Het verbeteren van de systeemprestaties, vooral voor computerstructuren, vereist een proces om een goed overzicht van de prestaties te krijgen. Dit proces wordt over het algemeen monitoring genoemd. Monitoring is een essentieel onderdeel van databasebeheer en de gedetailleerde prestatie-informatie van uw MongoDB helpt u niet alleen om de functionele status ervan te meten; maar geef ook een aanwijzing over afwijkingen, wat handig is bij het uitvoeren van onderhoud. Het is essentieel om ongebruikelijk gedrag te identificeren en op te lossen voordat ze escaleren tot ernstigere fouten.
Enkele van de soorten storingen die kunnen optreden zijn...
- Vertraging of vertraging
- Onvoldoende middelen
- Systeemstoring
Monitoring is vaak gericht op het analyseren van statistieken. Enkele van de belangrijkste statistieken die u wilt controleren, zijn onder meer...
- Prestaties van de database
- Gebruik van bronnen (CPU-gebruik, beschikbaar geheugen en netwerkgebruik)
- Opkomende tegenslagen
- Verzadiging en beperking van de bronnen
- Doorvoerbewerkingen
In deze blog gaan we deze statistieken in detail bespreken en kijken we naar beschikbare tools van MongoDB (zoals hulpprogramma's en commando's). We zullen ook kijken naar andere softwaretools zoals Pandora, FMS Open Source en Robo 3T. Voor de eenvoud gaan we in dit artikel de Robo 3T-software gebruiken om de statistieken te demonstreren.
Prestaties van de database
Het eerste en belangrijkste dat u in een database moet controleren, zijn de algemene prestaties, bijvoorbeeld of de server actief is of niet. Als u dit commando db.serverStatus() uitvoert op een database in Robo 3T, krijgt u deze informatie te zien die de status van uw server toont.
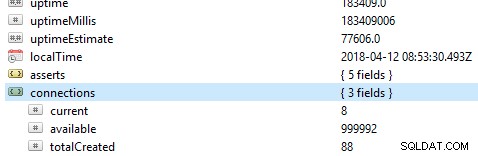

Replica-sets
Replica-set is een groep mongod-processen die dezelfde dataset onderhouden. Als u replicasets gebruikt, met name in de productiemodus, bieden bewerkingslogboeken een basis voor het replicatieproces. Alle schrijfbewerkingen worden gevolgd met behulp van knooppunten, dat wil zeggen een primair knooppunt en een secundair knooppunt, die een verzameling van beperkte omvang opslaan. Op het primaire knooppunt worden de schrijfbewerkingen toegepast en verwerkt. Als het primaire knooppunt echter faalt voordat ze naar de bewerkingslogboeken worden gekopieerd, wordt het secundaire schrijven uitgevoerd, maar in dit geval worden de gegevens mogelijk niet gerepliceerd.
Belangrijke statistieken om in de gaten te houden...
Replicatievertraging
Dit definieert hoe ver het secundaire knooppunt zich achter het primaire knooppunt bevindt. Een optimale toestand vereist dat de opening zo klein mogelijk is. Op een normaal besturingssysteem wordt deze vertraging geschat op 0. Als de kloof te groot is, komt de gegevensintegriteit in gevaar zodra het secundaire knooppunt wordt gepromoveerd tot primair. In dit geval kunt u een drempel instellen, bijvoorbeeld 1 minuut, en bij overschrijding wordt een alarm ingesteld. Veelvoorkomende oorzaken van grote replicatievertraging zijn...
- Shards die mogelijk onvoldoende schrijfcapaciteit hebben, wat vaak wordt geassocieerd met verzadiging van bronnen.
- Het secundaire knooppunt levert gegevens langzamer dan het primaire knooppunt.
- Nodes kunnen ook op de een of andere manier worden belemmerd om te communiceren, mogelijk door een slecht netwerk.
- Bewerkingen op het primaire knooppunt kunnen ook langzamer zijn, waardoor replicatie wordt geblokkeerd. Als dit gebeurt, kunt u de volgende opdrachten uitvoeren:
- db.getProfilingLevel():als u een waarde van 0 krijgt, zijn uw db-bewerkingen optimaal.
