In mijn vorige post in deze serie heb ik aangetoond dat niet alle queryscenario's kunnen profiteren van In-Memory OLTP-technologieën. Het gebruik van Hekaton in bepaalde gebruikssituaties kan zelfs een nadelig effect hebben op de prestaties (klik om te vergroten):

Prestatiemonitorprofiel tijdens uitvoering van opgeslagen procedure
In dat scenario zou ik echter het kaartspel tegen Hekaton hebben gestapeld, op twee manieren:
- Het voor geheugen geoptimaliseerde tabeltype dat ik heb gemaakt, had een aantal buckets van 256, maar ik gaf tot 2.000 waarden door om te vergelijken. In een recentere blogpost van het SQL Server-team legden ze uit dat het beter is om het aantal buckets te groot te maken dan het te klein te maken - iets dat ik in het algemeen wel wist, maar niet besefte dat het ook significante effecten had op tabelvariabelen:Houd er rekening mee dat voor een hash-index de bucket_count ongeveer 1-2X het aantal verwachte unieke indexsleutels moet zijn. Overmaat is meestal beter dan ondermaat:als u soms slechts 2 waarden in de variabelen invoegt, maar soms tot 1000 waarden, is het meestal beter om
BUCKET_COUNT=1000op te geven .Ze bespreken niet expliciet de werkelijke reden hiervoor, en ik weet zeker dat er tal van technische details zijn waar we in kunnen duiken, maar de voorgeschreven richtlijnen lijken te groot te zijn.
- De primaire sleutel was een hash-index op twee kolommen, terwijl de tabelwaardeparameter alleen probeerde de waarden in een van die kolommen te matchen. Dit betekende heel eenvoudig dat de hash-index niet kon worden gebruikt. Tony Rogerson legt dit iets gedetailleerder uit in een recente blogpost:De hash wordt gegenereerd voor alle kolommen in de index, u moet ook alle kolommen in de hash-index specificeren op uw gelijkheidscontrole-expressie, anders kan de index niet worden gebruikt .
Ik heb het niet eerder laten zien, maar merk op dat het plan tegen de voor geheugen geoptimaliseerde tabel met de hash-index met twee kolommen eigenlijk een tabelscan doet in plaats van de index die je zou verwachten tegen de niet-geclusterde hash-index (aangezien de leidende kolom was
SalesOrderID):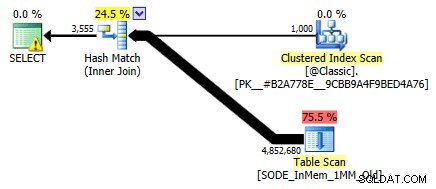
Queryplan met een in-memory tabel met twee kolommen hash-indexOm specifieker te zijn, in een hash-index betekent de leidende kolom niet alleen een heuvel met bonen; de hash komt nog steeds overeen in alle kolommen, dus het werkt helemaal niet als een traditionele B-tree-index (met een traditionele index kan een predikaat met alleen de leidende kolom nog steeds erg handig zijn bij het elimineren van rijen).
Wat te doen?
Nou, eerst heb ik een secundaire hash-index gemaakt op alleen de SalesOrderID kolom. Een voorbeeld van zo'n tabel, met een miljoen buckets:
CREATE TABLE [dbo].[SODE_InMem_1MM]
(
[SalesOrderID] [int] NOT NULL,
[SalesOrderDetailID] [int] NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL,
[LineTotal] [numeric](38, 6) NOT NULL,
[rowguid] [uniqueidentifier] NOT NULL,
[ModifiedDate] [datetime] NOT NULL
PRIMARY KEY NONCLUSTERED HASH
(
[SalesOrderID],
[SalesOrderDetailID]
) WITH (BUCKET_COUNT = 1048576),
/* I added this secondary non-clustered hash index: */
INDEX x NONCLUSTERED HASH
(
[SalesOrderID]
) WITH (BUCKET_COUNT = 1048576)
/* I used the same bucket count to minimize testing permutations */
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); Onthoud dat onze tafeltypes op deze manier zijn ingesteld:
CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
Nadat ik de nieuwe tabellen met gegevens heb gevuld en een nieuwe opgeslagen procedure heb gemaakt om naar de nieuwe tabellen te verwijzen, toont het plan dat we correct krijgen een indexzoekopdracht tegen de hash-index met één kolom:

