Korte samenvatting
- De prestaties van de methode voor subquery's zijn afhankelijk van de gegevensdistributie.
- De prestaties van voorwaardelijke aggregatie zijn niet afhankelijk van de gegevensdistributie.
De methode voor subquery's kan sneller of langzamer zijn dan voorwaardelijke aggregatie, dit hangt af van de gegevensdistributie.
Natuurlijk, als de tabel een geschikte index heeft, zullen subquery's er waarschijnlijk van profiteren, omdat index het mogelijk zou maken om alleen het relevante deel van de tabel te scannen in plaats van de volledige scan. Het is onwaarschijnlijk dat het hebben van een geschikte index de voorwaardelijke aggregatiemethode aanzienlijk ten goede zal komen, omdat het toch de volledige index zal scannen. Het enige voordeel zou zijn als de index smaller is dan de tabel en de engine minder pagina's in het geheugen hoeft in te lezen.
Als u dit weet, kunt u beslissen welke methode u kiest.
Eerste test
Ik heb een grotere testtabel gemaakt, met 5M rijen. Er waren geen indexen op de tafel. Ik heb de IO- en CPU-statistieken gemeten met SQL Sentry Plan Explorer. Ik gebruikte SQL Server 2014 SP1-CU7 (12.0.4459.0) Express 64-bit voor deze tests.
Inderdaad, uw oorspronkelijke zoekopdrachten gedroegen zich zoals u beschreef, d.w.z. subquery's waren sneller, ook al waren de uitlezingen 3 keer hoger.
Na een paar pogingen op een tabel zonder index heb ik je voorwaardelijke aggregaat herschreven en variabelen toegevoegd om de waarde van DATEADD vast te houden uitdrukkingen.
De totale tijd werd aanzienlijk sneller.
Daarna heb ik SUM vervangen met COUNT en het werd weer een beetje sneller.
Voorwaardelijke aggregatie werd immers vrijwel net zo snel als subquery's.
Verwarm de cache (CPU=375)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Subquery's (CPU=1031)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt
OPTION (RECOMPILE);
Oorspronkelijke voorwaardelijke aggregatie (CPU=1641)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Voorwaardelijke aggregatie met variabelen (CPU=1078)
DECLARE @VarYear1 datetime = DATEADD(year,-1,GETDATE());
DECLARE @VarYear10 datetime = DATEADD(year,-10,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear1
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > @VarYear10
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Voorwaardelijke aggregatie met variabelen en COUNT in plaats van SUM (CPU=1062)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear1
THEN 1 ELSE NULL END) AS last_year_cnt,
COUNT(CASE WHEN datesent > @VarYear10
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);

Op basis van deze resultaten vermoed ik dat CASE aangeroepen DATEADD voor elke rij, terwijl WHERE was slim genoeg om het een keer uit te rekenen. Plus COUNT is een klein beetje efficiënter dan SUM .
Uiteindelijk is voorwaardelijke aggregatie slechts iets langzamer dan subquery's (1062 versus 1031), misschien omdat WHERE is een beetje efficiënter dan CASE op zichzelf, en bovendien, WHERE filtert nogal wat rijen uit, dus COUNT hoeft minder rijen te verwerken.
In de praktijk zou ik voorwaardelijke aggregatie gebruiken, omdat ik dat aantal reads belangrijker vind. Als uw tabel klein is om in de bufferpool te passen en te blijven, zal elke vraag snel zijn voor de eindgebruiker. Maar als de tabel groter is dan het beschikbare geheugen, verwacht ik dat het lezen van de schijf subquery's aanzienlijk zou vertragen.
Tweede test
Aan de andere kant is het ook belangrijk om de rijen zo vroeg mogelijk uit te filteren.
Hier is een kleine variatie van de test, die het aantoont. Hier stel ik de drempel in op GETDATE() + 100 jaar, om er zeker van te zijn dat geen enkele rij aan de filtercriteria voldoet.
