In mijn vorige artikel heb ik een nieuwe serie over vergrendelingen afgetrapt door uit te leggen wat ze zijn, waarom ze nodig zijn en hoe ze werken, en ik raad je ten zeerste aan dat artikel vóór dit artikel te lezen. In dit artikel ga ik de FGCB_ADD_REMOVE-vergrendeling bespreken en laten zien hoe dit een knelpunt kan zijn.
Wat is de FGCB_ADD_REMOVE vergrendeling?
De meeste vergrendelingsklassenamen zijn rechtstreeks gekoppeld aan de gegevensstructuur die ze beschermen. De FGCB_ADD_REMOVE-latch beschermt een gegevensstructuur die een FGCB wordt genoemd, of File Group Control Block, en er zal een van deze grendels zijn voor elke online bestandsgroep van elke online database in een SQL Server-instantie. Telkens wanneer een bestand in een bestandsgroep wordt toegevoegd, verwijderd, gegroeid of verkleind, moet de vergrendeling worden verkregen in EX-modus, en bij het uitzoeken van het volgende bestand waaruit moet worden toegewezen, moet de vergrendeling worden verkregen in SH-modus om eventuele bestandsgroepwijzigingen te voorkomen. (Houd er rekening mee dat matetoewijzingen voor een bestandsgroep op een round-robin-basis worden uitgevoerd via de bestanden in de bestandsgroep, en houd ook rekening met proportionele vulling , wat ik hier uitleg.)
Hoe wordt de vergrendeling een knelpunt?
Het meest voorkomende scenario wanneer deze vergrendeling een knelpunt wordt, is als volgt:
- Er is een database met één bestand, dus alle toewijzingen moeten uit dat ene gegevensbestand komen
- De autogrow-instelling voor het bestand is erg klein (vergeet niet dat vóór SQL Server 2016 de standaard autogrow-instelling voor gegevensbestanden 1 MB was!)
- Er zijn veel gelijktijdige bewerkingen waarvoor ruimte moet worden toegewezen (bijvoorbeeld een constante werkbelasting van veel clientverbindingen)
In dit geval, ook al is er maar één bestand, moet een thread die een toewijzing vereist nog steeds de FGCB_ADD_REMOVE-vergrendeling in SH-modus verwerven. Het zal dan proberen om vanuit het enkele gegevensbestand toe te wijzen, zich realiseren dat er geen ruimte is en vervolgens de vergrendeling verkrijgen in de EX-modus, zodat het het bestand vervolgens kan laten groeien.
Laten we ons voorstellen dat acht threads die op acht afzonderlijke planners draaien allemaal tegelijkertijd proberen toe te wijzen, en dat ze allemaal beseffen dat er geen ruimte in het bestand is, dus moeten ze het laten groeien. Ze zullen elk proberen de grendel in de EX-modus te verkrijgen. Slechts één van hen zal het kunnen verwerven en het zal doorgaan met het groeien van het bestand en de anderen zullen moeten wachten, met een wachttype van LATCH_EX en een bronbeschrijving van FGCB_ADD_REMOVE plus het geheugenadres van de vergrendeling.
De zeven wachtende threads bevinden zich in de first-in-first-out (FIFO) wachtrij van de latch. Wanneer de thread die de bestandsgroei uitvoert, klaar is, laat deze de vergrendeling los en verleent deze aan de eerste wachtende thread. Deze nieuwe eigenaar van de vergrendeling gaat het bestand laten groeien en ontdekt dat het al is gegroeid en dat er niets aan te doen is. Dus het laat de grendel los en verleent deze aan de volgende wachtende thread. En zo verder.
De zeven wachtende threads wachtten allemaal op de vergrendeling in de EX-modus, maar deden uiteindelijk niets nadat ze de vergrendeling hadden gekregen, dus alle zeven threads verspilden in wezen verstreken tijd, waarbij de hoeveelheid tijd die werd verspild een klein beetje toenam voor elke thread, hoe verder naar beneden de FIFO-wachtrij was het.
De bottleneck laten zien
Nu ga ik je het exacte scenario hierboven laten zien, met behulp van uitgebreide evenementen. Ik heb een database met één bestand gemaakt met een kleine autogrow-instelling en honderden gelijktijdige verbindingen die eenvoudig gegevens in een tabel invoegen.
Ik kan de volgende uitgebreide evenementsessie gebruiken om te zien wat er aan de hand is:
-- Drop the session if it exists.