Als de waarde 1 is, komt dit overeen met langzame bewerkingen die bijgevolg het gevolg kunnen zijn van trage zoekopdrachten. - db.getProfilingStatus():in dit geval controleren we de waarde van slowms, standaard is deze 100ms. Als de waarde groter is dan dit, heeft u mogelijk zware schrijfbewerkingen op de primaire of onvoldoende bronnen op de secundaire. Om dit op te lossen, kun je de secundaire schaal schalen zodat deze net zoveel middelen heeft als de primaire.
- db.getProfilingLevel():als u een waarde van 0 krijgt, zijn uw db-bewerkingen optimaal.
Cursors
Als u bijvoorbeeld een leesverzoek doet, krijgt u een cursor die een verwijzing is naar de dataset van het resultaat. Als u deze opdracht db.serverStatus() uitvoert en naar het metrische object gaat en vervolgens de cursor, ziet u dit...

In dit geval is de eigenschap cursor.timeOut stapsgewijs bijgewerkt naar 9 omdat er 9 verbindingen zijn verbroken zonder de cursor te sluiten. Het gevolg is dat het open blijft op de server en dus geheugen verbruikt, tenzij het wordt gebruikt door de standaard MongoDB-instelling. Een waarschuwing voor u zou moeten zijn om niet-actieve cursors te identificeren en ze te oogsten om geheugen te besparen. U kunt ook niet-time-outcursors vermijden, omdat ze vaak bronnen vasthouden, waardoor de interne systeemprestaties worden vertraagd. Dit kan worden bereikt door de waarde van de eigenschap cursor.open.noTimeout in te stellen op een waarde van 0.
Journaling
Gezien de WiredTiger Storage Engine, voordat gegevens worden vastgelegd, worden deze eerst naar de schijfbestanden geschreven. Dit wordt journaliseren genoemd. Journaling zorgt voor de beschikbaarheid en duurzaamheid van gegevens over een storing van waaruit herstel kan worden uitgevoerd.
Met het oog op herstel gebruiken we vaak checkpoints (vooral voor het WiredTiger-opslagsysteem) om te herstellen vanaf het laatste checkpoint. Als MongoDB echter onverwacht wordt afgesloten, gebruiken we de journaaltechniek om alle gegevens te herstellen die zijn verwerkt of verstrekt na het laatste controlepunt.
Journaling mag in het eerste geval niet worden uitgeschakeld, omdat het slechts 60 seconden duurt om een nieuw controlepunt te maken. Als er dus een storing optreedt, kan MongoDB het journaal opnieuw afspelen om verloren gegevens binnen deze seconden te herstellen.
Journaling verkleint over het algemeen het tijdsinterval vanaf het moment dat gegevens op het geheugen worden toegepast totdat ze duurzaam op schijf staan. Het object storage.journal heeft een eigenschap die de commit-frequentie beschrijft, dat wil zeggen commitIntervalMs, die vaak is ingesteld op een waarde van 100ms voor WiredTiger. Als u deze op een lagere waarde afstemt, wordt de frequente opname van schrijfacties verbeterd, waardoor het aantal gevallen van gegevensverlies wordt verminderd.
Vergrendelingsprestaties
Dit kan worden veroorzaakt door meerdere lees- en schrijfverzoeken van veel clients. Wanneer dit gebeurt, is het nodig om consistentie te behouden en schrijfconflicten te vermijden. Om dit te bereiken gebruikt MongoDB multi-granularity-locking waarmee vergrendelingsoperaties op verschillende niveaus kunnen plaatsvinden, zoals globaal, database- of verzamelingsniveau.
Als u slechte schema-ontwerppatronen heeft, bent u kwetsbaar voor vergrendelingen die voor lange duur worden vastgehouden. Dit wordt vaak ervaren bij het uitvoeren van twee of meer verschillende schrijfbewerkingen naar een enkel document in dezelfde verzameling, met als gevolg dat ze elkaar blokkeren. Voor de WiredTiger-opslagengine kunnen we het ticketsysteem gebruiken waarbij lees- of schrijfverzoeken afkomstig zijn van zoiets als een wachtrij of thread.
Standaard wordt het gelijktijdige aantal lees- en schrijfbewerkingen gedefinieerd door de parameters wiredTigerConcurrentWriteTransactions en wiredTigerConcurrentReadTransactions die beide zijn ingesteld op een waarde van 128.
Als u deze waarde te hoog schaalt, wordt u uiteindelijk beperkt door CPU-bronnen. Om de doorvoer te vergroten, is het raadzaam om horizontaal te schalen door meer shards aan te bieden.
