De efficiëntie van een database hangt niet alleen af van de fijnafstemming van de meest kritische parameters, maar gaat ook verder naar de juiste datapresentatie in de gerelateerde collecties. Onlangs werkte ik aan een project dat een sociale chat-applicatie ontwikkelde, en na een paar dagen testen merkten we enige vertraging bij het ophalen van gegevens uit de database. We hadden niet zoveel gebruikers, dus we sloten het afstemmen van de databaseparameters uit en concentreerden ons op onze vragen om de oorzaak te achterhalen.
Tot onze verbazing realiseerden we ons dat onze gegevensstructurering niet helemaal passend was, omdat we meer dan één leesverzoek hadden om bepaalde specifieke informatie op te halen.
Het conceptuele model van hoe toepassingssecties worden opgezet, hangt sterk af van de structuur van de databaseverzamelingen. Als u zich bijvoorbeeld aanmeldt bij een sociale app, worden gegevens in de verschillende secties ingevoerd volgens het applicatieontwerp zoals weergegeven in de databasepresentatie.
In een notendop:voor een goed ontworpen database zijn schemastructuur en verzamelingsrelaties de belangrijkste factoren voor de verbeterde snelheid en integriteit, zoals we in de volgende secties zullen zien.
We zullen de factoren bespreken waarmee u rekening moet houden bij het modelleren van uw gegevens.
Wat is gegevensmodellering
Gegevensmodellering is over het algemeen de analyse van gegevensitems in een database en hoe gerelateerd deze zijn aan andere objecten in die database.
In MongoDB kunnen we bijvoorbeeld een gebruikersverzameling en een profielverzameling hebben. De verzameling gebruikers bevat namen van gebruikers voor een bepaalde toepassing, terwijl de verzameling profielen de profielinstellingen voor elke gebruiker vastlegt.
Bij datamodellering moeten we een relatie ontwerpen om elke gebruiker te verbinden met het corresponderende profiel. In een notendop, datamodellering is de fundamentele stap in databaseontwerp, naast het vormen van de architectuurbasis voor objectgeoriënteerd programmeren. Het geeft ook een idee over hoe de fysieke applicatie eruit zal zien tijdens de voortgang van de ontwikkeling. Een applicatie-database integratie-architectuur kan als volgt worden geïllustreerd.
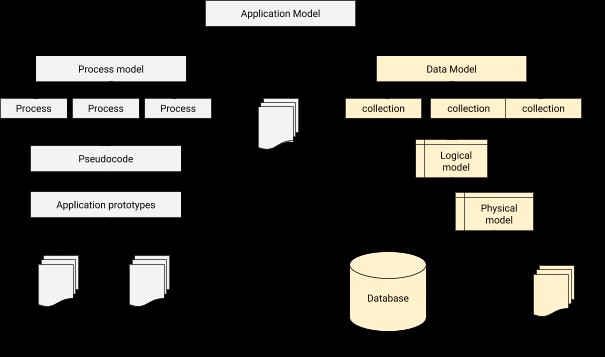
Het proces van gegevensmodellering in MongoDB
Gegevensmodellering gaat gepaard met verbeterde databaseprestaties, maar dit gaat ten koste van enkele overwegingen, waaronder:
- Patronen voor het ophalen van gegevens
- Het in evenwicht brengen van de behoeften van de applicatie, zoals:vragen, updates en gegevensverwerking
- Prestatiekenmerken van de gekozen database-engine
- De inherente structuur van de gegevens zelf
MongoDB-documentstructuur
Documenten in MongoDB spelen een belangrijke rol bij de besluitvorming over welke techniek voor een bepaalde set gegevens moet worden toegepast. Er zijn over het algemeen twee relaties tussen gegevens, namelijk:
- Ingesloten gegevens
- Referentiegegevens
Ingesloten gegevens
In dit geval worden gerelateerde gegevens in een enkel document opgeslagen, hetzij als een veldwaarde of als een array in het document zelf. Het belangrijkste voordeel van deze aanpak is dat gegevens worden gedenormaliseerd en dat het daarom de mogelijkheid biedt om de gerelateerde gegevens in één databasebewerking te manipuleren. Bijgevolg verbetert dit de snelheid waarmee CRUD-bewerkingen worden uitgevoerd, waardoor er minder zoekopdrachten nodig zijn. Laten we een voorbeeld van een document hieronder bekijken:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"Settings" : {
"location" : "Embassy",
"ParentPhone" : 724765986
"bus" : "KAZ 450G",
"distance" : "4",
"placeLocation" : {
"lat" : -0.376252,
"lng" : 36.937389
}
}
}In deze gegevensset hebben we een student met zijn naam en wat andere aanvullende informatie. Het veld Instellingen is ingebed met een object en verder is het veld plaatsLocatie ook ingebed met een object met de breedte- en lengtegraadconfiguraties. Alle gegevens van deze student zijn verzameld in één document. Als we alle informatie voor deze student moeten ophalen, voeren we gewoon uit:
db.students.findOne({StudentName : "George Beckonn"})Krachten van inbedding
- Hogere gegevenstoegangssnelheid:voor een betere toegang tot gegevens is insluiten de beste optie, aangezien een enkele querybewerking gegevens binnen het opgegeven document kan manipuleren met slechts één databasezoekopdracht.
