Cubes moeten regelmatig worden gecontroleerd omdat hun productiviteit vaak daalt (vertragingen tijdens het bouwen van query's, toename van de verwerkingstijd). Om de reden van de daling te achterhalen, moeten we ons systeem in de gaten houden. Hiervoor gebruiken we SQL Server Profiler. Microsoft is echter van plan deze SQL-traceertool in volgende versies uit te sluiten. Het belangrijkste nadeel van de tool is de intensiteit van de bronnen, en het moet zorgvuldig op een productieserver worden uitgevoerd, omdat het een kritiek verlies van systeemproductiviteit kan veroorzaken.
Extended Events is dus een algemeen gebeurtenisafhandelingssysteem voor serversystemen. Dit systeem ondersteunt de correlatie van gegevens van SQL Server, waardoor SQL Server-statusgebeurtenissen kunnen worden opgehaald.
De systeemarchitectuur wordt hieronder getoond:

We hebben zelfs een pakket dat gebeurtenissen, doelen, acties, typen, predikaten en kaarten bevat. Sessies met gebeurtenissen, doelen en acties worden uitgevoerd op de server. Ik zal de architectuur niet in detail beschrijven omdat de help een expliciete beschrijving bevat.
Laten we nu terugkeren naar onze SSAS. Laten we, om alles levendiger te maken, eens kijken naar verschillende scenario's die we gebruiken voor probleemanalyse.
Eerste scenario:Kubusverwerkingsanalyse (Multidimensionale kubus)
Het is vaak het geval wanneer een kubus tijdens de verwerking gedurende een zeer lange tijd wordt bijgewerkt, hoewel het gegevensvolume vrij laag is. Om de reden te achterhalen, moeten we begrijpen welke zoekopdracht of welke plaats van verwerking de vertraging veroorzaakt. Natuurlijk kunnen we de verwerking op Productie uitvoeren en zien wat er aan de hand is, maar ik weet niet zeker of uw gebruikers dit op prijs zullen stellen. Hier komt Extended Events te hulp. Laten we onze sessie uitvoeren en het opslaan ervan in een bestand configureren.
Laten we SSMS openen en verbinding maken met SSAS, en dan overschakelen naar Beheer.

Laten we nu een nieuwe sessie maken:
- Geef op het tabblad Algemeen een naam op voor onze sessie en laad een sjabloon.
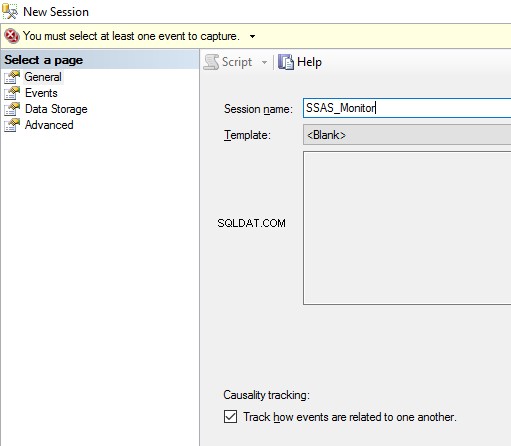
- De Evenementen tabblad toont de gebeurtenissen die ons zullen helpen om de problemen te analyseren. Het tabblad bevat al onze oude vrienden van Profiler. Laten we de volgende gebeurtenissen selecteren voor verwerkingsanalyse:CommandBegin , CommandEnd, Progr essReportBegin en ProgressReportEnd, ResourseUsage.
OpdrachtBegin , CommandEnd toont het begin en einde van de uitvoering van de opdracht tijdens de verwerking.
Progr essReportBegin en ProgressReportEn geef uitgebreide informatie over de lengte van elke gebeurtenis en toon gelezen gegevens, uitvoering van SQL-query's, lengte enz.
ResourseUsage toont het aantal resources dat is besteed aan het uitvoeren van een query, een actie.