IF EXISTS
(
SELECT * FROM sys.server_event_sessions
WHERE [name] = N'FGCB_ADDREMOVE'
)
BEGIN
DROP EVENT SESSION [FGCB_ADDREMOVE] ON SERVER;
END
GO
CREATE EVENT SESSION [FGCB_ADDREMOVE] ON SERVER
ADD EVENT [sqlserver].[database_file_size_change]
(WHERE [file_type] = 0), -- data files only
ADD EVENT [sqlserver].[latch_suspend_begin]
(WHERE [class] = 48 AND [mode] = 4), -- EX mode
ADD EVENT [sqlserver].[latch_suspend_end]
(WHERE [class] = 48 AND [mode] = 4) -- EX mode
ADD TARGET [package0].[ring_buffer]
WITH (TRACK_CAUSALITY = ON);
GO
-- Start the event session
ALTER EVENT SESSION [FGCB_ADDREMOVE]
ON SERVER STATE = START;
GO De sessie houdt bij wanneer een thread de wachtrij van de vergrendeling binnenkomt, wanneer deze de wachtrij verlaat (d.w.z. wanneer de vergrendeling wordt verleend) en wanneer een gegevensbestand groeit. Door causaliteit te volgen, kunnen we een tijdlijn zien van de acties van elke thread.
Met SQL Server Management Studio kan ik de optie Live-gegevens bekijken voor de uitgebreide gebeurtenissessie selecteren en alle uitgebreide gebeurtenisactiviteiten bekijken. Als u hetzelfde wilt doen, klikt u in het Live Data-venster met de rechtermuisknop op een van de kolomnamen bovenaan en wijzigt u de geselecteerde kolommen in zoals hieronder:
Ik liet de werklast een paar minuten lopen om een stabiele toestand te bereiken en zag toen een perfect voorbeeld van het scenario dat ik hierboven heb beschreven:
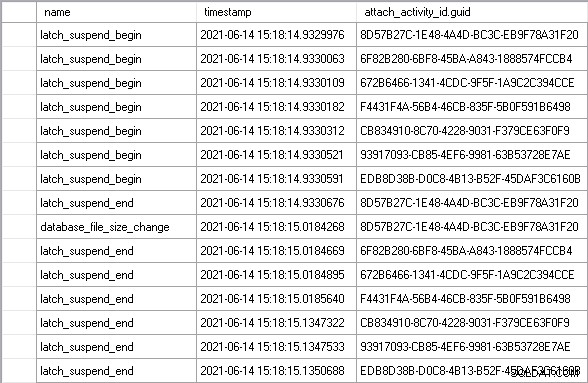
De attach_activity_id.guid gebruiken waarden om verschillende threads te identificeren, kunnen we zien dat zeven threads binnen 61,5 microseconden beginnen te wachten op de vergrendeling. De thread met de GUID-waarde die begint met 8D57 verwerft de vergrendeling in de EX-modus (de latch_suspend_end event) en laat het bestand dan onmiddellijk groeien (de database_file_size_change evenement). De 8D57-thread geeft vervolgens de vergrendeling vrij en verleent deze in EX-modus aan de 6F82-thread, die 85 milliseconden wachtte. Het heeft niets te doen, dus het verleent de grendel aan de 672B-draad. En zo verder, totdat de EDB8-thread de vergrendeling krijgt, na 202 milliseconden te hebben gewacht.
In totaal wachtten de zes threads die zonder reden wachtten bijna 1 seconde. Een deel van die tijd is signaalwachttijd, waarbij, hoewel de thread de vergrendeling heeft gekregen, deze nog steeds naar de top van de uitvoerbare wachtrij van de planner moet gaan voordat deze op de processor kan komen en code kan uitvoeren. Je zou kunnen zeggen dat dit geen redelijke maatstaf is voor de tijd die wordt besteed aan het wachten op de vergrendeling, maar dat is het absoluut, omdat de signaalwachttijd niet zou zijn gemaakt als de thread niet had hoeven wachten in de eerste plaats.
Verder zou je denken dat een vertraging van 200 milliseconden niet zo veel is, maar het hangt allemaal af van de performance service level agreements voor de betreffende workload. We hebben meerdere klanten met een hoog volume. Als een batch meer dan 200 milliseconden nodig heeft om uit te voeren, is het niet toegestaan op het productiesysteem!
Samenvatting
Als je de wachttijden op je server in de gaten houdt en je merkt dat LATCH_EX een van de beste wachttijden is, kun je de code in dit bericht gebruiken om te kijken of FGCB_ADD_REMOVE een van de boosdoeners is.
De eenvoudigste manier om ervoor te zorgen dat uw werklast geen FGCB_ADD_REMOVE-knelpunt raakt, is door ervoor te zorgen dat er geen autogrow-instellingen voor gegevensbestanden zijn die zijn geconfigureerd met de pre-SQL Server 2016-standaardinstellingen. In de sys.master_files bekijken, wordt de standaard 1 MB weergegeven als een gegevensbestand (type_desc kolom ingesteld op ROWS) met de is_percent_growth kolom ingesteld op 0 en de groeikolom ingesteld op 128.
Het geven van een aanbeveling voor wat autogrow zou moeten zijn, is een heel andere discussie, maar nu weet u een mogelijke prestatie-impact als u de standaardinstellingen in eerdere versies niet wijzigt.