De meeste databases zouden externe sleutels moeten gebruiken om waar mogelijk referentiële integriteit (RI) af te dwingen. Deze beslissing houdt echter meer in dan alleen maar besluiten om FK-beperkingen te gebruiken en deze te creëren. Er zijn een aantal overwegingen waarmee u rekening moet houden om ervoor te zorgen dat uw database zo soepel mogelijk werkt.
Dit artikel behandelt een dergelijke overweging die niet veel publiciteit krijgt:Om blokkering te minimaliseren , moet u goed nadenken over de indexen die worden gebruikt om uniciteit af te dwingen aan de bovenliggende kant van die externe-sleutelrelaties.
Dit geldt ongeacht of u vergrendeling . gebruikt read commit of de versioning-based lees vastgelegde snapshot-isolatie (RCSI). Beide kunnen worden geblokkeerd wanneer relaties met externe sleutels worden gecontroleerd door de SQL Server-engine.
Onder snapshot-isolatie (SI) is er een extra waarschuwing. Hetzelfde essentiële probleem kan leiden tot onverwachte (en aantoonbaar onlogische) transactiefouten vanwege duidelijke update-conflicten.
Dit artikel bestaat uit twee delen. Het eerste deel kijkt naar het blokkeren van externe sleutels onder locking read commit en read commit snapshot isolation. Het tweede deel behandelt gerelateerde update-conflicten onder snapshot-isolatie.
1. Buitenlandse sleutelcontroles blokkeren
Laten we eerst eens kijken hoe indexontwerp van invloed kan zijn wanneer blokkering optreedt als gevolg van externe sleutelcontroles.
De volgende demo moet worden uitgevoerd onder read commit isolatie. Voor SQL Server is de standaard locking read commit; Azure SQL Database gebruikt RCSI als standaard. Voel je vrij om te kiezen wat je wilt, of voer de scripts één keer uit voor elke instelling om voor jezelf te verifiëren dat het gedrag hetzelfde is.
-- Use locking read committed
ALTER DATABASE CURRENT
SET READ_COMMITTED_SNAPSHOT OFF;
-- Or use row-versioning read committed
ALTER DATABASE CURRENT
SET READ_COMMITTED_SNAPSHOT ON; Maak twee tabellen die verbonden zijn door een refererende sleutelrelatie:
CREATE TABLE dbo.Parent
(
ParentID integer NOT NULL,
ParentNaturalKey varchar(10) NOT NULL,
ParentValue integer NOT NULL,
CONSTRAINT [PK dbo.Parent ParentID]
PRIMARY KEY (ParentID),
CONSTRAINT [AK dbo.Parent ParentNaturalKey]
UNIQUE (ParentNaturalKey)
);
CREATE TABLE dbo.Child
(
ChildID integer NOT NULL,
ChildNaturalKey varchar(10) NOT NULL,
ChildValue integer NOT NULL,
ParentID integer NULL,
CONSTRAINT [PK dbo.Child ChildID]
PRIMARY KEY (ChildID),
CONSTRAINT [AK dbo.Child ChildNaturalKey]
UNIQUE (ChildNaturalKey),
CONSTRAINT [FK dbo.Child to dbo.Parent]
FOREIGN KEY (ParentID)
REFERENCES dbo.Parent (ParentID)
); Voeg een rij toe aan de bovenliggende tabel:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
DECLARE
@ParentID integer = 1,
@ParentNaturalKey varchar(10) = 'PNK1',
@ParentValue integer = 100;
INSERT dbo.Parent
(
ParentID,
ParentNaturalKey,
ParentValue
)
VALUES
(
@ParentID,
@ParentNaturalKey,
@ParentValue
);
Op een tweede verbinding , update het niet-sleutel bovenliggende tabelkenmerk ParentValue binnen een transactie, maar niet verplichten het is gewoon nog:
DECLARE
@ParentID integer = 1,
@ParentNaturalKey varchar(10) = 'PNK1',
@ParentValue integer = 200;
BEGIN TRANSACTION;
UPDATE dbo.Parent
SET ParentValue = @ParentValue
WHERE ParentID = @ParentID; Voel je vrij om het update-predikaat te schrijven met de natuurlijke sleutel als je dat liever hebt, het maakt geen verschil voor onze huidige doeleinden.