Wanneer we de gebeurtenissen hebben geselecteerd, kunnen we overschakelen naar het configureren van elke gebeurtenis en specificeren welke gebeurtenissen moeten worden weergegeven en welke gebeurtenissen moeten worden verborgen (we kunnen bijvoorbeeld de proces-ID verbergen).
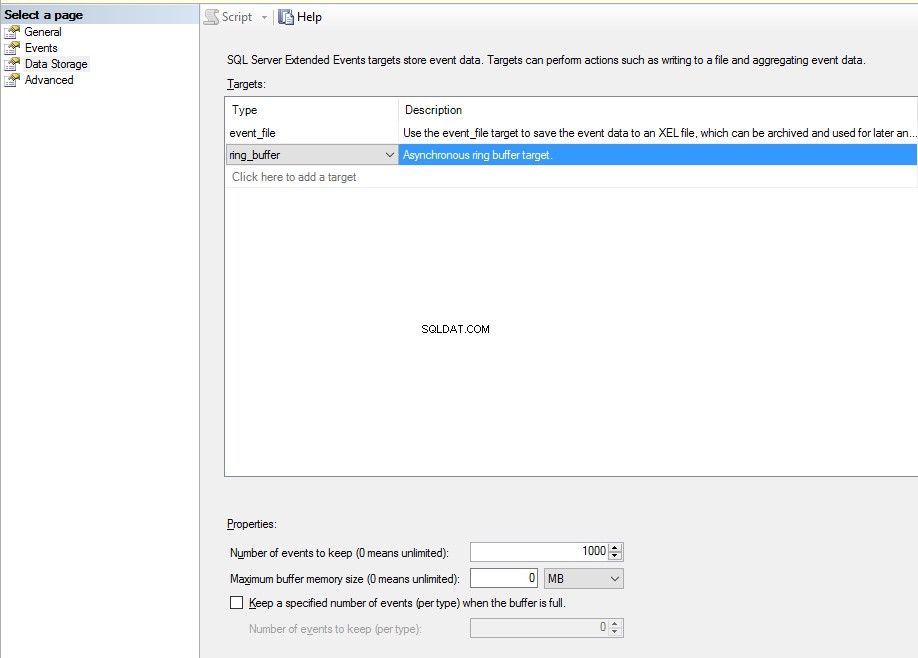
- Gegevensopslag tabblad. Hier kunnen we specificeren om gebeurtenissen in de real-time modus te tonen of ze naar een bestand te schrijven:
- event_file – gebeurtenis opslaan in een bestand voor verdere analyse. Geef de maximale bestandsgrootte en het bestemmingspad op. Als de bestandsgrootte de opgegeven grootte overschrijdt, wordt een nieuw bestand gemaakt. We kunnen ook het aantal bestanden specificeren dat moet worden aangemaakt (maximaal aantal bestanden).
- event_stream - maakt het bekijken van gebeurtenissen in de realtime-modus mogelijk.
- ring_buffer – geeft aan dat de sessiegegevens in het geheugen moeten worden opgeslagen zolang de server draait. In het geval van herladen worden gegevens verwijderd.
- De Geavanceerde tab staat het configureren van bronnen (geheugen, processor) voor een bepaalde sessie toe.
Klik ten slotte op OK en krijg de sessie. Laten we de kubusverwerking uitvoeren en de verwerking per gebeurtenis bekijken. Schakel over naar de live-gegevensmodus.
Boven aan de volgende schermafbeelding kunnen we de gebeurtenissen zien die nu plaatsvinden met onze instantie. Details van de evenementen worden onderaan weergegeven. Elke waarde van de gebeurtenisdetails kan bovenaan als een aparte kolom worden toegevoegd. Klik met de rechtermuisknop op een geselecteerde waarde van de gebeurtenisdetails en bekijk ze in een tabel.

In het resultaat krijgen we de volgende weergave:

Daarom maken Extended Events het mogelijk om onze verwerking in realtime te analyseren. We kunnen begrijpen hoeveel tijd er wordt besteed aan de verwerking van elk object, hoeveel middelen er worden gebruikt. Dit helpt om conclusies te trekken en zwakke plekken te vinden. Bovendien overbelasten we het systeem niet en lopen we geen productiviteitsverlies op.
U kunt ook een sessie maken via XMLA. Je kunt het script op GitHub ophalen.
Het stoppen en verwijderen van een sessie is mogelijk via zowel SSMS als XMLA.
- Via SSMS (in 2016 treedt de fout echter op en ik kan de sessie niet via de interface verwijderen).
- XMLA-script – kan hier worden gedownload.
Dit is het eerste deel van het artikel over Extended Events voor SSAS. In het tweede deel gaan we in op een scenario van query-productiviteitsanalyse in kubus, werken met traceerbestanden en analyseren van het bestand via Power BI.
Ik raad ook aan om de volgende blogposts te bekijken:
- Pinal Dave — SQL SERVER – SQL Profiler versus uitgebreide gebeurtenissen
- Chris Web — Profiler, uitgebreide evenementen en analyseservices. Hoewel de auteur van het artikel stelt dat Profiler bijna niet wordt gebruikt op productieservers, maar de problemen met serverbelasting bevestigt.
- Brent Ozar — SQL Server uitgebreide gebeurtenissen