Zorgen voor een soepele werking van uw productiedatabases is geen triviale taak, en er zijn een aantal hulpmiddelen en hulpprogramma's die u hierbij kunnen helpen. Er zijn tools beschikbaar voor het bewaken van de gezondheid, serverprestaties, het analyseren van query's, implementaties, het beheren van failover, upgrades en de lijst gaat maar door. ClusterControl als beheer- en monitoringplatform voor uw database-infrastructuur onderscheidt zich door de mogelijkheid om de volledige levenscyclus te beheren, van implementatie tot monitoring, doorlopend beheer en schaling.
Hoewel ClusterControl belangrijke functies biedt, zoals automatische database-failover, encryptie in-transit/at-rest, back-upbeheer, point-in-time recovery, Prometheus-integratie, database-scaling, zijn deze te vinden in andere enterprise management-/monitoringtools op de markt. Er zijn echter enkele functies die u niet zo gemakkelijk zult vinden. In deze blogpost presenteren we 9 functies die u niet zult vinden in andere beheer- en monitoringtools op de markt (op het moment van schrijven).
Back-upverificatie
Elke back-up is letterlijk geen back-up totdat je weet dat deze kan worden hersteld - door echt te verifiëren dat deze kan worden hersteld. Met ClusterControl kan een back-up worden geverifieerd nadat de back-up is gemaakt door een nieuwe server te draaien en herstel te testen. Het verifiëren van een back-up is een cruciaal proces om ervoor te zorgen dat u voldoet aan uw Recovery Point Objective (RPO)-beleid in het geval van noodherstel. Het verificatieproces voert het herstel uit op een nieuwe zelfstandige host (waar ClusterControl de benodigde databasepakketten installeert voordat het wordt hersteld) of op een server die speciaal is bedoeld voor back-upverificatie.
Om back-upverificatie te configureren, selecteert u eenvoudig een bestaande back-up en klikt u op Herstellen. Er zal een optie zijn om te herstellen en te verifiëren:
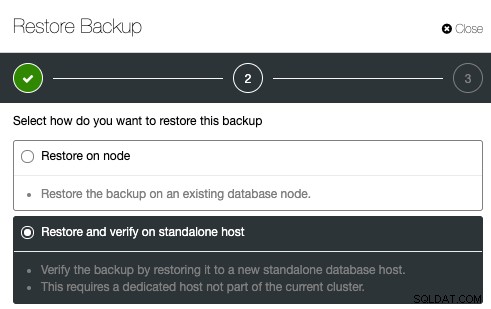
Geef vervolgens het IP-adres op van de server die u wilt herstellen en verifiëren:
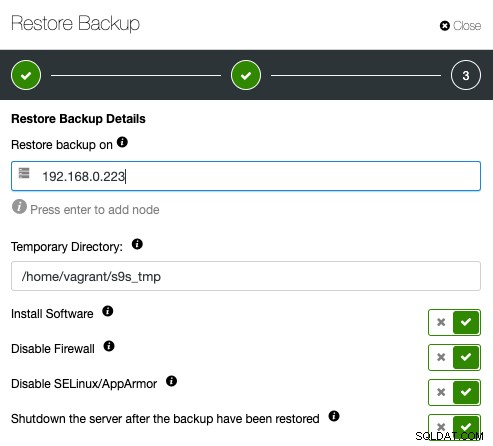
Zorg ervoor dat de opgegeven host vooraf toegankelijk is via SSH zonder wachtwoord. Je hebt ook een handvol opties eronder voor het inrichtingsproces. U kunt de verificatieserver ook afsluiten na herstel om kosten en middelen te besparen nadat de back-up is geverifieerd. ClusterControl zoekt naar de exit-code van het herstelproces en bekijkt het herstellogboek om te controleren of de verificatie mislukt of slaagt.
Vereenvoudiging van ProxySQL-beheer via een GUI
Velen zijn het erover eens dat het hebben van een grafische gebruikersinterface efficiënter is en minder vatbaar voor menselijke fouten bij het configureren van een systeem. ProxySQL maakt deel uit van de kritieke databaselaag (hoewel het er bovenop zit) en moet zichtbaar genoeg zijn voor de ogen van DBA om veelvoorkomende problemen en problemen op te sporen. ClusterControl biedt een uitgebreide grafische gebruikersinterface voor ProxySQL.