Verbeterd plan met behulp van de hash-index met één kolom
Maar wat zou dat echt betekenen voor de prestaties? Ik heb dezelfde reeks tests opnieuw uitgevoerd - zoekopdrachten tegen deze tabel met bucket-tellingen van 16K, 131K en 1MM; het gebruik van zowel klassieke als in-memory TVP's met 100, 1.000 en 2.000 waarden; en in het geval van TVP in het geheugen, waarbij zowel een traditionele opgeslagen procedure als een native gecompileerde opgeslagen procedure wordt gebruikt. Hier is hoe de prestatie ging voor 10.000 iteraties per combinatie:

Prestatieprofiel voor 10.000 iteraties tegen een hash-index met één kolom, een TVP met 256 emmers gebruiken
Je denkt misschien, hé, dat prestatieprofiel ziet er niet zo geweldig uit; integendeel, het is veel beter dan mijn vorige test vorige maand. Het toont alleen maar aan dat het aantal buckets voor de tabel een enorme impact kan hebben op het vermogen van SQL Server om de hash-index effectief te gebruiken. In dit geval is het gebruik van een aantal buckets van 16K duidelijk niet optimaal voor elk van deze gevallen, en het wordt exponentieel slechter naarmate het aantal waarden in de TVP toeneemt.
Onthoud dat het aantal buckets van de TVP 256 was. Dus wat zou er gebeuren als ik dat zou verhogen, volgens de richtlijnen van Microsoft? Ik heb een tweede tabeltype gemaakt met een meer geschikte emmergrootte. Aangezien ik 100, 1.000 en 2.000 waarden aan het testen was, gebruikte ik de volgende macht van 2 voor het aantal emmers (2048):
CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 2048) ) WITH (MEMORY_OPTIMIZED = ON);
Ik heb hiervoor ondersteunende procedures gemaakt en dezelfde reeks tests opnieuw uitgevoerd. Hier zijn de prestatieprofielen naast elkaar:

Prestatieprofielvergelijking met 256- en 2.048-bucket TVP's
De verandering in het aantal buckets voor het tabeltype had niet de impact die ik had verwacht, gezien de verklaring van Microsoft over de grootte. Het had eigenlijk helemaal geen positief effect; in feite was het voor sommige scenario's een beetje erger. Maar over het algemeen zijn de prestatieprofielen in alle opzichten hetzelfde.
Wat wel een enorm effect had, was het creëren van de *right* hash-index om het querypatroon te ondersteunen. Ik was dankbaar dat ik kon aantonen dat - ondanks mijn eerdere tests die anders aangaven - een in-memory tabel en in-memory TVP de ouderwetse manier konden verslaan om hetzelfde te bereiken. Laten we het meest extreme geval uit mijn vorige voorbeeld nemen, toen de tabel alleen een hash-index met twee kolommen had:

Prestatieprofiel voor 10 iteraties tegen een hash-index van twee kolommen
De meest rechtse balk toont de duur van slechts 10 iteraties van de native opgeslagen procedure die overeenkomt met een ongepaste hash-index - querytijden variërend van 735 tot 1.601 milliseconden. Nu echter, met de juiste hash-index, worden dezelfde zoekopdrachten uitgevoerd in een veel kleiner bereik - van 0,076 milliseconden tot 51,55 milliseconden. Als we het slechtste geval (16K bucket counts) buiten beschouwing laten, is de discrepantie nog groter. In alle gevallen is dit minstens twee keer zo efficiënt (tenminste qua duur) als beide methoden, zonder een naïef gecompileerde opgeslagen procedure, tegen dezelfde voor geheugen geoptimaliseerde tabel; en honderden keren beter dan alle benaderingen van onze oude voor geheugen geoptimaliseerde tabel met de enige hash-index met twee kolommen.
Conclusie
Ik hoop dat ik heb aangetoond dat er veel voorzichtigheid moet worden betracht bij het implementeren van voor geheugen geoptimaliseerde tabellen van welk type dan ook, en dat in veel gevallen het gebruik van een voor geheugen geoptimaliseerd TVP alleen niet de grootste prestatiewinst oplevert. U zult willen overwegen om native gecompileerde opgeslagen procedures te gebruiken om het meeste waar voor uw geld te krijgen, en om het beste te schalen, zult u echt aandacht willen besteden aan het aantal buckets voor de hash-indexen in uw voor geheugen geoptimaliseerde tabellen (maar misschien niet zoveel aandacht voor uw geheugen-geoptimaliseerde tafeltypes).
Voor meer informatie over In-Memory OLTP-technologie in het algemeen, kunt u deze bronnen raadplegen:
- Het SQL Server-teamblog (Tag:Hekaton en Tag:In-Memory OLTP – zijn codenamen niet leuk?)
- Bob Beauchemin's blog
- Blog van Klaus Aschenbrenner