Read Committed is de tweede zwakste van de vier isolatieniveaus gedefinieerd door de SQL-standaard. Niettemin is dit het standaardisolatieniveau voor veel database-engines, waaronder SQL Server. Dit bericht in een serie over isolatieniveaus en de ACID-eigenschappen van transacties kijkt naar de logische en fysieke garanties die daadwerkelijk worden geboden door read-committ isolation.
Logische garanties
De SQL-standaard vereist dat een transactie die onder read-commit-isolatie wordt uitgevoerd, alleen leest committed gegevens. Het drukt deze eis uit door het gelijktijdigheidsfenomeen dat bekend staat als een vuile lezing te verbieden. Een vuile lezing vindt plaats wanneer een transactie gegevens leest die door een andere transactie zijn geschreven, voordat die tweede transactie is voltooid. Een andere manier om dit uit te drukken is door te zeggen dat er een vuile lezing optreedt wanneer een transactie niet-vastgelegde gegevens leest.
De standaard vermeldt ook dat een transactie die wordt uitgevoerd met read-commit isolatie, het gelijktijdigheidsfenomeen kan tegenkomen dat bekend staat als niet-herhaalbare reads en fantomen . Hoewel veel boeken deze verschijnselen verklaren in termen van het feit dat een transactie gewijzigde of nieuwe gegevensitems kan zien als gegevens vervolgens opnieuw worden gelezen, kan deze verklaring de misvatting versterken. dat gelijktijdigheidsverschijnselen alleen kunnen optreden binnen een expliciete transactie die meerdere verklaringen bevat. Dit is niet zo. Een enkele verklaring zonder een expliciete transactie is net zo kwetsbaar voor de niet-herhaalbare lees- en fantoomfenomenen, zoals we binnenkort zullen zien.
Dat is zo ongeveer alles wat de norm te zeggen heeft over read-committ isolation. Op het eerste gezicht lijkt het lezen van alleen vastgelegde data een redelijk goede garantie voor verstandig gedrag, maar zoals altijd zit de duivel in de details. Zodra u op zoek gaat naar mogelijke mazen in de wet in deze definitie wordt het maar al te gemakkelijk om gevallen te vinden waarin onze read-committed transacties mogelijk niet de resultaten opleveren die we zouden verwachten. Nogmaals, we zullen deze in een paar ogenblikken in meer detail bespreken.
Verschillende fysieke implementaties
Er zijn ten minste twee dingen die betekenen dat het waargenomen gedrag van het read-commit-isolatieniveau behoorlijk kan verschillen op verschillende database-engines. Ten eerste, de SQL-standaardvereiste om alleen vastgelegde gegevens te lezen niet betekent noodzakelijkerwijs dat de vastgelegde gegevens die door een transactie worden gelezen, de meest recente . zijn vastgelegde gegevens.
Een database-engine mag een vastgelegde versie van een rij lezen vanaf elk punt in het verleden en voldoen nog steeds aan de standaarddefinitie van SQL. Verschillende populaire databaseproducten implementeren op deze manier read-committed isolation. Queryresultaten die zijn verkregen met deze implementatie van read-commit-isolatie kunnen willekeurig verouderd zijn , in vergelijking met de huidige vastgelegde status van de database. We zullen dit onderwerp behandelen zoals het van toepassing is op SQL Server in de volgende post in de serie.
Het tweede waar ik uw aandacht op wil vestigen, is dat de standaarddefinitie van SQL niet voorkomen dat een bepaalde implementatie aanvullende beveiligingen met gelijktijdigheidseffect biedt, naast het voorkomen van dirty reads . De standaard specificeert alleen dat dirty reads niet zijn toegestaan, het vereist niet dat andere gelijktijdigheidsfenomenen toegestaan moeten zijn op een bepaald isolatieniveau.
Om duidelijk te zijn over dit tweede punt:een database-engine die aan de normen voldoet, zou alle isolatieniveaus kunnen implementeren met behulp van serializable gedrag als hij dat wil. Sommige grote commerciële database-engines bieden ook een implementatie van read-commit die veel verder gaat dan alleen het voorkomen van vuile reads (hoewel geen enkele zo ver gaat als het bieden van volledige isolatie in de ACID zin van het woord).
Daarnaast, voor verschillende populaire producten, lees toegewijd isolatie is de laagste isolatieniveau beschikbaar; hun implementaties van read niet vastgelegd isolatie zijn precies hetzelfde als lezen gepleegd. Dit is toegestaan door de standaard, maar dit soort verschillen maken de toch al moeilijke taak om code van het ene platform naar het andere te migreren, nog ingewikkelder. Als we het hebben over het gedrag van een isolatieniveau, is het meestal belangrijk om ook het specifieke platform te specificeren.