ProxySQL-instanties kunnen worden geïmplementeerd op nieuwe hosts, of bestaande kunnen worden geïmporteerd in ClusterControl. ClusterControl kan ProxySQL configureren om te worden geïntegreerd met een virtueel IP-adres (geleverd door Keepalive) voor toegang via één eindpunt tot de databaseservers. Het biedt ook monitoringinzicht in de belangrijkste ProxySQL-componenten zoals Queries Backend, Slow Queries, Top Queries, Query Hits en een heleboel andere monitoringstatistieken. Het volgende is een screenshot die laat zien hoe u een nieuwe queryregel toevoegt:
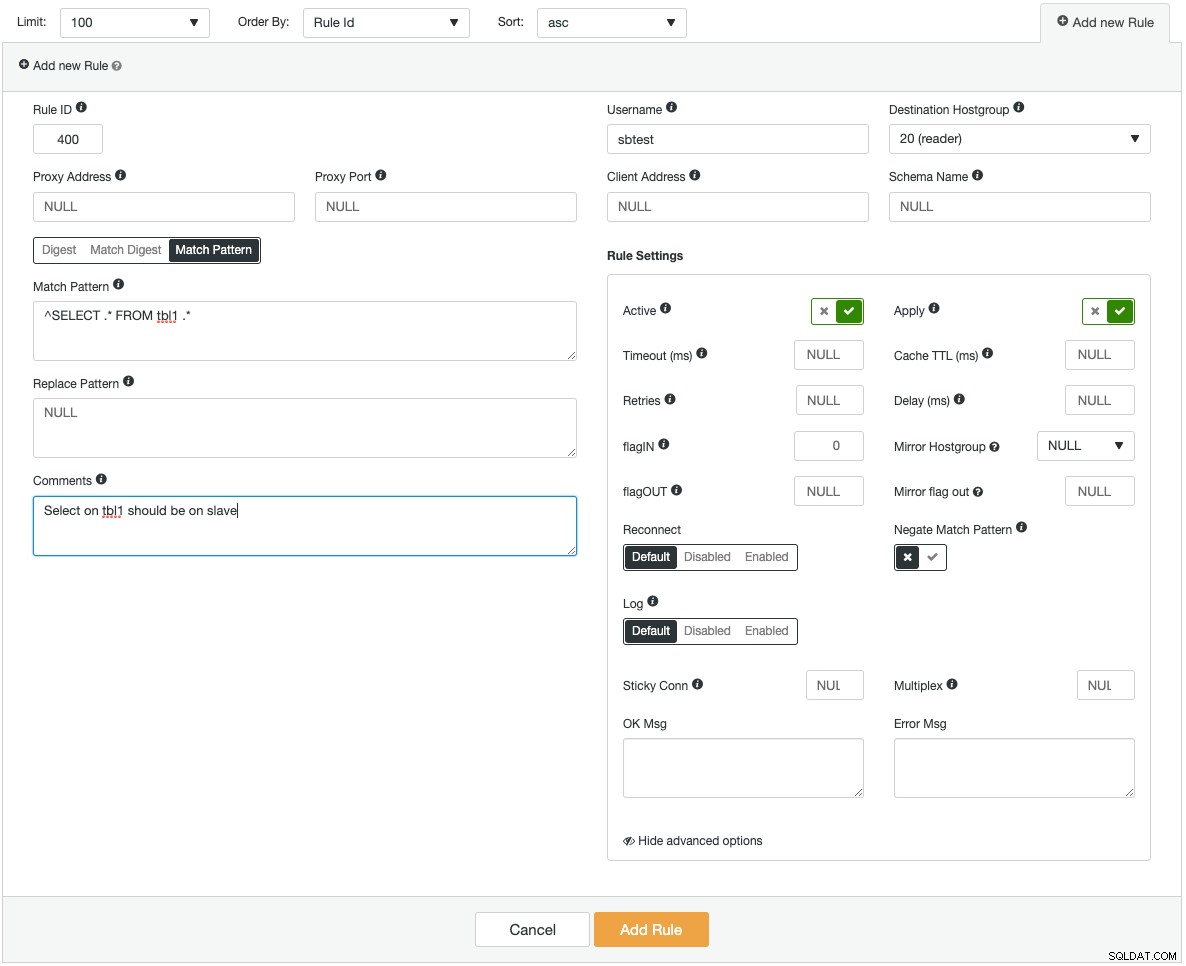
Als u een zeer complexe queryregel zou toevoegen, zou u dit gemakkelijker via de grafische gebruikersinterface kunnen doen. Elk veld heeft een tooltip om u te helpen bij het invullen van het formulier Query Rule. Bij het toevoegen of wijzigen van een ProxySQL-configuratie zorgt ClusterControl ervoor dat de wijzigingen in runtime worden aangebracht en voor persistentie op schijf worden opgeslagen.
