ClusterControl is geprogrammeerd met een aantal herstelalgoritmen om automatisch te reageren op verschillende soorten veelvoorkomende fouten die uw databasesystemen beïnvloeden. Het begrijpt verschillende typen databasetopologieën en databasegerelateerd procesbeheer om u te helpen bepalen wat de beste manier is om het cluster te herstellen. In zekere zin verbetert ClusterControl de beschikbaarheid van uw database.
Sommige topologiemanagers dekken alleen clusterherstel zoals MHA, Orchestrator en mysqlfailover, maar u moet het herstel van het knooppunt zelf afhandelen. ClusterControl ondersteunt herstel op zowel cluster- als knooppuntniveau.
Configuratie-opties
Er worden twee herstelcomponenten ondersteund door ClusterControl, namelijk:
- Cluster - Poging om een cluster te herstellen naar een operationele status
- Knooppunt - Poging om een knooppunt te herstellen naar een operationele status
Deze twee componenten zijn de belangrijkste dingen om ervoor te zorgen dat de servicebeschikbaarheid zo hoog mogelijk is. Als u al een topologiemanager bovenop ClusterControl hebt, kunt u de automatische herstelfunctie uitschakelen en een andere topologiemanager dit voor u laten doen. Met ClusterControl heeft u alle mogelijkheden.
De automatische herstelfunctie kan worden in- en uitgeschakeld met een simpele schakelaar AAN/UIT, en het werkt voor cluster- of knooppuntherstel. De groene pictogrammen betekenen ingeschakeld en rode pictogrammen betekenen uitgeschakeld. De volgende schermafbeelding laat zien waar u het kunt vinden in de lijst met databaseclusters:
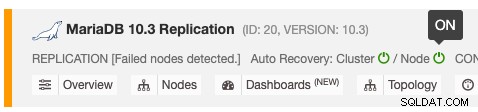
Er zijn 3 ClusterControl-parameters die kunnen worden gebruikt om het herstelgedrag te regelen. Alle parameters zijn standaard ingesteld op true (ingesteld met booleaans geheel getal 0 of 1):
- enable_autorecovery - Schakel cluster- en knooppuntherstel in. Deze parameter is de superset van enable_cluster_recovery en enable_node_recovery. Als het is ingesteld op 0, worden de subset-parameters uitgeschakeld.
- enable_cluster_recovery - ClusterControl voert clusterherstel uit indien ingeschakeld.
- enable_node_recovery - ClusterControl voert knooppuntherstel uit indien ingeschakeld.
Clusterherstel omvat herstelpogingen om de volledige clustertopologie op te halen. Een master-slave-replicatie moet bijvoorbeeld op elk moment ten minste één master in leven hebben, ongeacht het aantal beschikbare slave(s). ClusterControl probeert de topologie minstens één keer te corrigeren voor replicatieclusters, maar oneindig voor multi-masterreplicatie zoals NDB-cluster en Galera-cluster.
Knooppuntherstel dekt problemen met knooppuntherstel, bijvoorbeeld als een knooppunt wordt gestopt zonder kennis van ClusterControl, bijvoorbeeld via een systeemstopopdracht van de SSH-console of wordt gedood door het OOM-proces.
Knooppuntherstel
ClusterControl kan een databaseknooppunt herstellen in het geval van een periodieke storing door het proces en de connectiviteit met de databaseknooppunten te bewaken. Voor het proces werkt het op dezelfde manier als systemd, waar het ervoor zorgt dat de MySQL-service wordt gestart en uitgevoerd, tenzij je het opzettelijk hebt gestopt via de gebruikersinterface van ClusterControl.
Als het knooppunt weer online komt, zal ClusterControl een verbinding maken met het databaseknooppunt en de benodigde acties uitvoeren. Het volgende is wat ClusterControl zou doen om een knooppunt te herstellen:
- Het zal 30 seconden wachten tot systemd/chkconfig/init de bewaakte services/processen opstart
- Als de bewaakte services/processen nog steeds niet actief zijn, zal ClusterControl proberen de databaseservice automatisch te starten.
- Als ClusterControl de bewaakte services/processen niet kan herstellen, wordt er alarm geslagen.
Houd er rekening mee dat als het afsluiten van de database door de gebruiker wordt gestart, ClusterControl niet zal proberen het specifieke knooppunt te herstellen. Het verwacht dat de gebruiker het opnieuw start via de gebruikersinterface van ClusterControl door naar Node -> Node Actions -> Start Node te gaan of de OS-opdracht expliciet te gebruiken.
Het herstel omvat alle databasegerelateerde services zoals ProxySQL, HAProxy, MaxScale, Keepalive, Prometheus-exporteurs en garbd. Speciale aandacht voor Prometheus-exporteurs waar ClusterControl een programma genaamd "daemon" gebruikt om het exportproces te daemoniseren. ClusterControl zal proberen verbinding te maken met de luisterpoort van de exporteur voor statuscontrole en verificatie. Het wordt daarom aanbevolen om de exportpoorten van de ClusterControl- en Prometheus-server te openen om er zeker van te zijn dat er geen vals alarm optreedt tijdens het herstel.
