Hash-indexen zijn een integraal onderdeel van databases. Als je ooit een database hebt gebruikt, is de kans groot dat je ze in actie hebt gezien zonder het zelfs maar te beseffen.
Hash-indexen verschillen in werk van andere typen indexen omdat ze waarden opslaan in plaats van verwijzingen naar records op een schijf. Dit zorgt voor sneller zoeken en invoegen in de index. Daarom worden hash-indexen vaak gebruikt als primaire sleutels of unieke identifiers.
Hash-indexen begrijpen
Een hash-index is een indextype dat het meest wordt gebruikt in gegevensbeheer. Het wordt meestal gemaakt op een kolom die unieke waarden bevat, zoals een primaire sleutel of e-mailadres. Het belangrijkste voordeel van het gebruik van hash-indexen is hun snelle prestaties.
Het concept achter deze indexen kan ingewikkeld zijn om te begrijpen voor iemand die er nog nooit van heeft gehoord. Het begrijpen van hash-indexen is echter belangrijk als u wilt begrijpen hoe databases werken. Het is noodzakelijk voor het oplossen van veelvoorkomende problemen met betrekking tot databases en hun snelheid.
Het goede nieuws is dat je met een beetje geduld en een uitgeschakelde mobiele telefoon zeker de hash-indexen onder de knie kunt krijgen! Laten we dus eens beter kijken.
Snel en gemakkelijk
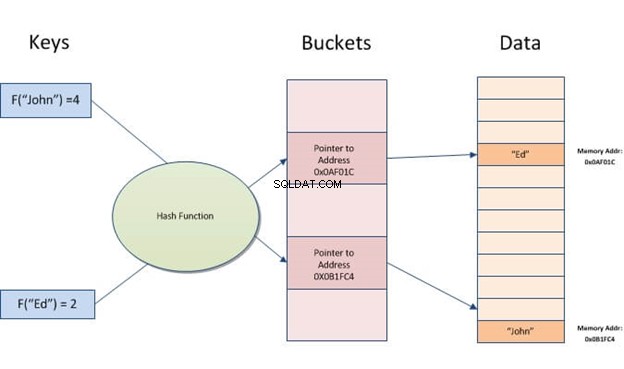
Een hash-index is een gegevensstructuur die kan worden gebruikt om databasequery's te versnellen. Het werkt door invoerrecords om te zetten in een reeks buckets. Elke bucket heeft hetzelfde aantal records als alle andere buckets in de tabel. Dus, ongeacht hoeveel verschillende waarden je hebt voor een bepaalde kolom, elke rij zal altijd worden toegewezen aan één bucket.
Met hash-indexen kunt u snel gegevens opzoeken die in tabellen zijn opgeslagen. Ze werken door een indexsleutel van de waarde te maken en deze vervolgens te lokaliseren op basis van de resulterende hash. Het is handig wanneer er veel invoer is met vergelijkbare waarden of duplicaten, omdat het alleen sleutels hoeft te vergelijken in plaats van alle records te doorzoeken.
Was dit niet snel of gemakkelijk? Om te begrijpen hoe hash-indexen werken en waarom ze zo krachtig zijn, moet u begrijpen wat wordt bedoeld met hashing.
Hashen neemt een stukje informatie (een string) en verandert het in een adres of aanwijzer voor snelle toegang later.
Het idee van hashing is dat aan gegevens een klein aantal wordt toegewezen. Wanneer u de gegevens opzoekt, hoeft u niet echt door massa's te bladeren. Zoek in plaats daarvan gewoon dat ene nummer op. Het eenvoudigste voorbeeld is Ctrl+F om het woord dat u zoekt in een tekst te gebruiken in plaats van zelf tientallen pagina's te lezen.
Waar zijn hash-indexen voor?
Een hash-index is een manier om het zoekproces te versnellen. Met traditionele indexen moet u door elke rij scannen om er zeker van te zijn dat uw zoekopdracht succesvol is. Maar met hash-indexen is dit niet het geval!
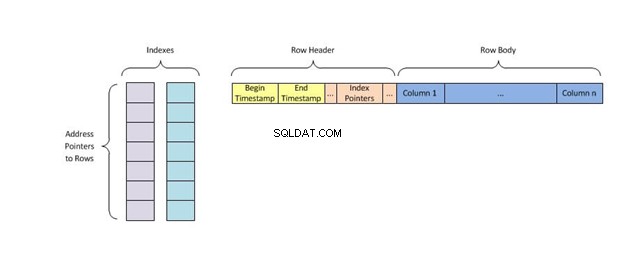
Elke sleutel van de index bevat slechts één rij met tabelgegevens en gebruikt het indexeringsalgoritme hashing die ze een unieke locatie in het geheugen toewijst, waardoor alle andere sleutels met dubbele waarden worden geëlimineerd voordat ze vinden wat ze zoeken.