Voor zover ik weet, is SQL Server uniek onder de belangrijkste commerciële database-engines in het leveren van twee implementaties van het read-commit isolatieniveau, elk met zeer verschillende fysieke gedragingen. Dit bericht behandelt de eerste hiervan, vergrendelend lees toegewijd.
SQL-serververgrendeling Lezen vastgelegd
Als de database-optie READ_COMMITTED_SNAPSHOT is OFF , SQL Server gebruikt een vergrendeling implementatie van het read-commit isolatieniveau, waarbij gedeelde vergrendelingen worden gebruikt om te voorkomen dat een gelijktijdige transactie tegelijkertijd de gegevens wijzigt, omdat wijziging een exclusieve vergrendeling vereist, die niet compatibel is met de gedeelde vergrendeling.
Het belangrijkste verschil tussen SQL Server locking read commit en locking repeatable read (waarbij ook gedeelde vergrendelingen nodig zijn bij het lezen van gegevens) is dat read commit de gedeelde vergrendeling zo snel mogelijk opheft , terwijl herhaalbaar lezen deze vergrendelingen vasthoudt tot het einde van de omsluitende transactie.
Wanneer vergrendeling read commit vergrendelingen verkrijgt met rijgranulariteit, wordt de gedeelde vergrendeling die op een rij is genomen vrijgegeven wanneer een gedeeld slot wordt ingenomen op de volgende rij . Bij paginagranulariteit wordt de gedeelde paginavergrendeling vrijgegeven wanneer de eerste rij op de volgende pagina wordt gelezen, enzovoort. Tenzij er een hint voor de granulariteit van de vergrendeling bij de query wordt geleverd, bepaalt de database-engine met welk niveau van granulariteit moet worden begonnen. Houd er rekening mee dat granulariteitshints alleen worden behandeld als suggesties door de engine, een minder granulaire vergrendeling dan gevraagd kan in eerste instantie nog steeds worden genomen. Afhankelijk van de systeemconfiguratie kunnen vergrendelingen tijdens de uitvoering ook worden geëscaleerd van rij- of paginaniveau naar partitie- of tabelniveau.
Het belangrijke punt hier is dat gedeelde sloten doorgaans slechts voor een zeer korte tijd worden vastgehouden terwijl de instructie wordt uitgevoerd. Om een veelvoorkomende misvatting expliciet aan te pakken, is locking read commit niet houd gedeelde sloten vast aan het einde van de instructie.
Lees vastgelegd gedrag vergrendelen
De gedeelde vergrendelingen voor de korte termijn die worden gebruikt door de SQL Server-vergrendeling van read-committe implementatie bieden zeer weinig van de garanties die algemeen worden verwacht van een databasetransactie door T-SQL-programmeurs. In het bijzonder een instructie die wordt uitgevoerd onder locking read commit isolatie:
- Kan dezelfde rij meerdere keren tegenkomen;
- Kan sommige rijen volledig missen; en
- Is niet geef een point-in-time weergave van de gegevens
Die lijst lijkt misschien meer op een beschrijving van het vreemde gedrag dat u meer zou kunnen associëren met het gebruik van NOLOCK hints, maar al deze dingen kunnen echt gebeuren, en gebeuren ook bij het gebruik van locking read commit isolation.
Voorbeeld
Overweeg de eenvoudige taak om de rijen in een tabel te tellen, met behulp van de voor de hand liggende query met één instructie. Onder locking read commit isolation met rijvergrendelingsgranulariteit, neemt onze query een gedeelde vergrendeling op de eerste rij, leest deze, laat de gedeelde vergrendeling los, gaat verder naar de volgende rij, enzovoort totdat deze het einde van de structuur bereikt leest. Omwille van dit voorbeeld, neem aan dat onze query een index b-tree leest in oplopende sleutelvolgorde (hoewel het net zo goed een aflopende volgorde of een andere strategie kan gebruiken).