Clusterherstel
ClusterControl begrijpt de databasetopologie en volgt best practices bij het uitvoeren van het herstel. Voor een databasecluster dat wordt geleverd met ingebouwde fouttolerantie, zoals Galera Cluster, NDB Cluster en MongoDB Replicaset, wordt het failoverproces automatisch uitgevoerd door de databaseserver via quorumberekening, hartslag en rolwisseling (indien aanwezig). ClusterControl bewaakt het proces en maakt de nodige aanpassingen aan de visualisatie, zoals het weerspiegelen van de wijzigingen in de weergave Topologie en het aanpassen van de monitoring- en beheercomponent voor de nieuwe rol, bijvoorbeeld een nieuw primair knooppunt in een replicaset.
Voor databasetechnologieën die geen ingebouwde fouttolerantie hebben met automatisch herstel, zoals MySQL/MariaDB Replication en PostgreSQL/TimescaleDB Streaming Replication, voert ClusterControl de herstelprocedures uit door de best-practices te volgen die worden geboden door de database leverancier. Als het herstel mislukt, is tussenkomst van de gebruiker vereist, en natuurlijk krijgt u hierover een alarmmelding.
In een gemengde/hybride topologie, bijvoorbeeld een asynchrone slave die is gekoppeld aan een Galera-cluster of NDB-cluster, wordt het knooppunt hersteld door ClusterControl als clusterherstel is ingeschakeld.
Clusterherstel is niet van toepassing op zelfstandige MySQL-server. Het wordt echter aanbevolen om herstel van zowel knooppunten als clusters voor dit clustertype in de gebruikersinterface van ClusterControl in te schakelen.
MySQL/MariaDB-replicatie
ClusterControl ondersteunt herstel van de volgende MySQL/MariaDB-replicatie-instellingen:
- Master-slave met MySQL GTID
- Master-slave met MariaDB GTID
- Master-slave met zonder GTID (zowel MySQL als MariaDB)
- Master-master met MySQL GTID
- Master-master met MariaDB GTID
- Asynchrone slaaf gekoppeld aan een Galera-cluster
ClusterControl respecteert de volgende parameters bij het uitvoeren van clusterherstel:
- enable_cluster_autorecovery
- auto_manage_readonly
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_check_binlog_filtratie_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- replication_post_failover_script
- replication_post_switchover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_pre_switchover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
Raadpleeg de documentatiepagina voor meer informatie over elke parameter.
ClusterControl houdt zich aan de volgende regels bij het bewaken en beheren van een master-slave-replicatie:
- Alle knooppunten worden gestart met read_only=ON en super_read_only=ON (ongeacht hun rol).
- Slechts één master (read_only=OFF) mag tegelijkertijd werken.
- Vertrouw op de MySQL-variabele report_host om de topologie in kaart te brengen.
- Als er twee of meer nodes zijn die read_only=OFF tegelijk hebben, zal ClusterControl automatisch read_only=ON op beide masters instellen om ze te beschermen tegen onbedoeld schrijven. Gebruikersinterventie is vereist om de eigenlijke master te kiezen door alleen-lezen uit te schakelen. Ga naar Knooppunten -> Knooppuntacties -> Alleen-lezen uitschakelen.
In het geval dat de actieve master uitvalt, zal ClusterControl proberen de master-failover uit te voeren in de volgende volgorde:
- Na 3 seconden van onbereikbaarheid van de master, zal ClusterControl alarm slaan.
- Controleer de beschikbaarheid van de slave, minimaal één van de slaves moet bereikbaar zijn voor ClusterControl.
- Kies de slaaf als kandidaat om meester te worden.
- ClusterControl berekent de kans op foutieve transacties als GTID is ingeschakeld.
- Als er geen foutieve transactie wordt gedetecteerd, wordt de gekozene gepromoveerd als de nieuwe master.
- Maak een replicatiegebruiker aan en sta deze toe voor gebruik door slaves.
- Verander master voor alle slaves die naar de oude master wezen naar de nieuw gepromoveerde master.
- Slaaf starten en alleen-lezen inschakelen.
- Flush logs op alle nodes.
- Als de slave-promotie mislukt, zal ClusterControl de hersteltaak afbreken. Gebruikersinterventie of het opnieuw opstarten van de cmon-service is vereist om de hersteltaak opnieuw te activeren.
- Als de oude master weer beschikbaar is, wordt deze gestart als alleen-lezen en maakt deze geen deel uit van de replicatie. Gebruikersinterventie is vereist.