ClusterControl 1.7.4 ondersteunt nu zowel ProxySQL 1.x als ProxySQL 2.x.
Operationele rapporten
Operationele rapporten zijn een reeks samenvattende rapporten van uw database-infrastructuur die on-the-fly kunnen worden gegenereerd of kunnen worden gepland om naar verschillende ontvangers te worden verzonden. Deze rapportages bestaan uit verschillende controles en behandelen verschillende dagelijkse DBA-taken. Het idee achter de operationele rapportage van ClusterControl is om alle meest relevante gegevens in één document te plaatsen dat snel kan worden geanalyseerd om een duidelijk inzicht te krijgen in de status van de databases en de bijbehorende processen.
Met ClusterControl kunt u clusteroverschrijdende omgevingsrapporten plannen, zoals dagelijks systeemrapport, pakketupgraderapport, schemawijzigingsrapport, evenals back-ups en beschikbaarheid. Deze rapporten helpen u om uw omgeving veilig en operationeel te houden. U ziet ook aanbevelingen voor het oplossen van hiaten. Rapporten kunnen worden gericht aan SysOps, DevOps of zelfs managers die regelmatig statusupdates willen ontvangen over de gezondheid van een bepaald systeem.
Het volgende is een voorbeeld van een dagelijks operationeel rapport dat naar uw mailbox wordt gestuurd met betrekking tot beschikbaarheid:
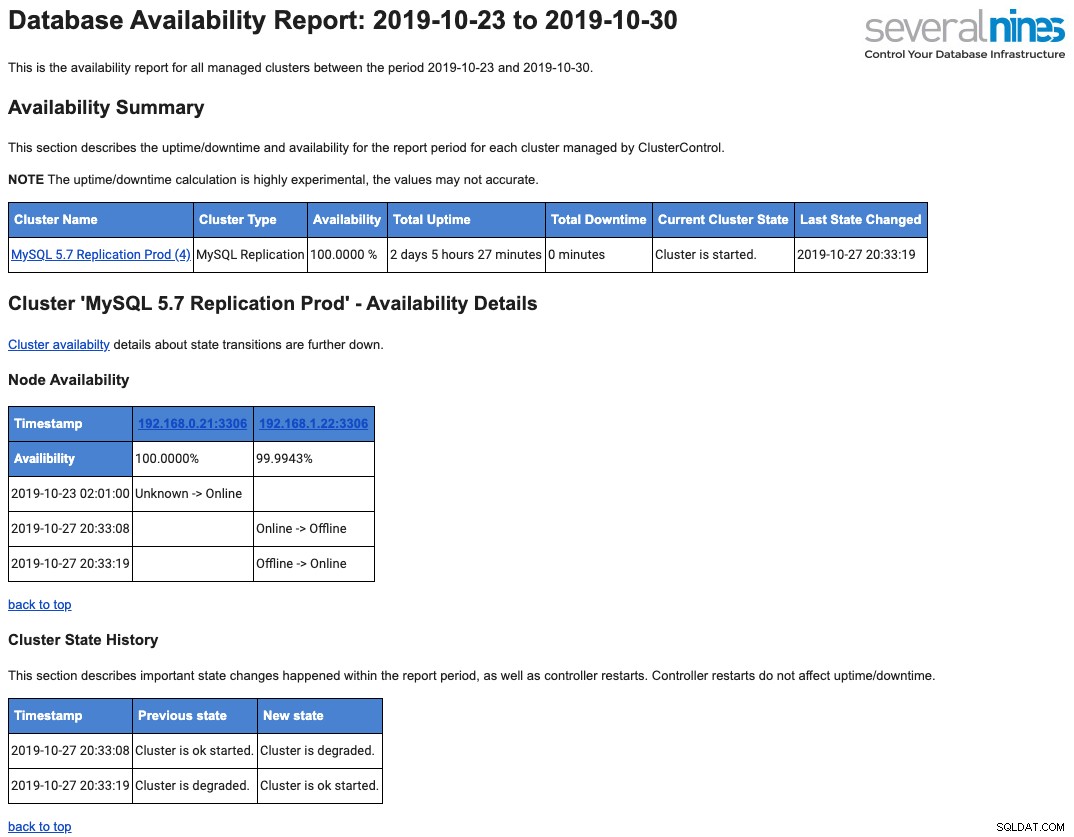
We hebben dit in detail behandeld in deze blogpost, An Overview of Database Operational Reporting in ClusterControl.