Terug op de eerste verbinding , probeer een onderliggend record toe te voegen:
DECLARE
@ChildID integer = 101,
@ChildNaturalKey varchar(10) = 'CNK1',
@ChildValue integer = 999,
@ParentID integer = 1;
INSERT dbo.Child
(
ChildID,
ChildNaturalKey,
ChildValue,
ParentID
)
VALUES
(
@ChildID,
@ChildNaturalKey,
@ChildValue,
@ParentID
); Deze insert-instructie zal blokkeren , of je nu kiest voor vergrendelen of versiebeheer lees toegewijd isolatie voor deze test.
Uitleg
Het uitvoeringsplan voor het invoegen van het onderliggende record is:
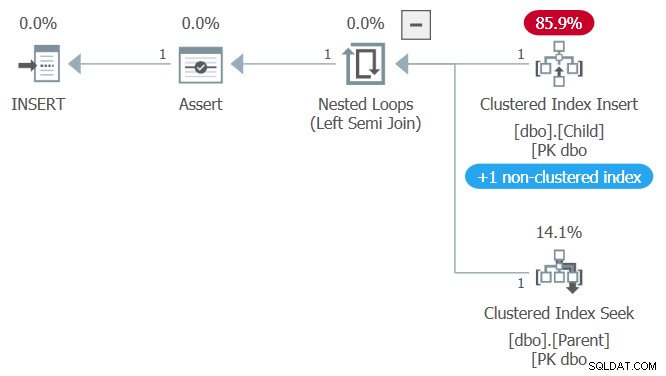
Na het invoegen van de nieuwe rij in de onderliggende tabel, controleert het uitvoeringsplan de externe-sleutelbeperking. De controle wordt overgeslagen als het ingevoegde ouder-ID null is (bereikt via een 'pass through'-predikaat op de linker semi-join). In het huidige geval is het toegevoegde ouder-ID niet null, dus de externe sleutelcontrole is uitgevoerd.
SQL Server verifieert de externe-sleutelbeperking door te zoeken naar een overeenkomende rij in de bovenliggende tabel. De engine kan geen row-versioning gebruiken om dit te doen — het moet er zeker van zijn dat de gegevens die het controleert de laatste vastgelegde gegevens zijn , niet een of andere oude versie. De engine zorgt hiervoor door een interne READCOMMITTEDLOCK . toe te voegen tabelhint naar de externe sleutelcontrole op de bovenliggende tabel.
Het eindresultaat is dat SQL Server probeert een gedeelde vergrendeling op de overeenkomstige rij in de bovenliggende tabel te verkrijgen, die blokkeert omdat de andere sessie een incompatibele exclusieve modusvergrendeling heeft vanwege de nog niet uitgevoerde update.
Voor alle duidelijkheid:de interne vergrendelingshint is alleen van toepassing op de externe sleutelcontrole. De rest van het plan gebruikt nog steeds RCSI, als je die implementatie van het read-commit isolatieniveau hebt gekozen.
De blokkering vermijden
Voer de open transactie uit of draai deze terug in de tweede sessie, en reset vervolgens de testomgeving:
DROP TABLE IF EXISTS
dbo.Child, dbo.Parent; Maak de testtabellen opnieuw, maar deze keer in plaats van de standaardwaarden te accepteren, kiezen we ervoor om de primaire sleutel niet-geclusterd te maken en de unieke beperking geclusterd:
CREATE TABLE dbo.Parent
(
ParentID integer NOT NULL,
ParentNaturalKey varchar(10) NOT NULL,
ParentValue integer NOT NULL,
CONSTRAINT [PK dbo.Parent ParentID]
PRIMARY KEY NONCLUSTERED (ParentID),
CONSTRAINT [AK dbo.Parent ParentNaturalKey]
UNIQUE CLUSTERED (ParentNaturalKey)
);
CREATE TABLE dbo.Child
(
ChildID integer NOT NULL,
ChildNaturalKey varchar(10) NOT NULL,
ChildValue integer NOT NULL,
ParentID integer NULL,
CONSTRAINT [PK dbo.Child ChildID]
PRIMARY KEY NONCLUSTERED (ChildID),
CONSTRAINT [AK dbo.Child ChildNaturalKey]
UNIQUE CLUSTERED (ChildNaturalKey),
CONSTRAINT [FK dbo.Child to dbo.Parent]
FOREIGN KEY (ParentID)
REFERENCES dbo.Parent (ParentID)
); Voeg een rij toe aan de bovenliggende tabel zoals eerder:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
DECLARE
@ParentID integer = 1,
@ParentNaturalKey varchar(10) = 'PNK1',
@ParentValue integer = 100;
INSERT dbo.Parent
(
ParentID,
ParentNaturalKey,
ParentValue
)
VALUES
(
@ParentID,
@ParentNaturalKey,
@ParentValue
); In de tweede sessie , voer de update uit zonder deze opnieuw te plegen. Ik gebruik deze keer de natuurlijke sleutel alleen voor de afwisseling - het is niet belangrijk voor het resultaat. Gebruik desgewenst opnieuw de surrogaatsleutel.
