongoDB-verzameling. Om een index te maken op velden van dit type (die geospatiale gegevens bevatten), kunt u een Geospatial index gebruiken. MongoDB ondersteunt twee soorten geospatiale indexen.
-
2D-index:u kunt deze index gebruiken voor gegevens die zijn opgeslagen als punten op het 2D-vlak.
db.collection.createIndex( { <location field> : "2d" } ) -
2dsphere-index:gebruik deze index wanneer uw gegevens zijn opgeslagen als GeoJson-indeling of coördinatenparen (lengtegraad, breedtegraad)
db.collection.createIndex( { <location field> : "2dsphere" } ) -
-
Tekstindex
Om zoekopdrachten te ondersteunen, waaronder het zoeken naar tekst in de verzameling, kunt u Tekstindex gebruiken.
Voorbeeld:
db.myColl.createIndex( { address: "text" } ) -
Gehashte index
MongoDB ondersteunt op hash gebaseerde sharding. Gehashte index berekent de hash van de waarden van het geïndexeerde veld. Gehashte index ondersteunt sharding met gehashte shard-sleutels. Gehashte sharding gebruikt deze index als shardsleutel om de gegevens over uw cluster te partitioneren.
Voorbeeld:
db.myColl.createIndex( { _id: "hashed" } )
-
Unieke index
Deze eigenschap zorgt ervoor dat er geen dubbele waarden in het geïndexeerde veld staan. Als er duplicaten worden gevonden tijdens het maken van de index, worden deze items verwijderd.
-
Sparse Index
Deze eigenschap zorgt ervoor dat alle zoekopdrachten documenten met geïndexeerd veld doorzoeken. Als een document geen geïndexeerd veld heeft, wordt het verwijderd uit de resultatenset.
-
TTL-index
Deze index wordt gebruikt om automatisch documenten uit een collectie te verwijderen na een specifiek tijdsinterval (TTL). Dit is ideaal voor het verwijderen van documenten van gebeurtenislogboeken of gebruikerssessies.
Prestatieanalyse
Overweeg een verzameling leerlingscores. Er staan precies 3000000 documenten in. We hebben geen indexen gemaakt in deze verzameling. Bekijk deze afbeelding hieronder om het schema te begrijpen.
 Voorbeelddocumenten in partituurverzameling
Voorbeelddocumenten in partituurverzameling Beschouw deze vraag nu eens zonder indexen:
db.scores.find({ student: 585534 }).explain("executionStats")Deze query duurt 1155 ms om uit te voeren. Hier is de uitvoer. Zoek naar het veld executionTimeMillis voor het resultaat.
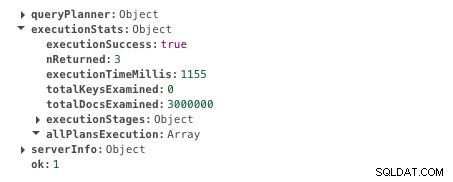 Uitvoertijd zonder indexering
Uitvoertijd zonder indexering Laten we nu een index maken op het studentenveld. Voer deze query uit om de index te maken.
db.scores.createIndex({ student: 1 })Nu duurt dezelfde zoekopdracht 0 ms.
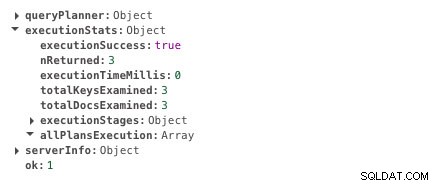 Uitvoertijd met indexering
Uitvoertijd met indexering Je ziet duidelijk het verschil in uitvoeringstijd. Het is bijna onmiddellijk. Dat is de kracht van indexeren.
Conclusie
Een voor de hand liggende afhaalmaaltijd is:maak indexen. Op basis van uw zoekopdrachten kunt u verschillende typen indexen voor uw collecties definiëren. Als u geen indexen maakt, scant elke query de volledige verzamelingen, wat veel tijd kost, waardoor uw toepassing erg traag wordt en veel bronnen van uw server worden gebruikt. Aan de andere kant, maak ook niet te veel indexen, want het maken van onnodige indexen zal extra tijd veroorzaken voor al het invoegen, verwijderen en bijwerken. Wanneer u een van deze bewerkingen uitvoert op een geïndexeerd veld, moet u dezelfde bewerking ook op de indexstructuur uitvoeren, wat tijd kost. Indexen worden opgeslagen in RAM, dus het maken van irrelevante indexen kan uw RAM-ruimte opslokken en uw server vertragen.