Als onderdeel van het leren van de Oracle SQL-zelfstudie, vindt u hier goede details over de groep per orakel
Groepsfuncties, in tegenstelling tot functies met één waarde, werken op de reeks rijen en retourneren één rij per groep. De reeks rijen kan een hele tabel zijn of de tabel opgesplitst in groepen
Typen groepsfuncties in Oracle zijn:
| AVG([Distinct/all] n) | Alleen numerieke gegevenstypen. De gemiddelde waarde van de kolom n negeert null-waarden |
| COUNT({*/[Distinct/all]expr}) | Het is alleen een groepsfunctie die null-waarden bevat. Het telt het aantal rijen in de select-instructie dat voldoet aan de where-clausule. Count(*) bevat alle null- en dubbele waarden |
| MAX([Distinct/all] expr) | Het kan met elk gegevenstype worden gebruikt. Het geeft de maximale waarde van expr en negeert null-waarden |
| MIN([Distinct/all] expr) | Het kan met elk datatype worden gebruikt. . Het geeft een minimumwaarde van expr waarbij nulwaarden worden genegeerd |
| STDDEV([Distinct/all] n) | Alleen numerieke gegevenstypen. Het geeft een standaarddeviatie van n negeert null-waarden |
| SUM ([Distinct/all] n) | Alleen numerieke gegevenstypen en mogen geen andere rekenkundige operatoren in de functie hebben. Het levert de som van n negeert null-waarden |
| VARIANTIE([Distinct/all] n) | Alleen numerieke gegevenstypen. Het geeft variantie van n negeert null-waarden |
Syntaxis:
SELECT col1, col2, … col_n, aggregate_function (aggregate_expression) FROM tables [WHERE conditions] GROUP BY col1, col2, … col_n Having group condition;
Oracle-server heeft de volgende stappen uitgevoerd
- Eerst worden de rijen geselecteerd op basis van de where-clausule
- Rijen zijn gegroepeerd
- De groepsfunctie wordt toegepast op elke groep
- De groep die overeenkomt met het criterium in de hebbende clausule wordt weergegeven
Dus de WHERE-component wordt eerst geëvalueerd (beperkt de queryresultaten), vervolgens de GROUP BY-component (groepeert de resultaten van de WHERE), en vervolgens de HAVING-component (verder beperkt de resultaten door de geretourneerde groepen te beperken).
Enkele belangrijke punten over groeperen op orakel
(1) GROUP BY:Splitst de resultaten van groepsfuncties uit één grote gegevenstabel op in kleinere logische groepen.
(2) WHERE-clausule kan een groep niet beperken, dus gebruik de HAVING-clausule.
(3) Gebruik niet de kolomalias in de GROUP BY-clausule.
(4) HAVING:beperkt de weergave van groepen tot degenen die de gespecificeerde voorwaarden "hebben".
(5) Met de NVL-functie kan een GROUP BY-functie null-waarden in de berekening opnemen.
(6) Elke kolom of uitdrukking in de selectielijst die geen aggregatiefunctie is, moet in de group by-clausule staan
Voorbeelden van groepsfuncties in Oracle
Laten we eerst de voorbeeldtabellen maken en dan de groep op oracle sql proberen
CREATE TABLE "DEPT"
( "DEPTNO" NUMBER(2,0),
"DNAME" VARCHAR2(14),
"LOC" VARCHAR2(13),
CONSTRAINT "PK_DEPT" PRIMARY KEY ("DEPTNO")
)
CREATE TABLE "EMP"
( "EMPNO" NUMBER(4,0),
"ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9),
"MGR" NUMBER(4,0),
"HIREDATE" DATE,
"SAL" NUMBER(7,2),
"COMM" NUMBER(7,2),
"DEPTNO" NUMBER(2,0),
CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO"),
CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO")
REFERENCES "DEPT" ("DEPTNO") ENABLE
);
insert into DEPT values(10, 'ACCOUNTING', 'NEW YORK');
insert into dept values(20, 'RESEARCH', 'DALLAS');
insert into dept values(30, 'RESEARCH', 'DELHI');
insert into dept values(40, 'RESEARCH', 'MUMBAI');
insert into emp values( 7698, 'Blake', 'MANAGER', 7839, to_date('1-5-2007','dd-mm-yyyy'), 2850, null, 10 );
insert into emp values( 7782, 'Clark', 'MANAGER', 7839, to_date('9-6-2008','dd-mm-yyyy'), 2450, null, 10 );
insert into emp values( 7788, 'Scott', 'ANALYST', 7566, to_date('9-6-2012','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7789, 'TPM', 'ANALYST', 7566, to_date('9-6-2017','dd-mm-yyyy'), 3000, null, null );
insert into emp values( 7560, 'T1OM', 'ANALYST', 7567, to_date('9-7-2017','dd-mm-yyyy'), 4000, null, 20 );
insert into emp values( 7790, 'TOM', 'ANALYST', 7567, to_date('9-7-2017','dd-mm-yyyy'), 4000, null, null );
commit;
Select * from emp; 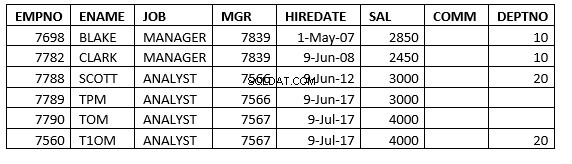
Enkele kolom
Select dept , avg(sal) from emp group by dept;
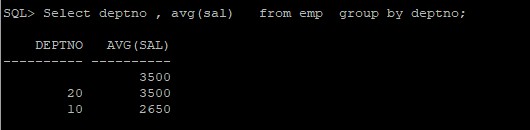
Meerdere kolommen
Select deptno ,job, sum(sal) from emp group by deptno,job

Telfunctie
SELECT dept, COUNT(*) AS "Np of employees" FROM emp WHERE sal < 15000
GROUP BY dept;
Min Functie
SELECT dept, MIN(sal) AS "Lowest salary" FROM emp
GROUP BY dept;
Ik hoop dat je dit artikel leuk vindt
Gerelateerde artikelen
Analytische functies in Oracle:Oracle Analytische functies berekenen een geaggregeerde waarde op basis van een groep rijen door gebruik te maken van over partitie door Oracle-clausule, ze verschillen van geaggregeerde functies
rang in Oracle:RANK, DENSE_RANK en ROW_NUMBER zijn orakel-analytisch functie die wordt gebruikt om rijen te rangschikken in de groep rijen genaamd window
Lead-functie in oracle:bekijk de LAG-functie in Oracle &Lead-functie in Oracle, hoe ze te gebruiken in analytische query's en hoe het werkt in Oracle sql
Top-N-query's in Oracle :Bekijk deze pagina over het verkennen van de verschillende manieren om Top-N-query's in Oracle en paginering in Oracle-query Oracle-database te bereiken.