Sinds slechts een enkele rij op elk moment in de tijd is vergrendeld, is het duidelijk mogelijk voor gelijktijdige transacties om de ontgrendelde rijen in de index die onze zoekopdracht doorloopt, te wijzigen. Als deze gelijktijdige wijzigingen de waarden van de indexsleutel wijzigen, zorgen ze ervoor dat rijen binnen de indexstructuur worden verplaatst. Met die mogelijkheid in gedachten illustreert het onderstaande diagram twee problematische scenario's die zich kunnen voordoen:
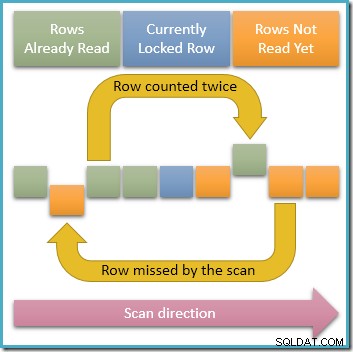
De bovenste pijl toont een rij die we al hebben geteld en waarvan de indexsleutel gelijktijdig is gewijzigd, zodat de rij voor de huidige scanpositie in de index komt, wat betekent dat de rij twee keer wordt geteld . De tweede pijl toont een rij die onze scan nog niet is tegengekomen achter de scanpositie, wat betekent dat de rij niet wordt geteld helemaal niet.
Geen momentopname
De vorige sectie liet zien hoe locking read commits gegevens volledig kunnen missen, of hetzelfde item meerdere keren kunnen tellen (meer dan twee keer, als we pech hebben). Het derde opsommingsteken in de lijst met onverwacht gedrag vermeldde dat het vergrendelen van de leesopdracht ook geen momentopname van de gegevens biedt.
De redenering achter die verklaring zou nu gemakkelijk te zien moeten zijn. Onze telquery kan bijvoorbeeld gemakkelijk gegevens lezen die zijn ingevoegd door gelijktijdige transacties nadat onze query werd uitgevoerd. Evenzo kunnen gegevens die onze query ziet, worden gewijzigd door gelijktijdige activiteit nadat onze query is gestart en voordat deze is voltooid. Ten slotte kunnen gegevens die we hebben gelezen en geteld, worden verwijderd door een gelijktijdige transactie voordat onze zoekopdracht is voltooid.
Het is duidelijk dat de gegevens die worden gezien door een instructie of transactie die wordt uitgevoerd onder locking read-commit-isolatie, overeenkomen met geen enkele status van de database op een bepaald moment . De gegevens die we tegenkomen, kunnen afkomstig zijn van verschillende tijdstippen, met als enige gemeenschappelijke factor dat elk item de laatste vastgelegde waarde van die gegevens vertegenwoordigde op het moment dat het werd gelezen (hoewel het sindsdien misschien veranderd of verdwenen is).
Hoe ernstig zijn deze problemen?
Dit lijkt allemaal misschien een nogal wollige stand van zaken als je gewend bent om je single-statement queries en expliciete transacties te zien als logisch onmiddellijk uitgevoerd, of als draaiend tegen een enkele vastgelegde point-in-time status van de database bij gebruik van de standaard SQL Server-isolatieniveau. Het past zeker niet goed bij het concept van isolatie in de ZURE betekenis.
Gezien de schijnbare zwakte van de garanties die worden geboden door het vergrendelen van read commit-isolatie, zou je je kunnen afvragen hoe een van uw productie T-SQL-code ooit goed heeft gewerkt! Natuurlijk kunnen we accepteren dat het gebruik van een isolatieniveau onder serialiseerbaar betekent dat we de volledige ACID-transactie-isolatie opgeven in ruil voor andere potentiële voordelen, maar hoe ernstig kunnen we verwachten dat deze problemen in de praktijk zullen zijn?
Ontbrekende en dubbelgetelde rijen
Deze eerste twee problemen zijn in wezen afhankelijk van het wijzigen van sleutels . door gelijktijdige activiteit in een indexstructuur die we momenteel aan het scannen zijn. Merk op dat scannen hier omvat het scangedeelte van het gedeeltelijke bereik van een index zoeken , evenals de bekende onbeperkte index- of tabelscan.
Als we (bereik) een indexstructuur scannen waarvan de sleutels doorgaans niet worden gewijzigd door een gelijktijdige activiteit, zouden deze eerste twee problemen niet echt een praktisch probleem moeten zijn. Het is echter moeilijk om hier zeker van te zijn, omdat queryplannen kunnen worden gewijzigd om een andere toegangsmethode te gebruiken en de nieuwe gezochte index vluchtige sleutels kan bevatten.
We moeten er ook rekening mee houden dat veel productievragen slechts een bij benadering . nodig hebben of hoe dan ook het beste antwoord op sommige soorten vragen. Het feit dat sommige rijen ontbreken of dubbel worden geteld, maakt in het grotere geheel misschien niet zoveel uit. Op een systeem met veel gelijktijdige wijzigingen kan het zelfs moeilijk zijn om er zeker van te zijn dat het resultaat was onnauwkeurig, aangezien de gegevens zo vaak veranderen. In dat soort situaties kan een ongeveer juist antwoord goed genoeg zijn voor de doeleinden van de gegevensconsument.
