Database load balancing distribueert gelijktijdige clientverzoeken naar meerdere databaseservers om de hoeveelheid belasting op een enkele server te verminderen. Dit kan de prestaties van uw database drastisch verbeteren. Gelukkig kan MongoDB standaard meerdere verzoeken van klanten verwerken om dezelfde gegevens tegelijkertijd te lezen en te schrijven. Het gebruikt enkele concurrency-controlemechanismen en vergrendelingsprotocollen om te allen tijde de consistentie van gegevens te garanderen.
Op deze manier zorgt MongoDB er ook voor dat alle clients op elk moment een consistent beeld van gegevens krijgen. Vanwege deze ingebouwde functie voor het afhandelen van verzoeken van meerdere clients, hoeft u zich geen zorgen te maken over het toevoegen van een externe load balancer bovenop uw MongoDB-servers. Als u de prestaties van uw database toch wilt verbeteren met behulp van taakverdeling, volgen hier enkele manieren om dat te bereiken.
MongoDB verticale schaling
In eenvoudige bewoordingen betekent verticaal schalen het toevoegen van meer bronnen aan uw server om te verwerken om te laden. Zoals alle databasesystemen geeft MongoDB de voorkeur aan meer RAM- en IO-capaciteit. Dit is de eenvoudigste manier om de MongoDB-prestaties te verbeteren zonder de belasting over meerdere servers te verdelen. Verticale schaling van de MongoDB-database omvat doorgaans het vergroten van de CPU-capaciteit of schijfcapaciteit en het verhogen van de doorvoer (I/O-bewerkingen). Door meer bronnen toe te voegen, wordt uw mongo-server beter in staat om verzoeken van meerdere klanten te verwerken. Dus betere taakverdeling voor uw database.
Het nadeel van deze benadering is de technische beperking van het toevoegen van bronnen aan een enkel systeem. Ook hebben alle cloudproviders de beperkingen voor het toevoegen van nieuwe hardwareconfiguraties. Het andere nadeel van deze aanpak is een single point of failure. Bij deze aanpak worden al uw gegevens opgeslagen in één systeem, wat kan leiden tot permanent verlies van uw gegevens.
MongoDB horizontaal schalen
Horizontaal schalen verwijst naar het opdelen van uw database in delen en deze op meerdere servers opslaan. Het belangrijkste voordeel van deze aanpak is dat u direct extra servers kunt toevoegen om uw databaseprestaties te verbeteren zonder downtime. MongoDB biedt horizontale schaling door middel van sharding. MongoDB-sharding geeft extra capaciteit om de schrijfbelasting over meerdere servers (shards) te verdelen. Hier kan elke shard worden gezien als één onafhankelijke database en kan de verzameling van alle shards worden gezien als één grote logische database. Met sharding kan uw MongoDB de gegevens over meerdere servers verdelen om gelijktijdige clientverzoeken efficiënt af te handelen. Daarom verhoogt het de lees- en schrijfdoorvoer van uw database.
MongoDB Sharding
Een shard kan een enkele mongod-instantie zijn of een replicaset die de subset van de mongo-sharddatabase bevat. U kunt shard in replicaset converteren om een hoge beschikbaarheid van gegevens en redundantie te garanderen.
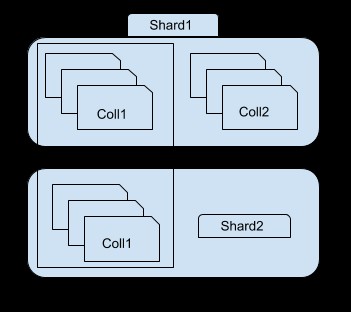
Zoals je kunt zien in de bovenstaande afbeelding, bevat shard 1 een subset van collectie 1 en hele collectie2, terwijl shard 2 alleen een andere subset van collectie1 bevat. U hebt toegang tot elke shard met behulp van de mongos-instantie. Als u bijvoorbeeld verbinding maakt met shard1-instantie, kunt u alleen een subset van collection1 zien/toegang krijgen.
Mongo's
Mongos is de queryrouter die toegang biedt tot sharded cluster voor clienttoepassingen. U kunt meerdere mongos-instanties hebben voor een betere taakverdeling. In uw productiecluster kunt u bijvoorbeeld één mongos-instantie hebben voor elke toepassingsserver. Hier kunt u nu een externe load balancer gebruiken, die het verzoek van uw toepassingsserver doorstuurt naar de juiste instantie van mongos. Zorg er bij het toevoegen van dergelijke configuraties aan uw productieserver voor dat de verbinding van elke client altijd verbinding maakt met dezelfde mongos-instantie, aangezien sommige mongo-bronnen, zoals cursors, specifiek zijn voor de mongos-instantie.