Een slaaf opnieuw synchroniseren via back-up
ClusterControl maakt het mogelijk om een slaaf (of het nu een nieuwe slaaf of een kapotte slaaf is) in te stellen via de laatste volledige of incrementele back-up. Het klinkt niet erg spannend, maar deze functie is enorm als je grote datasets van 100GB en meer hebt. Gebruikelijke praktijk bij het opnieuw synchroniseren van een slave is het streamen van een back-up van de huidige master, wat enige tijd zal duren, afhankelijk van de databasegrootte. Dit zal de master extra belasten, wat de prestaties van de master in gevaar kan brengen.
Om een slave via een back-up opnieuw te synchroniseren, kiest u de slave-node op de pagina Nodes en gaat u naar Node Actions -> Rebuild Replication Slave -> Rebuild from a backup. Alleen PITR-compatibele back-up wordt weergegeven in de vervolgkeuzelijst:
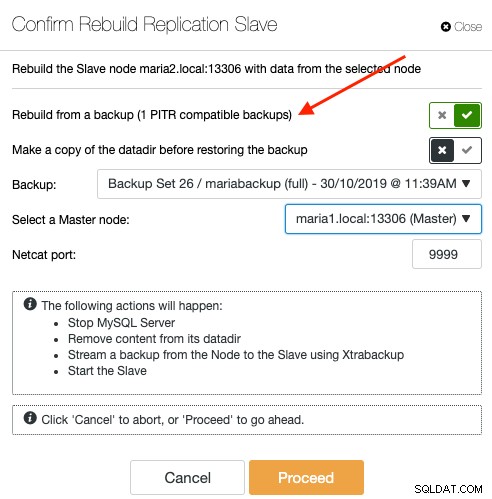
Het opnieuw synchroniseren van een slave vanaf een back-up brengt geen extra overhead met zich mee voor de master, waar ClusterControl de back-up extraheert en streamt van de back-upopslaglocatie naar de slave en uiteindelijk de replicatielink tussen de slave naar de master configureert. De slave zal later de master inhalen zodra de replicatielink tot stand is gebracht. De master blijft gedurende het hele proces onaangetast en u kunt de hele voortgang volgen onder Activiteit -> Jobs.
Bootstrap een Galera-cluster
Galera Cluster is erg populair bij het implementeren van hoge beschikbaarheid voor MySQL of MariaDB, maar de verkeerde beheeropdrachten kunnen rampzalige gevolgen hebben. Bekijk deze blogpost over hoe je een Galera-cluster opstart onder verschillende omstandigheden. Dit illustreert dat het bootstrappen van een Galera-cluster veel variabelen heeft en met uiterste zorg moet worden uitgevoerd. Anders kunt u gegevens verliezen of een gespleten brein veroorzaken. ClusterControl begrijpt de databasetopologie en weet precies wat te doen om een databasecluster correct te bootstrappen. Om een cluster te bootstrappen via ClusterControl, klikt u op Clusteracties -> Bootstrap-cluster:
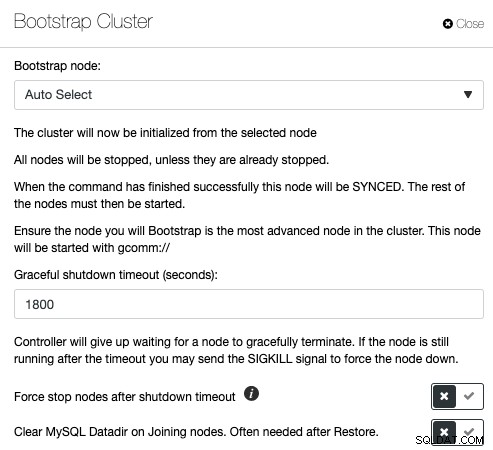
U hebt de mogelijkheid om ClusterControl automatisch het juiste bootstrap-knooppunt te laten kiezen, of een eerste bootstrap uit te voeren waarbij u een van de database-knooppunten uit de lijst kiest om het referentieknooppunt te worden en de MySQL-datadir op de joiner-knooppunten te wissen om SST van af te dwingen het bootstrap-knooppunt. Als het bootstrapping-proces mislukt, haalt ClusterControl het MySQL-foutlogboek op.
