~3.5TB aan gegevens opslaan en ongeveer 1K/sec 24x7 invoegen, en ook query's uitvoeren met een niet gespecificeerde snelheid, is mogelijk met SQL Server, maar er zijn meer vragen:
- welke beschikbaarheidseis heeft u hiervoor? 99,999% uptime, of is 95% genoeg?
- welke betrouwbaarheidseis heeft u? Kost het missen van een insert u $ 1 miljoen?
- Welke eis voor herstelbaarheid heeft u? Als u een dag aan gegevens kwijtraakt, maakt dat dan uit?
- welke consistentie-eis heeft u? Moet een schrijfactie gegarandeerd zichtbaar zijn bij de volgende lezing?
Als je al deze vereisten nodig hebt die ik heb benadrukt, kost de belasting die je voorstelt miljoenen aan hardware en licenties op een relationeel systeem, elk systeem, ongeacht welke trucs je probeert (sharding, partitionering, enz.). Een nosql-systeem zou per definitie niet aan alles voldoen deze vereisten.
U hebt dus duidelijk al een aantal van deze vereisten versoepeld. Er is een mooie visuele gids die het nosql-aanbod vergelijkt op basis van het 'pick 2 of 3'-paradigma bij Visual Guide to NoSQL-systemen:
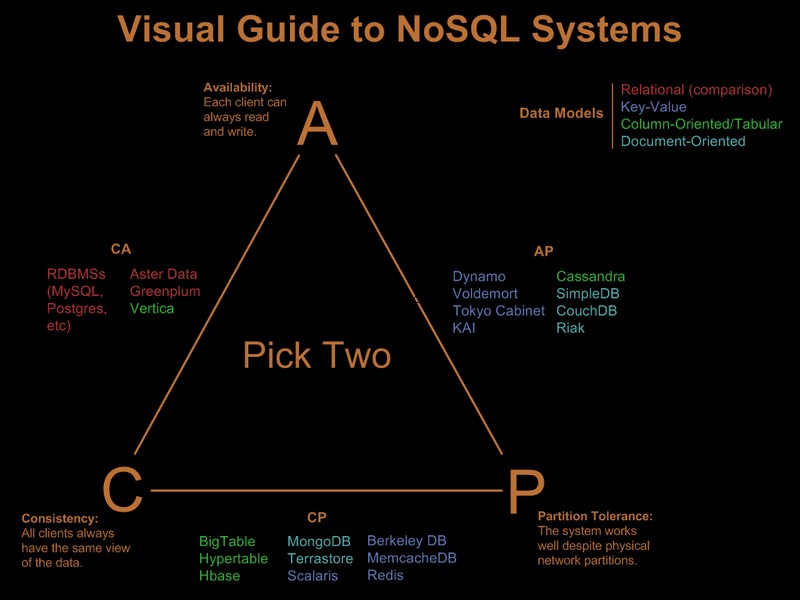
Na update van OP-reactie
Met SQL Server zou dit een ongecompliceerde implementatie zijn:
- één enkele tabel geclusterde sleutel (GUID, tijd). Ja, het zal gefragmenteerd raken, maar is fragmentatie van invloed op read-aheads en read-aheads zijn alleen nodig voor significante bereikscans. Aangezien u alleen naar een specifieke GUID en datumbereik zoekt, maakt fragmentatie niet veel uit. Ja, het is een brede sleutel, dus niet-bladige pagina's hebben een slechte sleuteldichtheid. Ja, het zal leiden tot een slechte vulfactor. En ja, paginasplitsingen kunnen voorkomen. Ondanks deze problemen is het, gezien de eisen, nog steeds de beste keuze voor een geclusterde sleutel.
- partitioneer de tabel op tijd, zodat u de verlopen records efficiënt kunt verwijderen via een automatisch schuifvenster. Breid dit uit met een online reconstructie van indexpartities van de afgelopen maand om de slechte vulfactor en fragmentatie te elimineren die zijn geïntroduceerd door de GUID-clustering.
- paginacompressie inschakelen. Aangezien de geclusterde sleutelgroepen door GUID eerst worden geclusterd, zullen alle records van een GUID naast elkaar staan, wat paginacompressie een goede kans geeft om woordenboekcompressie in te zetten.
- je hebt een snel IO-pad nodig voor het logbestand. Je bent geïnteresseerd in een hoge doorvoer, niet in een lage latentie om een logbestand bij te houden met 1K inserts/sec, dus strippen is een must.
Partitionering en paginacompressie vereisen elk een Enterprise Edition SQL Server, ze werken niet op Standard Edition en beide zijn vrij belangrijk om aan de vereisten te voldoen.
Als een kanttekening, als de records afkomstig zijn van een front-end webserverfarm, zou ik Express op elke webserver plaatsen en in plaats van INSERT aan de achterkant, zou ik SEND de info naar de back-end, met behulp van een lokale verbinding/transactie op de Express die zich samen met de webserver bevindt. Dit geeft een veel beter beschikbaarheidsverhaal aan de oplossing.
Dus dit is hoe ik het zou doen in SQL Server. Het goede nieuws is dat de problemen waarmee u te maken krijgt goed worden begrepen en dat de oplossingen bekend zijn. dat betekent niet noodzakelijk dat dit beter is dan wat je zou kunnen bereiken met Cassandra, BigTable of Dynamo. Ik zal iemand die meer verstand heeft van dingen die geen sql-achtig zijn, hun zaak laten bepleiten.
Merk op dat ik nooit het programmeermodel, .Net-ondersteuning en dergelijke heb genoemd. Ik denk eerlijk gezegd dat ze niet relevant zijn in grote implementaties. Ze maken een enorm verschil in het ontwikkelingsproces, maar als ze eenmaal zijn geïmplementeerd, maakt het niet uit hoe snel de ontwikkeling was, als de ORM-overhead de prestaties doodt :)