Config-servers
Config-servers slaan de configuratie-instellingen en metadata over uw cluster op. Vanaf MongoDB versie 3.4 moet u configuratieservers implementeren als replicaset. Als u sharding in een productieomgeving inschakelt, is het verplicht om drie afzonderlijke configuratieservers te gebruiken, elk op verschillende machines.
U kunt deze handleiding volgen om uw replicasetcluster om te zetten in een shard-cluster. Hier is de voorbeeldillustratie van een sharded-productiecluster:
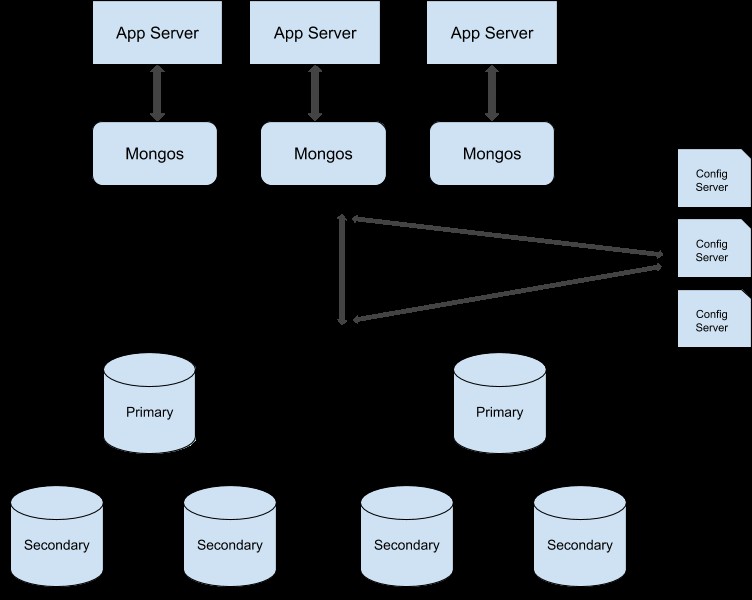
MongoDB-taakverdeling met behulp van replicatie
Soms kan MongoDB-replicatie worden gebruikt om meer verkeer van clients te verwerken en de belasting van de primaire server te verminderen. Om dit te doen, kunt u clients instrueren om van secundaire servers te lezen in plaats van van de primaire server. Dit kan de belasting van de primaire server verminderen, aangezien alle leesverzoeken van clients worden afgehandeld door secundaire servers en de primaire server alleen schrijfverzoeken afhandelt.
Hier volgt het commando om de leesvoorkeur op secundair in te stellen:
db.getMongo().setReadPref('secondary')Je kunt ook enkele tags specificeren om specifieke secondaries te targeten tijdens het afhandelen van de leesquery's.
db.getMongo().setReadPref(
"secondary", [
{ "datacenter": "APAC" },
{ "region": "East"},
{}
])Hier probeert MongoDB het secundaire knooppunt te vinden met de datacenter-tagwaarde als APAC. Indien gevonden, zal Mongo de leesverzoeken van alle secundairen bedienen met tag datacenter:"APAC". Indien niet gevonden, zal Mongo proberen om secundairen te vinden met de tag regio:“Oost”. Als er nog steeds geen secondaries zijn gevonden, werkt {} standaard en zal Mongo de verzoeken van alle in aanmerking komende secondaries behandelen.
Deze benadering voor taakverdeling wordt echter niet aanbevolen om de leesdoorvoer te verhogen. Omdat elke andere leesvoorkeursmodus dan primair oude gegevens kan retourneren in het geval van recente schrijfupdates op de primaire server. Gewoonlijk zal de primaire server enige tijd nodig hebben om de schrijfverzoeken te verwerken en de wijzigingen door te geven aan secundaire servers. Als iemand gedurende deze tijd een leesbewerking op dezelfde gegevens aanvraagt, retourneert de secundaire server verouderde gegevens omdat deze niet synchroon lopen met de primaire server. U kunt deze aanpak gebruiken als uw toepassing veel leesbewerkingen nodig heeft in vergelijking met schrijfbewerkingen.
Conclusie
Aangezien MongoDB zelf gelijktijdige verzoeken kan verwerken, is het niet nodig om een load balancer toe te voegen aan uw MongoDB-cluster. Voor de taakverdeling van de clientaanvragen kunt u kiezen tussen verticale schaling of horizontale schaling, aangezien het niet raadzaam is om secundaire schalen te gebruiken om uw lees- en schrijfbewerkingen uit te schalen. Verticaal schalen kan de technische limieten bereiken, zoals hierboven besproken. Daarom is het geschikt voor kleinschalige toepassingen. Voor grote toepassingen is horizontaal schalen door middel van sharding de beste benadering voor het balanceren van de lees- en schrijfbewerkingen.