Multiplenines Word een MongoDB DBA - MongoDB naar productie brengenLeer over wat u moet weten om MongoDB gratis te implementeren, bewaken, beheren en schalenGebruik van bronnen
Dit beschrijft over het algemeen het gebruik van beschikbare bronnen, zoals de CPU-capaciteit/verwerkingssnelheid en RAM. De prestaties, vooral voor de CPU, kunnen drastisch veranderen in overeenstemming met ongebruikelijke verkeersbelastingen. Dingen om te controleren zijn onder meer...
- Aantal verbindingen
- Opslag
- Cache
Aantal verbindingen
Als het aantal verbindingen hoger is dan wat het databasesysteem aankan, dan zullen er veel wachtrijen ontstaan. Bijgevolg zal dit de prestaties van de database overweldigen en uw installatie traag maken. Dit nummer kan leiden tot driverproblemen of zelfs complicaties met uw aanvraag.
Als u een bepaald aantal verbindingen gedurende een bepaalde periode bewaakt en vervolgens merkt dat die waarde een piek heeft bereikt, is het altijd een goede gewoonte om een waarschuwing in te stellen als de verbinding dit aantal overschrijdt.
Als het aantal te hoog wordt, kunt u opschalen om deze stijging op te vangen. Om dit te doen, moet u het aantal beschikbare verbindingen binnen een bepaalde periode weten, anders worden verzoeken niet tijdig behandeld als de beschikbare verbindingen niet voldoende zijn.
Standaard biedt MongoDB ondersteuning voor maximaal 1 miljoen verbindingen. Zorg er bij uw monitoring altijd voor dat de huidige verbindingen nooit te dicht bij deze waarde komen. U kunt de waarde controleren in het verbindingen-object.

Opslag
Elke rij en gegevensrecord in MongoDB wordt een document genoemd. Documentgegevens zijn in BSON-formaat. Als u in een bepaalde database de opdracht db.stats() uitvoert, krijgt u deze gegevens te zien.
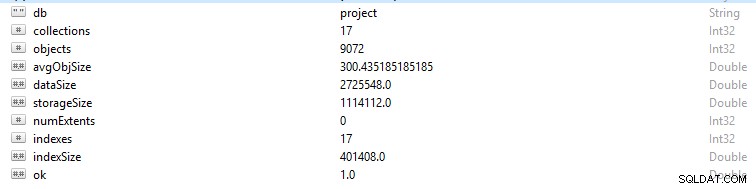
- StorageSize definieert de grootte van alle data-extensions in de database.
- IndexSize geeft de grootte weer van alle indexen die in die database zijn gemaakt.
- dataSize is een maat voor de totale ruimte die wordt ingenomen door de documenten in de database.
U kunt soms een verandering in het geheugen zien, vooral als er veel gegevens zijn verwijderd. In dit geval moet u een waarschuwing instellen om ervoor te zorgen dat deze niet te wijten was aan kwaadwillende activiteiten.
Soms kan de totale opslagcapaciteit omhoog schieten terwijl de grafiek van het databaseverkeer constant is. In dit geval moet u uw applicatie- of databasestructuur controleren om te voorkomen dat u duplicaten krijgt als dat niet nodig is.
Net als het algemene geheugen van een computer heeft MongoDB ook caches waarin actieve gegevens tijdelijk worden opgeslagen. Een bewerking kan echter vragen om gegevens die zich niet in dit actieve geheugen bevinden, waardoor een verzoek wordt gedaan vanaf de hoofdschijfopslag. Dit verzoek of deze situatie wordt paginafout genoemd. Aanvragen voor paginafouten hebben een beperking dat het langer duurt om ze uit te voeren, en kunnen schadelijk zijn als ze vaak voorkomen. Om dit scenario te voorkomen, moet u ervoor zorgen dat de grootte van uw RAM altijd voldoende is om tegemoet te komen aan de gegevenssets waarmee u werkt. Je moet er ook voor zorgen dat je geen schema-redundantie of onnodige indexen hebt.
Cache
Cache is een tijdelijk gegevensopslagitem voor veelgebruikte gegevens. In WiredTiger worden vaak de cache van het bestandssysteem en de cache van de opslagengine gebruikt. Zorg er altijd voor dat uw werkset niet verder dan de beschikbare cache uitpuilt, anders zullen de paginafouten in aantal toenemen, wat prestatieproblemen veroorzaakt.