DECLARE
@ParentID integer = 1,
@ParentNaturalKey varchar(10) = 'PNK1',
@ParentValue integer = 200;
BEGIN TRANSACTION
UPDATE dbo.Parent
SET ParentValue = @ParentValue
WHERE ParentNaturalKey = @ParentNaturalKey; Voer nu de onderliggende invoeging uit tijdens de eerste sessie :
DECLARE
@ChildID integer = 101,
@ChildNaturalKey varchar(10) = 'CNK1',
@ChildValue integer = 999,
@ParentID integer = 1;
INSERT dbo.Child
(
ChildID,
ChildNaturalKey,
ChildValue,
ParentID
)
VALUES
(
@ChildID,
@ChildNaturalKey,
@ChildValue,
@ParentID
); Deze keer wordt het ingevoegde kind niet geblokkeerd . Dit is waar, of u nu werkt met op vergrendeling gebaseerde of op versiebeheer gebaseerde leescommittatie. Dat is geen typfout of fout:RCSI maakt hier geen verschil.
Uitleg
Het uitvoeringsplan voor het invoegen van het onderliggende record is deze keer iets anders:
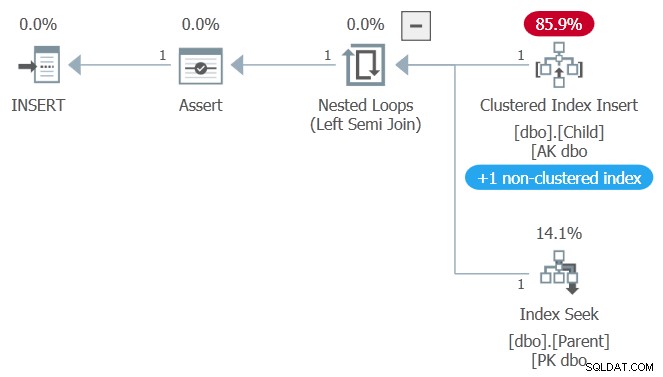
Alles is hetzelfde als voorheen (inclusief het onzichtbare READCOMMITTEDLOCK hint) behalve de externe sleutelcontrole gebruikt nu de niet-geclusterde unieke index die de primaire sleutel van de bovenliggende tabel afdwingt. In de eerste test werd deze index geclusterd.
Dus waarom worden we deze keer niet geblokkeerd?
De nog niet vastgelegde update van de bovenliggende tafel in de tweede sessie heeft een exclusieve vergrendeling op de geclusterde index rij omdat de basistabel wordt gewijzigd. De wijziging in de ParentValue kolom doet niet invloed hebben op de niet-geclusterde primaire sleutel op ParentID , zodat de rij van de niet-geclusterde index niet is vergrendeld .
De externe sleutelcontrole kan daarom zonder strijd de noodzakelijke gedeelde vergrendeling op de niet-geclusterde primaire sleutelindex verkrijgen, en het invoegen van de onderliggende tabel slaagt onmiddellijk .
Toen de primaire werd geclusterd, had de externe-sleutelcontrole een gedeelde vergrendeling nodig op dezelfde bron (geclusterde indexrij) die exclusief was vergrendeld door de update-instructie.
Het gedrag is misschien verrassend, maar het is geen bug . Door de externe sleutelcontrole een eigen geoptimaliseerde toegangsmethode te geven, wordt logisch onnodige lock-conflicten vermeden. Het is niet nodig om het opzoeken van de refererende sleutel te blokkeren omdat de ParentID kenmerk wordt niet beïnvloed door de gelijktijdige update.