Verwarm de cache (CPU=344)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Subquery's (CPU=500)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,100,GETDATE())
) last_year_cnt
OPTION (RECOMPILE);
Oorspronkelijke voorwaardelijke aggregatie (CPU=937)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,100,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Voorwaardelijke aggregatie met variabelen (CPU=750)
DECLARE @VarYear100 datetime = DATEADD(year,100,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear100
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Voorwaardelijke aggregatie met variabelen en COUNT in plaats van SUM (CPU=750)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear100
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
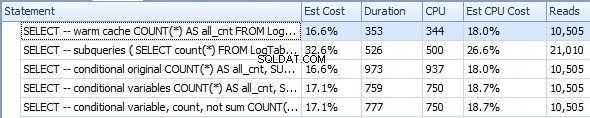
Hieronder staat een plan met subquery's. Je kunt zien dat er 0 rijen in de Stream Aggregate zijn gegaan in de tweede subquery, ze zijn allemaal uitgefilterd bij de stap Tabelscan.
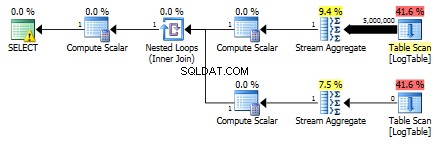
Als gevolg hiervan zijn subquery's weer sneller.
Derde toets
Hier heb ik de filtercriteria van de vorige test gewijzigd:alle > werden vervangen door < . Als gevolg hiervan wordt de voorwaardelijke COUNT telde alle rijen in plaats van geen. Verrassing, verrassing! Voorwaardelijke aggregatiequery duurde dezelfde 750 ms, terwijl subquery's 813 werden in plaats van 500.

Hier is het plan voor subquery's:
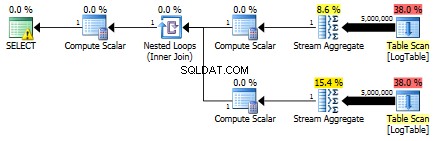
Kunt u mij een voorbeeld geven waarbij voorwaardelijke aggregatie met name beter presteert dan de subquery-oplossing?
Hier is het. De prestaties van de subquery-methode zijn afhankelijk van de gegevensdistributie. De prestaties van voorwaardelijke aggregatie zijn niet afhankelijk van de gegevensdistributie.
De methode voor subquery's kan sneller of langzamer zijn dan voorwaardelijke aggregatie, dit hangt af van de gegevensdistributie.
Als u dit weet, kunt u beslissen welke methode u kiest.
Bonusdetails
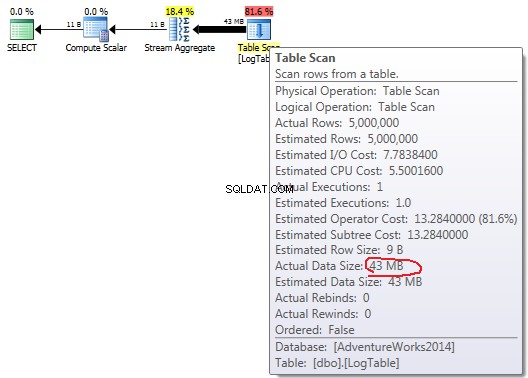
Als u met de muis over de Table Scan . gaat operator kunt u de Actual Data Size . zien in verschillende varianten.