Geen tijdstipweergave
De derde kwestie (de kwestie van een zogenaamde 'consistente' point-in-time weergave van de gegevens) komt ook neer op dezelfde soort overwegingen. Voor rapportagedoeleinden, waar inconsistenties vaak leiden tot lastige vragen van de gegevensconsumenten, heeft een momentopname vaak de voorkeur. In andere gevallen is het soort inconsistenties dat voortkomt uit het ontbreken van een momentopname van de gegevens misschien wel acceptabel.
Problematische scenario's
Er zijn ook tal van gevallen waarin de genoemde zorgen zullen belangrijk zijn. Als u bijvoorbeeld code schrijft die bedrijfsregels . afdwingt in T-SQL moet u voorzichtig zijn bij het selecteren van een isolatieniveau (of het nemen van andere passende maatregelen) om de correctheid te garanderen. Veel bedrijfsregels kunnen worden afgedwongen met behulp van externe sleutels of beperkingen, waarbij de fijne kneepjes van het selecteren van isolatieniveaus automatisch voor u worden afgehandeld door de database-engine. Als algemene vuistregel:gebruik de ingebouwde set van declaratieve integriteit features heeft de voorkeur boven het maken van je eigen regels in T-SQL.
Er is een andere brede categorie van zoekopdrachten die een bedrijfsregel per se niet helemaal afdwingt , maar die niettemin ongelukkige gevolgen kunnen hebben wanneer ze worden uitgevoerd op het standaard locking read commit isolation level. Deze scenario's zijn niet altijd zo voor de hand liggend als de vaak aangehaalde voorbeelden van geld overmaken tussen bankrekeningen, of ervoor zorgen dat het saldo over een aantal gekoppelde rekeningen nooit onder nul zakt. Beschouw bijvoorbeeld de volgende zoekopdracht die achterstallige facturen identificeert als input voor een proces dat streng geformuleerde herinneringsbrieven verstuurt:
INSERT dbo.OverdueInvoices
SELECT I.InvoiceNumber
FROM dbo.Invoices AS INV
WHERE INV.TotalDue >
(
SELECT SUM(P.Amount)
FROM dbo.Payments AS P
WHERE P.InvoiceNumber = I.InvoiceNumber
); Het is duidelijk dat we geen brief willen sturen naar iemand die zijn factuur volledig in termijnen heeft betaald, simpelweg omdat gelijktijdige database-activiteit op het moment dat onze zoekopdracht werd uitgevoerd, betekende dat we een onjuist bedrag hadden berekend. van ontvangen betalingen. Echte vragen over echte productiesystemen zijn natuurlijk vaak veel complexer dan het eenvoudige voorbeeld hierboven.
Om vandaag af te ronden, kijk eens naar de volgende query en kijk of u kunt zien hoeveel kansen er zijn dat iets onbedoeld gebeurt, als meerdere van dergelijke query's gelijktijdig worden uitgevoerd op het locking read commit isolation-niveau (misschien terwijl andere niet-gerelateerde transacties wijzigen ook de Cases-tabel):
-- Allocate the oldest unallocated case ID to
-- the current case worker, while ensuring
-- the worker never has more than three
-- active cases at once.
UPDATE dbo.Cases
SET WorkerID = @WorkerID
WHERE
CaseID =
(
-- Find the oldest unallocated case ID
SELECT TOP (1)
C2.CaseID
FROM dbo.Cases AS C2
WHERE
C2.WorkerID IS NULL
ORDER BY
C2.DateCreated DESC
)
AND
(
SELECT COUNT_BIG(*)
FROM dbo.Cases AS C3
WHERE C3.WorkerID = @WorkerID
) < 3; Als u eenmaal op zoek bent naar alle kleine manieren waarop een query op dit isolatieniveau mis kan gaan, kan het moeilijk zijn om te stoppen. Houd rekening met de eerder gemaakte kanttekeningen met betrekking tot de echte behoefte aan volledig geïsoleerde en op het juiste moment nauwkeurige resultaten. Het is prima om zoekopdrachten te hebben die voldoende resultaten opleveren, zolang je je bewust bent van de afwegingen die je maakt door read-commit te gebruiken.
Volgende keer
Het volgende deel in deze serie kijkt naar de tweede fysieke implementatie van read Committed isolation beschikbaar in SQL Server, read Committed snapshot isolation.
[ Zie de index voor de hele serie ]