2. Vermijdbare updateconflicten
Als u de vorige tests uitvoert onder het Snapshot Isolation (SI)-niveau, zal het resultaat hetzelfde zijn. De onderliggende rij voegt blokken in wanneer de sleutel waarnaar wordt verwezen wordt afgedwongen door een geclusterde index , en blokkeert niet wanneer sleutelhandhaving een niet-geclusterde . gebruikt unieke index.
Er is echter één belangrijk potentieel verschil bij het gebruik van SI. Onder read commit (locking of RCSI) isolatie, slaagt het invoegen van de onderliggende rij uiteindelijk nadat de update in de tweede sessie wordt doorgevoerd of teruggedraaid. Bij gebruik van SI bestaat het risico dat een transactie afbreken vanwege een duidelijk updateconflict.
Dit is een beetje lastiger om aan te tonen omdat een momentopnametransactie niet begint met de BEGIN TRANSACTION statement — het begint met de eerste toegang tot gebruikersgegevens na dat punt.
Het volgende script stelt de SI-demonstratie in, met een extra dummytabel die alleen wordt gebruikt om ervoor te zorgen dat de momentopnametransactie echt is begonnen. Het gebruikt de testvariant waarbij de primaire sleutel waarnaar wordt verwezen wordt afgedwongen met behulp van een unieke geclusterde index (de standaard):
ALTER DATABASE CURRENT SET ALLOW_SNAPSHOT_ISOLATION ON;
GO
DROP TABLE IF EXISTS
dbo.Dummy, dbo.Child, dbo.Parent;
GO
CREATE TABLE dbo.Dummy
(
x integer NULL
);
CREATE TABLE dbo.Parent
(
ParentID integer NOT NULL,
ParentNaturalKey varchar(10) NOT NULL,
ParentValue integer NOT NULL,
CONSTRAINT [PK dbo.Parent ParentID]
PRIMARY KEY (ParentID),
CONSTRAINT [AK dbo.Parent ParentNaturalKey]
UNIQUE (ParentNaturalKey)
);
CREATE TABLE dbo.Child
(
ChildID integer NOT NULL,
ChildNaturalKey varchar(10) NOT NULL,
ChildValue integer NOT NULL,
ParentID integer NULL,
CONSTRAINT [PK dbo.Child ChildID]
PRIMARY KEY (ChildID),
CONSTRAINT [AK dbo.Child ChildNaturalKey]
UNIQUE (ChildNaturalKey),
CONSTRAINT [FK dbo.Child to dbo.Parent]
FOREIGN KEY (ParentID)
REFERENCES dbo.Parent (ParentID)
); De bovenliggende rij invoegen:
DECLARE
@ParentID integer = 1,
@ParentNaturalKey varchar(10) = 'PNK1',
@ParentValue integer = 100;
INSERT dbo.Parent
(
ParentID,
ParentNaturalKey,
ParentValue
)
VALUES
(
@ParentID,
@ParentNaturalKey,
@ParentValue
); Nog in de eerste sessie , start de snapshot-transactie:
-- Session 1 SET TRANSACTION ISOLATION LEVEL SNAPSHOT; BEGIN TRANSACTION; -- Ensure snapshot transaction is started SELECT COUNT_BIG(*) FROM dbo.Dummy AS D;
In de tweede sessie (draaiend op elk isolatieniveau):
-- Session 2
DECLARE
@ParentID integer = 1,
@ParentNaturalKey varchar(10) = 'PNK1',
@ParentValue integer = 200;
BEGIN TRANSACTION;
UPDATE dbo.Parent
SET ParentValue = @ParentValue
WHERE ParentID = @ParentID; Poging om de onderliggende rij in te voegen in de eerste sessie blokken zoals verwacht:
-- Session 1
DECLARE
@ChildID integer = 101,
@ChildNaturalKey varchar(10) = 'CNK1',
@ChildValue integer = 999,
@ParentID integer = 1;
INSERT dbo.Child
(
ChildID,
ChildNaturalKey,
ChildValue,
ParentID
)
VALUES
(
@ChildID,
@ChildNaturalKey,
@ChildValue,
@ParentID
); Het verschil treedt op wanneer we de transactie beëindigen in de tweede sessie. Als we het terugdraaien , het invoegen van de onderliggende rij van de eerste sessie voltooid succesvol .
Als we in plaats daarvan toezeggen de openstaande transactie:
-- Session 2 COMMIT TRANSACTION;
De eerste sessie meldt een updateconflict en rolt terug:

Uitleg
Dit updateconflict treedt op ondanks het feit dat de buitenlandse sleutel wordt gevalideerd is niet gewijzigd door de update van de tweede sessie.