Tegelijkertijd zullen de volgende alarmen afgaan:
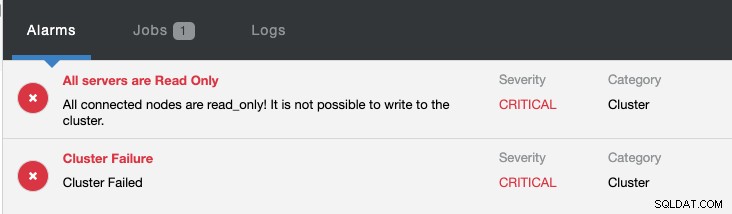
Bekijk Inleiding tot Failover voor MySQL-replicatie - de 101 Blog en automatische failover van MySQL-replicatie - Nieuw in ClusterControl 1.4 voor meer informatie over het configureren en beheren van MySQL-replicatie-failover met ClusterControl.
PostgreSQL/TimescaleDB Streaming Replicatie
ClusterControl ondersteunt herstel van de volgende PostgreSQL-replicatie-instellingen:
- PostgreSQL-streamingreplicatie
- TimescaleDB Streaming Replicatie
ClusterControl respecteert de volgende parameters bij het uitvoeren van clusterherstel:
- enable_cluster_autorecovery
- repl_password
- repl_user
- replication_auto_rebuild_slave
- replication_failover_whitelist
- replication_failover_blacklist
Raadpleeg de documentatiepagina voor meer informatie over elke parameter.
ClusterControl houdt zich aan de volgende regels voor het beheren en bewaken van een PostgreSQL-streamingreplicatieconfiguratie:
- wal_level is ingesteld op "replica" (of "hot_standby" afhankelijk van de PostgreSQL-versie).
- Variabele archive_mode is ingesteld op AAN op de master.
- Stel het recovery.conf-bestand in op de slave-knooppunten, waardoor het knooppunt een hot-standby wordt met alleen-lezen ingeschakeld.
In het geval dat de actieve master uitvalt, zal ClusterControl proberen om het clusterherstel in de volgende volgorde uit te voeren:
- Na 10 seconden onbereikbaarheid van de master zal ClusterControl alarm slaan.
- Na 10 seconden van sierlijke wachttijd, start ClusterControl de master-failover-taak.
- Bemonster de replayLocation en receiverLocation op alle beschikbare nodes om de meest geavanceerde node te bepalen.
- Promoot het meest geavanceerde knooppunt als de nieuwe master.
- Stop slaven.
- Controleer de synchronisatiestatus met pg_rewind.
- Slaves herstarten met de nieuwe master.
- Als de slave-promotie mislukt, zal ClusterControl de hersteltaak afbreken. Gebruikersinterventie of het opnieuw opstarten van de cmon-service is vereist om de hersteltaak opnieuw te activeren.
- Als de oude master weer beschikbaar is, wordt deze gedwongen af te sluiten en maakt deze geen deel uit van de replicatie. Gebruikersinterventie is vereist. Zie verder naar beneden.
Als de oude master weer online komt en de PostgreSQL-service actief is, zal ClusterControl het afsluiten van de PostgreSQL-service forceren. Dit is om de server te beschermen tegen onbedoeld schrijven, aangezien het zou worden gestart zonder een herstelbestand (recovery.conf), wat betekent dat het beschrijfbaar zou zijn. Je zou verwachten dat de volgende regels in postgresql-{day}.log zullen verschijnen:
2019-11-27 05:06:10.091 UTC [2392] LOG: database system is ready to accept connections
2019-11-27 05:06:27.696 UTC [2392] LOG: received fast shutdown request
2019-11-27 05:06:27.700 UTC [2392] LOG: aborting any active transactions
2019-11-27 05:06:27.703 UTC [2766] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.704 UTC [2758] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.709 UTC [2392] LOG: background worker "logical replication launcher" (PID 2419) exited with exit code 1
2019-11-27 05:06:27.709 UTC [2414] LOG: shutting down
2019-11-27 05:06:27.735 UTC [2392] LOG: database system is shut downDe PostgreSQL werd gestart nadat de server weer online was rond 05:06:10, maar ClusterControl sluit 17 seconden daarna snel af rond 05:06:27. Als dit iets is dat u niet zou willen, kunt u het herstel van knooppunten voor dit cluster tijdelijk uitschakelen.
Bekijk automatische failover van Postgres-replicatie en failover voor PostgreSQL-replicatie 101 voor meer informatie over het configureren en beheren van PostgreSQL-replicatiefailover met ClusterControl.
Conclusie
ClusterControl automatisch herstel begrijpt de topologie van databaseclusters en is in staat om een down of gedegradeerd cluster te herstellen naar een volledig operationeel cluster, wat de uptime van de databaseservice enorm zal verbeteren. Probeer ClusterControl nu en bereik uw negens in SLA en databasebeschikbaarheid. Weet je je negens niet? Bekijk deze coole negens-calculator.