Als u een handmatige bootstrap wilt uitvoeren, kunt u ook de functie "Find Most Advanced Node" gebruiken en de clusterbootstrap-bewerking uitvoeren op de meest geavanceerde node die door ClusterControl is gerapporteerd.
Gecentraliseerde configuratie en logboekregistratie
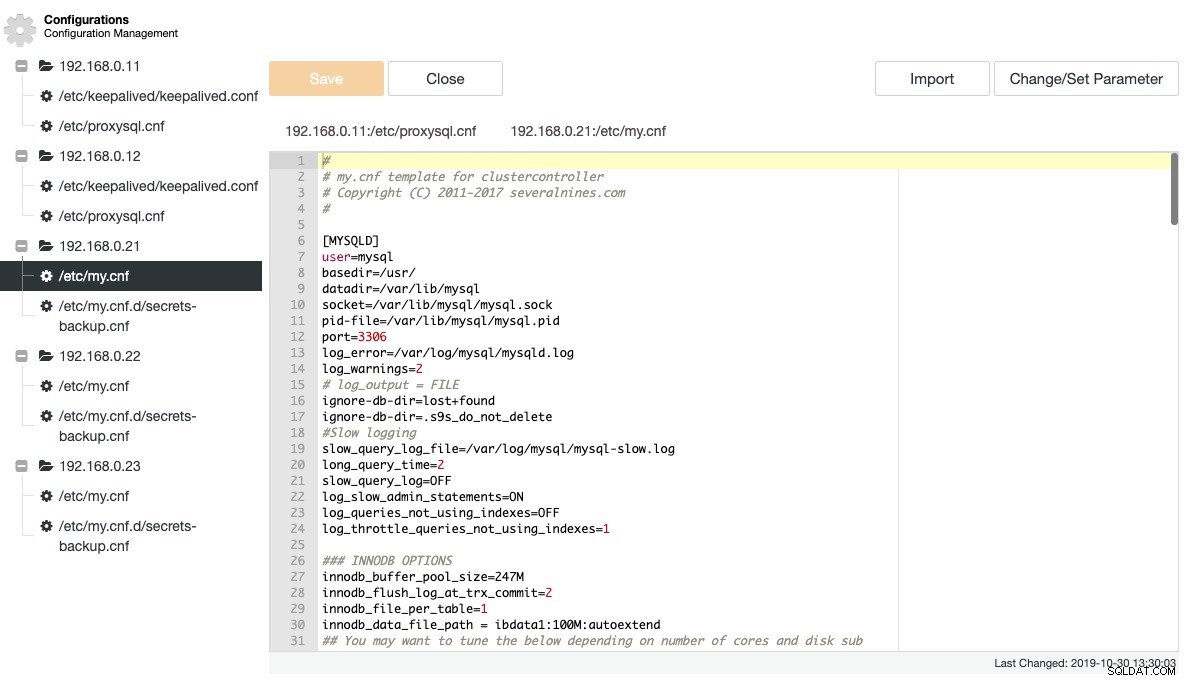
ClusterControl haalt een aantal belangrijke configuratie- en logbestanden op en geeft deze weer in een boomstructuur binnen ClusterControl. Een gecentraliseerde weergave van deze bestanden is essentieel voor het efficiënt begrijpen en oplossen van problemen met gedistribueerde databaseconfiguraties. De traditionele manier om deze bestanden te volgen/greppen is allang voorbij met ClusterControl. De volgende schermafbeelding toont de configuratiebestandsbeheerder van ClusterControl die alle gerelateerde configuratiebestanden voor dit cluster in één enkele weergave opsomt (met syntaxisaccentuering natuurlijk):
ClusterControl elimineert de herhaling bij het wijzigen van een configuratie-optie van een databasecluster. Het wijzigen van een configuratie-optie op meerdere knooppunten kan worden uitgevoerd via een enkele interface en zal dienovereenkomstig worden toegepast op het databaseknooppunt. Wanneer u op "Parameter wijzigen/instellen" klikt, kunt u de database-instanties selecteren die u wilt wijzigen en de configuratiegroep, parameter en waarde specificeren:
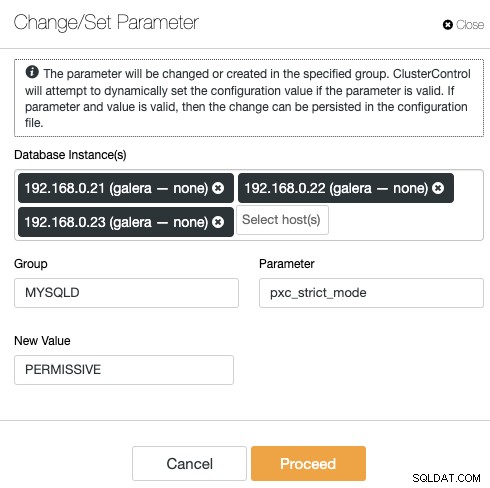
U kunt een nieuwe parameter toevoegen aan het configuratiebestand of een bestaande parameter wijzigen . De parameter wordt toegepast op de runtime van de gekozen databaseknooppunten en in het configuratiebestand als de optie het variabelevalidatieproces doorstaat. Voor sommige variabelen kan het zijn dat de server opnieuw moet worden opgestart, wat dan wordt geadviseerd door ClusterControl.
Klonen van databaseclusters