- Verminderde inconsistentie van gegevens:als er tijdens de werking iets misgaat (bijvoorbeeld een netwerkuitval of stroomstoring), kan dit slechts een paar aantallen documenten beïnvloeden, aangezien de criteria vaak één enkel document selecteren.
- Gereduceerde CRUD-bewerkingen. Dit wil zeggen dat het aantal leesbewerkingen het aantal schrijfbewerkingen overtreft. Bovendien is het mogelijk om gerelateerde gegevens bij te werken in een enkele atomaire schrijfbewerking. D.w.z. voor de bovenstaande gegevens kunnen we het telefoonnummer bijwerken en ook de afstand vergroten met deze enkele handeling:
db.students.updateOne({StudentName : "George Beckonn"}, { $set: {"ParentPhone" : 72436986}, $inc: {"Settings.distance": 1} })
Zwakke punten van inbedding
- Beperkte documentgrootte. Alle documenten in MongoDB zijn beperkt tot de BSON-grootte van 16 megabyte. Daarom mag de totale documentgrootte samen met ingesloten gegevens deze limiet niet overschrijden. Anders kunnen gegevens voor sommige opslagengines, zoals MMAPv1, te groot worden en leiden tot gegevensfragmentatie als gevolg van verminderde schrijfprestaties.
- Gegevensduplicatie:meerdere kopieën van dezelfde gegevens maken het moeilijker om de gerepliceerde gegevens te doorzoeken en het kan langer duren om ingesloten documenten te filteren, waardoor het belangrijkste voordeel van insluiten teniet wordt gedaan.
Puntnotatie
De puntnotatie is het identificerende kenmerk voor ingebedde gegevens in het programmeergedeelte. Het wordt gebruikt om toegang te krijgen tot elementen van een ingesloten veld of een array. In de bovenstaande voorbeeldgegevens kunnen we informatie retourneren van de student wiens locatie 'Ambassade' is met deze zoekopdracht met behulp van de puntnotatie.
db.users.find({'Settings.location': 'Embassy'})Referentiegegevens
De gegevensrelatie is in dit geval dat de gerelateerde gegevens worden opgeslagen in verschillende documenten, maar dat er een referentielink wordt uitgegeven naar deze gerelateerde documenten. Voor de voorbeeldgegevens hierboven kunnen we deze zo reconstrueren dat:
Gebruikersdocument
{ "_id" : xyz,
"StudentName" : "George Beckonn",
"ParentPhone" : 075646344,
}Instellingendocument
{
"id" :xyz,
"location" : "Embassy",
"bus" : "KAZ 450G",
"distance" : "4",
"lat" : -0.376252,
"lng" : 36.937389
}Er zijn 2 verschillende documenten, maar ze zijn gekoppeld door dezelfde waarde voor de velden _id en id. Het datamodel is dus genormaliseerd. Om toegang te krijgen tot informatie uit een gerelateerd document, moeten we echter aanvullende vragen stellen, wat resulteert in een langere uitvoeringstijd. Als we bijvoorbeeld de ParentPhone en de gerelateerde afstandsinstellingen willen bijwerken, hebben we ten minste 3 vragen, d.w.z.