De reden is in wezen dezelfde als bij de eerste reeks tests. Wanneer de geclusterde index wordt gebruikt voor het afdwingen van sleutels waarnaar wordt verwezen, de snapshot-transactie ontmoet een rij dat is gewijzigd sinds het begon. Dit is niet toegestaan onder snapshot-isolatie.
Wanneer de sleutel wordt afgedwongen met behulp van een niet-geclusterde index , ziet de snapshot-transactie alleen de ongewijzigde niet-geclusterde indexrij, dus er is geen blokkering en er wordt geen 'updateconflict' gedetecteerd.
Er zijn veel andere omstandigheden waarin snapshot-isolatie onverwachte updateconflicten of andere fouten kan melden. Zie mijn eerdere artikel voor voorbeelden.
Conclusies
Er zijn veel overwegingen waarmee u rekening moet houden bij het kiezen van de geclusterde index voor een rij-opslagtabel. De hier beschreven problemen zijn slechts een andere factor evalueren.
Dit geldt met name als u snapshot-isolatie gaat gebruiken. Niemand geniet van een afgebroken transactie , vooral een die aantoonbaar onlogisch is. Als u RCSI gaat gebruiken, is de blokkering bij het lezen het valideren van externe sleutels kan onverwacht zijn en tot impasses leiden.
De standaard voor een PRIMARY KEY beperking is om de ondersteunende index als geclusterd te maken , tenzij een andere index of beperking in de tabeldefinitie expliciet aangeeft dat deze in plaats daarvan moet worden geclusterd. Het is een goede gewoonte om expliciet . te zijn over uw ontwerpintentie, dus ik zou u willen aanmoedigen om CLUSTERED . te schrijven of NONCLUSTERED elke keer.
Dubbele indexen?
Er kunnen momenten zijn dat u om gegronde redenen serieus overweegt om een geclusterde index en een niet-geclusterde index te gebruiken met de dezelfde sleutel(s) .
De bedoeling kan zijn om optimale leestoegang te bieden voor gebruikersquery's via de geclusterde index (waarbij het opzoeken van sleutels wordt vermeden), terwijl ook minimaal blokkerende (en update-conflicterende) validatie voor externe sleutels mogelijk wordt gemaakt via de compacte niet-geclusterde index zoals hier getoond.
Dit is haalbaar, maar er zijn een paar problemen om op te letten:
-
Gezien meer dan één geschikte doelindex, biedt SQL Server geen manier om waarborgen welke index zal worden gebruikt voor het afdwingen van externe sleutels.
Dan Guzman heeft zijn observaties gedocumenteerd in Secrets of Foreign Key Index Binding, maar deze kunnen onvolledig zijn, en in ieder geval niet gedocumenteerd, en dus kunnen veranderen .
U kunt dit omzeilen door ervoor te zorgen dat er slechts één doel is index op het moment dat de externe sleutel wordt gemaakt, maar het maakt de zaken wel ingewikkelder en nodigt uit tot toekomstige problemen als de beperking van de externe sleutel ooit wordt verwijderd en opnieuw wordt gemaakt.
-
Als u de verkorte syntaxis voor externe sleutels gebruikt, zal SQL Server alleen bind de beperking aan de primaire sleutel , of het nu niet-geclusterd of geclusterd is.
Het volgende codefragment demonstreert het laatste verschil:
CREATE TABLE dbo.Parent
(
ParentID integer NOT NULL UNIQUE CLUSTERED
);
-- Shorthand (implicit) syntax
-- Fails with error 1773
CREATE TABLE dbo.Child
(
ChildID integer NOT NULL PRIMARY KEY NONCLUSTERED,
ParentID integer NOT NULL
REFERENCES dbo.Parent
);
-- Explicit syntax succeeds
CREATE TABLE dbo.Child
(
ChildID integer NOT NULL PRIMARY KEY NONCLUSTERED,
ParentID integer NOT NULL
REFERENCES dbo.Parent (ParentID)
); Mensen zijn gewend geraakt aan het grotendeels negeren van lees-schrijfconflicten onder RCSI en SI. Hopelijk heeft dit artikel je iets extra's gegeven om over na te denken bij het implementeren van het fysieke ontwerp voor tabellen die zijn gerelateerd aan een externe sleutel.