Met ClusterControl kun je snel een bestaande MySQL Galera-cluster klonen, zodat je een exacte kopie hebt van de dataset op het andere cluster. ClusterControl voert het klonen online uit, zonder enige vergrendeling of downtime naar het bestaande cluster. Het lijkt op een uitschaalbewerking voor clusters, behalve dat beide clusters onafhankelijk van elkaar zijn nadat de synchronisatie is voltooid. Het gekloonde cluster hoeft niet noodzakelijk dezelfde clustergrootte te hebben als het bestaande. We zouden kunnen beginnen met een "cluster met één knooppunt" en dit in een later stadium uitbreiden met meer databaseknooppunten.
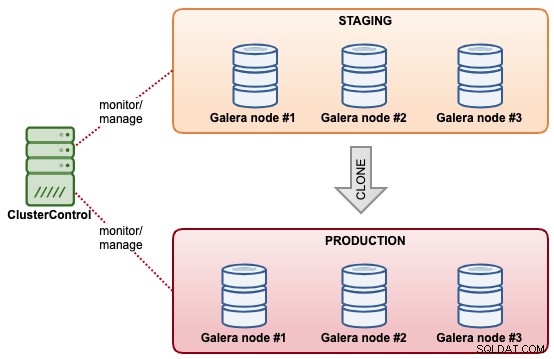
Een andere soortgelijke functie die door ClusterControl wordt aangeboden, is "Cluster maken van back-up". Deze functie is geïntroduceerd in ClusterControl 1.7.1, specifiek voor Galera Cluster- en PostgreSQL-clusters waar men een nieuw cluster kan maken van de bestaande back-up. In tegenstelling tot het klonen van clusters, veroorzaakt deze bewerking geen extra belasting voor het broncluster met de afweging dat het gekloonde cluster niet in dezelfde staat zal zijn als het broncluster.
We hebben dit onderwerp in detail behandeld in deze blogpost, Een kloon maken van uw MySQL- of PostgreSQL-databasecluster.
Fysieke back-up herstellen
De meeste hulpprogramma's voor databasebeheer staan het maken van back-ups van een database toe, en slechts een handvol daarvan ondersteunt alleen databaseherstel van logische back-ups. ClusterControl ondersteunt volledig herstel, niet alleen voor logische back-ups, maar ook voor fysieke back-ups, of het nu een volledige of incrementele back-up is. Het herstellen van een fysieke back-up vereist een aantal kritieke stappen (vooral incrementele back-ups) die in feite het voorbereiden van een back-up inhouden, het kopiëren van de voorbereide gegevens naar de gegevensdirectory, het toewijzen van de juiste toestemming/eigendom en het opstarten van het knooppunt in de juiste volgorde om de gegevensconsistentie over de hele alle leden van de cluster. ClusterControl voert al deze bewerkingen automatisch uit.