//fetch the id of a matching student
var studentId = db.students.findOne({"StudentName" : "George Beckonn"})._id
//use the id of a matching student to update the ParentPhone in the Users document
db.students.updateOne({_id : studentId}, {
$set: {"ParentPhone" : 72436986},
})
//use the id of a matching student to update the distance in settings document
db.students.updateOne({id : studentId}, {
$inc: {"distance": 1}
})Krachten van verwijzingen
- Consistentie van gegevens. Voor elk document wordt een canonieke vorm gehandhaafd, dus de kans op inconsistentie in de gegevens is vrij klein.
- Verbeterde gegevensintegriteit. Dankzij de normalisatie is het eenvoudig om gegevens bij te werken, ongeacht de duur van de bewerking, en zo voor elk document correcte gegevens te garanderen zonder verwarring te veroorzaken.
- Verbeterd cachegebruik. Canonieke documenten die vaak worden geopend, worden opgeslagen in de cache in plaats van ingesloten documenten die een paar keer worden geopend.
- Efficiënt hardwaregebruik. In tegenstelling tot inbedding, wat kan leiden tot documentgroei, bevordert verwijzingen de documentgroei niet, waardoor het schijf- en RAM-gebruik wordt verminderd.
- Verbeterde flexibiliteit, vooral bij een grote set subdocumenten.
- Sneller schrijven.
Zwakke punten van verwijzing
- Meerdere zoekacties:aangezien we in een aantal documenten moeten kijken die aan de criteria voldoen, is er een langere leestijd bij het ophalen van de schijf. Bovendien kan dit leiden tot cachemissers.
- Veel zoekopdrachten worden uitgevoerd om een bepaalde bewerking uit te voeren, daarom vereisen genormaliseerde gegevensmodellen meer retourvluchten naar de server om een specifieke bewerking te voltooien.
Gegevensnormalisatie
Gegevensnormalisatie verwijst naar het herstructureren van een database in overeenstemming met enkele normale vormen om de gegevensintegriteit te verbeteren en gevallen van gegevensredundantie te verminderen.
Gegevensmodellering draait om 2 belangrijke normalisatietechnieken, namelijk:
-
Genormaliseerde datamodellen
Zoals toegepast in referentiegegevens, verdeelt normalisatie gegevens in meerdere collecties met referenties tussen de nieuwe collecties. Een enkele documentupdate wordt uitgegeven aan de andere collectie en dienovereenkomstig toegepast op het overeenkomende document. Dit zorgt voor een efficiënte weergave van gegevensupdates en wordt vaak gebruikt voor gegevens die vrij vaak veranderen.
-
Gedenormaliseerde datamodellen
Gegevens bevatten ingesloten documenten, waardoor leesbewerkingen behoorlijk efficiënt zijn. Het gaat echter gepaard met meer schijfruimtegebruik en ook met problemen om synchroon te blijven. Het denormalisatieconcept kan goed worden toegepast op subdocumenten waarvan de gegevens niet vaak veranderen.
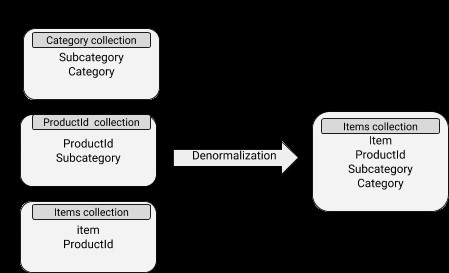
MongoDB-schema
Een schema is in feite een geschetst skelet van velden en gegevenstype dat elk veld zou moeten bevatten voor een bepaalde set gegevens. Gezien het SQL-oogpunt zijn alle rijen ontworpen om dezelfde kolommen te hebben en moet elke kolom het gedefinieerde gegevenstype bevatten. In MongoDB hebben we echter standaard een flexibel schema dat niet voor alle documenten dezelfde conformiteit heeft.