- Eenvoudig
COUNT(*):
- Voorwaardelijke aggregatie:
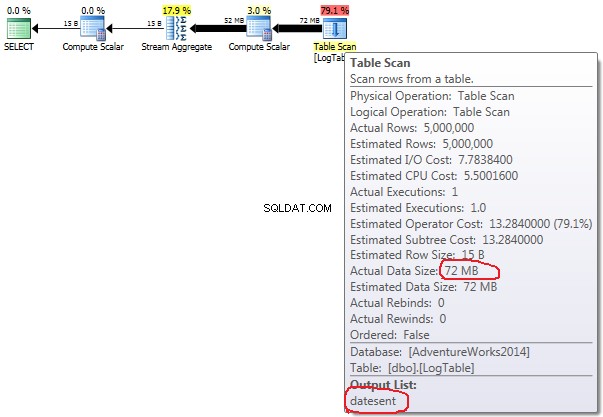
- Subquery in test 2:
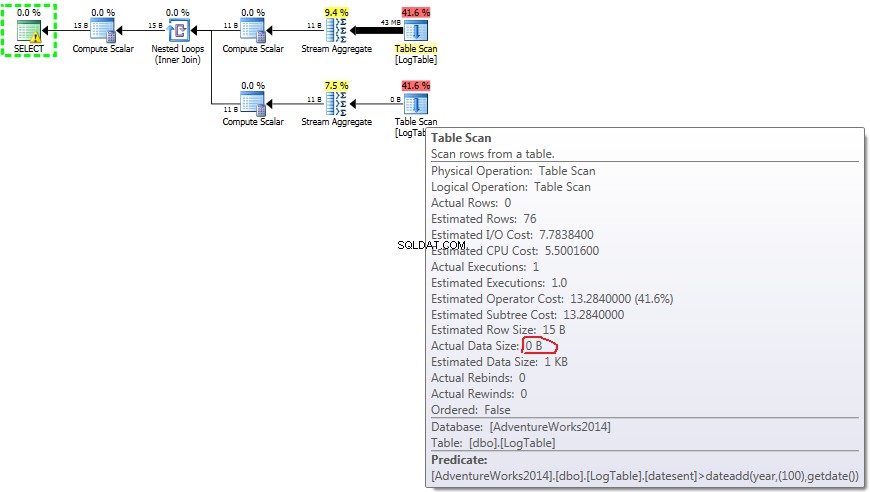
- Subquery in test 3:
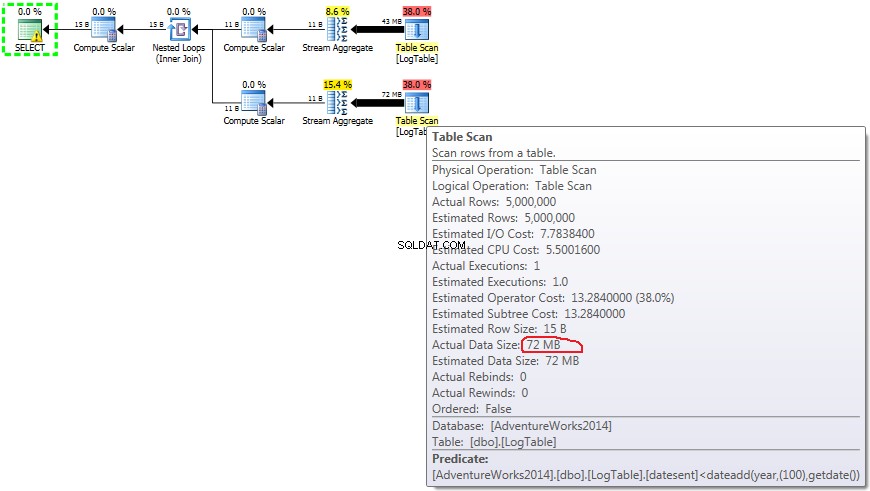
Nu wordt duidelijk dat het verschil in prestaties waarschijnlijk wordt veroorzaakt door het verschil in de hoeveelheid gegevens die door het plan stroomt.
In het geval van eenvoudige COUNT(*) er is geen Output list (er zijn geen kolomwaarden nodig) en de gegevensgrootte is het kleinst (43 MB).
Bij voorwaardelijke aggregatie verandert dit bedrag niet tussen test 2 en 3, het is altijd 72MB. Output list heeft één kolom datesent .
In het geval van subquery's, is dit aantal wel veranderen afhankelijk van de gegevensdistributie.