Hash-indexen zijn een van de vele manieren om gegevens in een database te ordenen. Ze werken door invoer te nemen en deze te gebruiken als een sleutel voor opslag op een schijf. Deze sleutels, of hash-waarden , kan van alles zijn, van tekenreekslengtes tot tekens in de invoer.
Hash-indexen worden het meest gebruikt bij het opvragen van specifieke invoer met specifieke kenmerken. Het kan bijvoorbeeld zijn om alle A-letters te vinden die hoger zijn dan 10 cm. Je kunt het snel doen door een hash-indexfunctie te maken.
Hash-indexen maken deel uit van het PostgreSQL-databasesysteem. Dit systeem is ontwikkeld om de snelheid en prestaties te verhogen. Hash-indexen kunnen worden gebruikt in combinatie met andere indextypen, zoals B-tree of GiST.
Een hash-index slaat sleutels op door ze te verdelen in kleinere brokken die buckets worden genoemd, waarbij elke bucket een geheel getal krijgt om het snel op te halen bij het zoeken naar de locatie van een sleutel in de hashtabel. De buckets worden achtereenvolgens op een schijf opgeslagen, zodat de gegevens die ze bevatten snel toegankelijk zijn.
Meer technische uitleg vindt u op deze pagina (klik met de rechtermuisknop en kies "Vertalen naar Engels").
Voordelen
Het belangrijkste voordeel van het gebruik van hash-indexen is dat ze snelle toegang mogelijk maken bij het ophalen van het record op basis van de sleutelwaarde. Het is vaak handig voor query's met een gelijkheidsvoorwaarde. Het gebruik van hash-benchmarks vereist ook niet veel opslagruimte. Het is dus een effectief hulpmiddel, maar niet zonder nadelen.
Nadelen
Hash-indexen zijn een relatief nieuwe indexeringsstructuur met het potentieel om aanzienlijke prestatievoordelen te bieden. Je kunt ze zien als een uitbreiding van binaire zoekbomen (BST's).
Hash-indexen werken door gegevens op te slaan in buckets op basis van hun hash-waarden, waardoor de gegevens snel en efficiënt kunnen worden opgehaald. Ze zijn gegarandeerd in orde.
Het is echter onmogelijk om dubbele sleutels in een bucket op te slaan. Er zal dus altijd wat overhead zijn. Maar tot nu toe wegen de voordelen van het gebruik van hash-indexen op tegen de nadelen.
Hoe werkt het allemaal in een beetje meer diepte?
Laten we een demo nemen aviasales database om een dieper inzicht te krijgen in hoe hash-indexen werken.
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged
CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN
----------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (flight_no = 'PG0001'::bpchar)
-> Bitmap Index Scan on flights_flight_no_idx
Index Cond: (flight_no = 'PG0001'::bpchar)
(4 rows)
Hier kunt u zien hoe we hash-indexen implementeren door gegevens in sets te compileren.
Dit is een eenvoudig voorbeeld, maar houd er rekening mee dat er beperkingen zijn met minder code-infrastructuur. Er kan een gebrek aan WAL-logtoegang zijn of een onvermogen om indexen (indices?) te herstellen na een crash. Bovendien nemen indexen mogelijk niet deel aan replicatie - dit komt doordat PostgreSQL verouderd is. Maar net als bij Python krijg je waarschuwingen waarmee je vaak fouten kunt voorkomen.
U kunt dieper in deze indexen kijken als u voldoende geïntrigeerd bent. Daarvoor maken we een pagina-inspectie extensie-instantie.
demo=# create extension pageinspect;
CREATE EXTENSION
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type
----------------
metapage
(1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket
---------+-----------
33121 | 127
(1 row)
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type
----------------
bucket
(1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items
------------+------------
407 | 0
(1 row)
Als je de code volledig wilt inspecteren, begin dan met README.
Samenvatting
Hash-indexen zijn een gegevensstructuur die het zoeken naar informatie in grote databases versnelt. Ze werken door de gegevens in kleinere brokken te splitsen en ze vervolgens te sorteren. Dus als je iets zoekt, kun je het veel sneller vinden.
Als je meer dingen wilt opzoeken, zijn er bronnen voor DYOR. Houd ook onze nieuwe artikelen in de gaten, die sneller verschijnen dan u op deze pagina met Ctrl+F het woord "hash" kunt gebruiken. Ik hoop dat dit helpt!