Flexibel schema
Een flexibel schema in MongoDB definieert dat de documenten niet noodzakelijk dezelfde velden of hetzelfde gegevenstype hoeven te hebben, omdat een veld kan verschillen tussen documenten binnen een verzameling. Het belangrijkste voordeel van dit concept is dat men nieuwe velden kan toevoegen, bestaande kan verwijderen of de veldwaarden kan wijzigen in een nieuw type en zo het document kan bijwerken in een nieuwe structuur.
We kunnen bijvoorbeeld deze 2 documenten in dezelfde collectie hebben:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"ParentPhone" : 75646344,
"age" : 10
}
{ "_id" : ObjectId("5b98bfe7e8b9ab98757e8b9a"),
"StudentName" : "Fredrick Wesonga",
"ParentPhone" : false,
}In het eerste document hebben we een leeftijdsveld, terwijl er in het tweede document geen leeftijdsveld is. Verder is het gegevenstype voor het veld ParentPhone een getal, terwijl het in het tweede document is ingesteld op false, wat een booleaans type is.
De flexibiliteit van het schema vergemakkelijkt het in kaart brengen van documenten aan een object en elk document kan overeenkomen met gegevensvelden van de vertegenwoordigde entiteit.
Rigide Schema
Hoezeer we ook hebben gezegd dat deze documenten van elkaar kunnen verschillen, soms kunt u besluiten om een rigide schema te maken. Een rigide schema definieert dat alle documenten in een verzameling dezelfde structuur zullen delen en dit geeft u een betere kans om enkele documentvalidatieregels in te stellen als een manier om de gegevensintegriteit te verbeteren tijdens invoeg- en updatebewerkingen.
Schemagegevenstypen
Bij het gebruik van sommige serverstuurprogramma's voor MongoDB, zoals mangoest, zijn er enkele verstrekte gegevenstypen waarmee u gegevensvalidatie kunt uitvoeren. De basisgegevenstypen zijn:
- String
- Nummer
- Booleaans
- Datum
- Buffer
- Object-ID
- Array
- Gemengd
- Decimaal128
- Kaart
Bekijk het voorbeeldschema hieronder
var userSchema = new mongoose.Schema({
userId: Number,
Email: String,
Birthday: Date,
Adult: Boolean,
Binary: Buffer,
height: Schema.Types.Decimal128,
units: []
});Voorbeeld use case
var user = mongoose.model(‘Users’, userSchema )
var newUser = new user;
newUser.userId = 1;
newUser.Email = “example@sqldat.com”;
newUser.Birthday = new Date;
newUser.Adult = false;
newUser.Binary = Buffer.alloc(0);
newUser.height = 12.45;
newUser.units = [‘Circuit network Theory’, ‘Algerbra’, ‘Calculus’];
newUser.save(callbackfunction);Schemavalidatie
Zoveel als u gegevensvalidatie kunt doen vanaf de toepassingskant, is het altijd een goede gewoonte om de validatie ook vanaf de server te doen. We bereiken dit door gebruik te maken van de schemavalidatieregels.
Deze regels worden toegepast tijdens het invoegen en bijwerken. Ze worden normaal gesproken op collectiebasis gedeclareerd tijdens het creatieproces. U kunt de documentvalidatieregels echter ook toevoegen aan een bestaande collectie met behulp van de collMod-opdracht met validatieopties, maar deze regels worden pas toegepast op de bestaande documenten wanneer er een update op van toepassing is.