U kunt een fysieke back-up ook terugzetten op een ander knooppunt dat geen deel uitmaakt van een cluster. In ClusterControl heet de optie hiervoor "Cluster maken van back-up". U kunt beginnen met een "cluster met één knooppunt" om het herstelproces op een andere server te testen of om uw databasecluster naar een andere locatie te kopiëren.
ClusterControl ondersteunt ook het terugzetten van een externe back-up, een back-up die niet via ClusterControl is gemaakt. U hoeft alleen de back-up te uploaden naar de ClusterControl-server en het fysieke pad naar het back-upbestand op te geven bij het terugzetten. ClusterControl doet de rest.
Cluster-naar-cluster replicatie
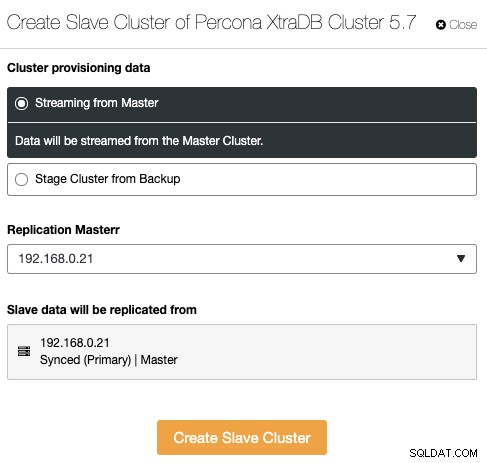
Dit is een nieuwe functie die is geïntroduceerd in ClusterControl 1.7.4. ClusterControl kan nu cluster-clusterreplicatie afhandelen en bewaken, wat in feite de asynchrone databasereplicatie tussen meerdere clustersets op meerdere geografische locaties uitbreidt. Een cluster kan worden ingesteld als een mastercluster (actief cluster dat lees-/schrijfbewerkingen verwerkt) en het slave-cluster kan worden ingesteld als een alleen-lezen cluster (standby-cluster dat ook leesbewerkingen kan verwerken). ClusterControl ondersteunt asynchrone cluster-clusterreplicatie voor Galera Cluster (binair logboek moet zijn ingeschakeld) en ook master-slave-replicatie voor PostgreSQL Streaming Replication.
Om een nieuw cluster te maken van de replica's van een ander cluster, gaat u naar Clusteracties -> Slavecluster maken:
Het resultaat van de bovenstaande implementatie wordt duidelijk weergegeven op het databaseclusterlijst-dashboard :
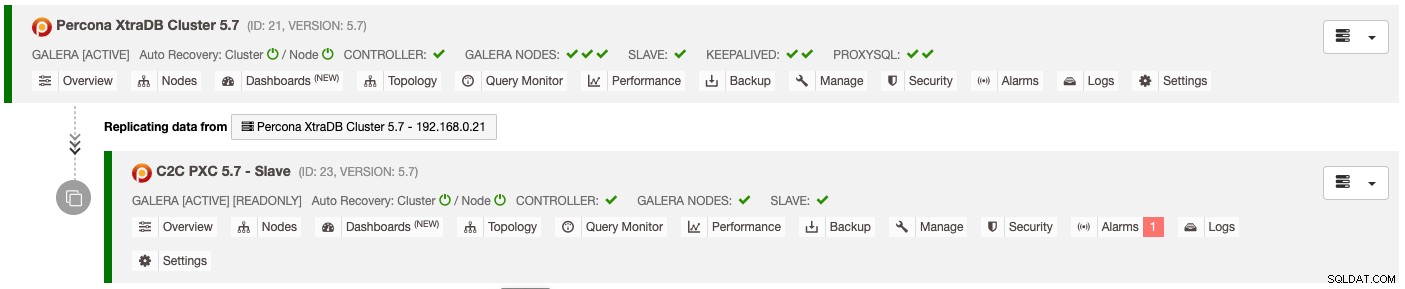
Het slave-cluster wordt automatisch geconfigureerd als alleen-lezen, repliceert vanuit het primaire cluster en fungeert als een standby-cluster. Als een ramp het primaire cluster treft en u de secundaire site wilt activeren, kiest u gewoon het menu 'Alleen-lezen uitschakelen' dat beschikbaar is onder de vervolgkeuzelijst Knooppunten -> Knooppuntacties om het als een actief cluster te promoten.