Op een gegeven moment kunt u besluiten om uw frequente bewerkingen aan te passen, maar de wijzigingen worden soms niet weergegeven in de cache. Deze ongewijzigde gegevens worden 'vuile gegevens' genoemd. Het bestaat omdat het nog niet naar de schijf is gewist. Knelpunten zullen het gevolg zijn als de hoeveelheid "vuile gegevens" groeit tot een gemiddelde waarde die wordt gedefinieerd door langzaam schrijven naar de schijf. Door meer scherven toe te voegen, kunt u dit aantal verminderen.
CPU-gebruik
Onjuiste indexering, slechte schemastructuur en onvriendelijk ontworpen query's vereisen meer CPU-aandacht, waardoor het gebruik ervan duidelijk zal toenemen.
Doorvoerbewerkingen
Door voldoende informatie over deze operaties te krijgen, kan men voor een groot deel de daaruit voortvloeiende tegenslagen, zoals fouten, verzadiging van middelen en functionele complicaties, vermijden.
U moet altijd rekening houden met het aantal lees- en schrijfbewerkingen naar de database, dat wil zeggen een overzicht op hoog niveau van de activiteiten van het cluster. Als u weet hoeveel bewerkingen er voor de verzoeken zijn gegenereerd, kunt u de belasting berekenen die de database naar verwachting zal verwerken. De belasting kan vervolgens worden afgehandeld door uw database op te schalen of uit te schalen; afhankelijk van het soort middelen dat u heeft. Hierdoor kunt u eenvoudig de quotiëntverhouding meten waarin de verzoeken zich ophopen tot de snelheid waarmee ze worden verwerkt. Bovendien kunt u uw zoekopdrachten op de juiste manier optimaliseren om de prestaties te verbeteren.
Om het aantal lees- en schrijfbewerkingen te controleren, voert u deze opdracht uit db.serverStatus(), navigeert u vervolgens naar het object locks.global, de waarde voor de eigenschap r staat voor het aantal leesverzoeken en w aantal schrijfacties.
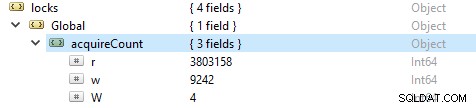
Vaker zijn de leesbewerkingen meer dan de schrijfbewerkingen. Actieve klantstatistieken worden gerapporteerd onder globalLock.
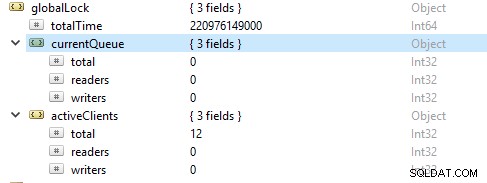
Verzadiging en beperking van bronnen
Soms kan de database het tempo van schrijven en lezen niet bijhouden, zoals blijkt uit een toenemend aantal verzoeken in de wachtrij. In dit geval moet u uw database opschalen door meer shards aan te bieden zodat MongoDB de verzoeken snel genoeg kan afhandelen.
Opkomende tegenslagen
MongoDB-logbestanden geven altijd een algemeen overzicht van geretourneerde assertuitzonderingen. Dit resultaat geeft u een idee van de mogelijke oorzaken van fouten. Als u de opdracht db.serverStatus() uitvoert, zijn enkele van de foutwaarschuwingen die u opmerkt:

- Regelmatig beweert:deze zijn het gevolg van een mislukte bewerking. Bijvoorbeeld in een schema als een tekenreekswaarde wordt verstrekt aan een integer-veld, wat resulteert in een fout bij het lezen van het BSON-document.
- Waarschuwing stelt:dit zijn vaak waarschuwingen over een bepaald probleem, maar hebben niet veel invloed op de werking ervan. Wanneer u bijvoorbeeld uw MongoDB upgradet, wordt u mogelijk gewaarschuwd met behulp van verouderde functies.
- Msg beweert:ze zijn het gevolg van interne serveruitzonderingen zoals een traag netwerk of als de server niet actief is.
- Gebruiker beweert:net als gewone beweringen, treden deze fouten op bij het uitvoeren van een opdracht, maar ze worden vaak teruggestuurd naar de client. Bijvoorbeeld als er dubbele sleutels zijn, onvoldoende schijfruimte of geen toegang om in de database te schrijven. U zult ervoor kiezen om uw aanvraag te controleren om deze fouten op te lossen.