Evenzo, wanneer u een nieuwe verzameling maakt met de opdracht db.createCollection() kunt u de validator-optie gebruiken. Bekijk dit voorbeeld bij het maken van een collectie voor studenten. Vanaf versie 3.6 ondersteunt MongoDB de JSON Schema-validatie, dus u hoeft alleen maar de $jsonSchema-operator te gebruiken.
db.createCollection("students", {
validator: {$jsonSchema: {
bsonType: "object",
required: [ "name", "year", "major", "gpa" ],
properties: {
name: {
bsonType: "string",
description: "must be a string and is required"
},
gender: {
bsonType: "string",
description: "must be a string and is not required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
exclusiveMaximum: false,
description: "must be an integer in [ 2017, 2020 ] and is required"
},
major: {
enum: [ "Math", "English", "Computer Science", "History", null ],
description: "can only be one of the enum values and is required"
},
gpa: {
bsonType: [ "double" ],
minimum: 0,
description: "must be a double and is required"
}
}
}})Als we in dit schemaontwerp een nieuw document proberen in te voegen, zoals:
db.students.insert({
name: "James Karanja",
year: NumberInt(2016),
major: "History",
gpa: NumberInt(3)
})De callback-functie retourneert de onderstaande fout, omdat sommige validatieregels zijn geschonden, zoals de opgegeven jaarwaarde die niet binnen de gespecificeerde limieten valt.
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 121,
"errmsg" : "Document failed validation"
}
})Verder kunt u query-expressies aan uw validatie-optie toevoegen met behulp van query-operators, behalve $where, $text, near en $nearSphere, d.w.z.:
db.createCollection( "contacts",
{ validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
]
}
} )Schemavalidatieniveaus
Zoals eerder vermeld, wordt normaal gesproken een validatie afgegeven aan de schrijfbewerkingen.
Validatie kan echter ook worden toegepast op reeds bestaande documenten.
Er zijn 3 validatieniveaus:
- Strikt:dit is het standaard MongoDB-validatieniveau en het past validatieregels toe op alle invoegingen en updates.
- Gemiddeld:de validatieregels worden toegepast tijdens invoegingen, updates en op reeds bestaande documenten die alleen aan de validatiecriteria voldoen.
- Uit:dit niveau stelt de validatieregels voor een bepaald schema in op nul, dus er wordt geen validatie uitgevoerd op de documenten.
Voorbeeld:
Laten we de onderstaande gegevens invoegen in een klantenverzameling.
db.clients.insert([
{
"_id" : 1,
"name" : "Brillian",
"phone" : "+1 778 574 666",
"city" : "Beijing",
"status" : "Married"
},
{
"_id" : 2,
"name" : "James",
"city" : "Peninsula"
}
]Als we het gematigde validatieniveau toepassen met:
db.runCommand( {
collMod: "test",
validator: { $jsonSchema: {
bsonType: "object",
required: [ "phone", "name" ],
properties: {
phone: {
bsonType: "string",
description: "must be a string and is required"
},
name: {
bsonType: "string",
description: "must be a string and is required"
}
}
} },
validationLevel: "moderate"
} )De validatieregels worden alleen toegepast op het document met _id van 1 omdat het aan alle criteria voldoet.
Voor het tweede document, aangezien niet aan de validatieregels wordt voldaan met de afgegeven criteria, zal het document niet worden gevalideerd.
Acties voor schemavalidatie
Na validatie op documenten kunnen er enkele zijn die de validatieregels schenden. Het is altijd nodig om een actie op te geven wanneer dit gebeurt.
MongoDB biedt twee acties die kunnen worden uitgevoerd op de documenten die niet voldoen aan de validatieregels:
- Fout:dit is de standaard MongoDB-actie, die elke invoeging of update weigert als deze de validatiecriteria schendt.
-
Waarschuwen:met deze actie wordt de overtreding vastgelegd in het MongoDB-logboek, maar kan de invoeg- of updatebewerking worden voltooid. Bijvoorbeeld:
db.createCollection("students", { validator: {$jsonSchema: { bsonType: "object", required: [ "name", "gpa" ], properties: { name: { bsonType: "string", description: "must be a string and is required" }, gpa: { bsonType: [ "double" ], minimum: 0, description: "must be a double and is required" } } }, validationAction: “warn” })Als we een document als dit proberen in te voegen:
db.students.insert( { name: "Amanda", status: "Updated" } );De gpa ontbreekt ongeacht het feit dat het een verplicht veld is in het schemaontwerp, maar aangezien de validatieactie is ingesteld om te waarschuwen, wordt het document opgeslagen en wordt er een foutmelding opgenomen in het MongoDB-logboek.