Zeer weinig database-auteurs noemen de uitdagingen van globalisering en lokalisatie op een zinvolle manier. Er is een soortgelijk gebrek aan vooruitziendheid van database-architecten. Feit is dat veel auteurs en ontwerpers vaak erg 'self-centric' zijn:ze maken (of schrijven over) datamodellen die alleen goed omgaan met hun lokale tijdzones, adressen, enz.
Een zelfgerichte benadering heeft een groot probleem:het resulterende model ondersteunt alleen lokale gegevens. In de door internet aangedreven wereld van vandaag worden applicaties vaak onverwacht geopend door gebruikers over de hele wereld. We moeten zoveel mogelijk flexibiliteit ondersteunen voor dit internationale publiek. Daarom moeten we onze datamodellen ontwerpen met een geglobaliseerde aanpak.
Ik heb het geluk om in een zeer multinationale en meertalige omgeving te werken, dus ik heb geleerd hoe globaliseringsproblemen kunnen worden aangepakt bij de start van het project. Met dat in gedachten heb ik zeven belangrijke punten op een rij gezet voor het maken van een datamodel dat internationaal gebruik ondersteunt.
1. Getalnotatie
Er zijn twee dingen waarmee u rekening moet houden als u kijkt naar de opmaak van getallen:de uitvoer die gebruikers zien (d.w.z. het formaat) en het onderliggende gegevenstype.
U hoeft zich geen zorgen te maken over hoe getallen worden weergegeven in uw gegevensmodel - het databasesysteem zal de opslag van decimale getallen afhandelen en uw toepassing moet zich aanpassen aan hoe decimale getallen worden weergegeven (“.” of “,” als decimaal punt bijvoorbeeld). Evenzo hoeft u zich geen zorgen te maken over welk scheidingsteken voor duizendtallen (zoals een punt of komma) uw gegevensmodel zal gebruiken.
Dit is het punt: Kies uw datatypes correct bij het modelleren. Uw toepassing zou de uitvoeropmaak moeten afhandelen.
In dit eenvoudige model van een weerstationtoepassing worden de weermetingen (temperatuur, vochtigheid, regenval) bijvoorbeeld opgeslagen als getallen met drijvende komma. Maar de prijsinformatie is in decimalen, vergelijkbaar met de GPS-coördinaten van elk weerstation.
2. Valuta's en wisselkoersen
Als u informatie met betrekking tot valuta opslaat, moet u voor elke valuta het juiste aantal decimalen opslaan. De meeste valuta's hebben twee decimalen, maar sommige hebben er geen (d.w.z. de Chileense peso), één (de Malagassische ariary), drie (de Tunesische dinar) of zelfs vier decimalen (Chili's Unidad de Fomento, een rekeneenheid die wordt gebruikt om een bereik van prijswaarden.)
Zorg er dus voor dat uw "bedrag"-velden in het gegevensmodel meer dan twee cijfers achter de komma ondersteunen - hoewel vier cijfers achter de komma zeer zeldzaam is, gebeurt het wel. Drie decimalen komt vaker voor. Voor dinars in zes verschillende landen (Bahrein, Irak, Jordanië, Koeweit, Libië, Tunesië) en rial in één land (Oman) zijn bijvoorbeeld drie decimalen vereist.
Punt nummer 1: Kies uw gegevenstype correct bij het modelleren.
Een ander belangrijk punt met betrekking tot valuta's zijn wisselkoersen. Deze vragen om nog meer precisie. Veel systemen bieden slechts 4-6 significante cijfers in wisselkoersen; soms is er een schaalfactor tussen valuta's die enorm verschillende waarden hebben. Vier of zes significante cijfers betekenen echter niet noodzakelijkerwijs dat er zes cijfers achter de komma zullen zijn. Controleer de wisselkoers tussen Indonesische Rupiah en Euro:0,0000668755. Dat zijn veel decimalen om op te slaan in uw wisselkoersveld.
Punt nummer 2: Uw model moet mogelijk een hoge mate van precisie hanteren - veel decimalen - als het gaat om wisselkoersen.
Hieronder hebben we een voorbeeld gemaakt van een online winkel met prijzen. We hebben ook een eenvoudige tabel toegevoegd (gemarkeerd in aqua) waarin de wisselkoersen zijn opgeslagen, inclusief historische wisselkoersen. Elke rij in de exchange_rate tabel is gekoppeld aan een valuta (currency_id , de ISO 4217-valutacode). We staan toe dat voor elke valuta op een bepaalde dag één wisselkoers wordt opgeslagen (rate_date ), en hebben één actieve wisselkoers voor elke valuta.
Om deze tarieftabel te gebruiken, heeft u uiteraard wat aanvullende informatie nodig. Tegen welke basisvaluta zijn deze wisselkoersen bijvoorbeeld gedefinieerd? Euro's of Amerikaanse dollars kunnen typisch zijn, maar uw aanvraag heeft hier exacte informatie nodig.
Als alternatief zou een complexer model valutaparen, de middenkoers (of bankkoers) en de koop- en verkoopkoersen tussen die valutaparen kunnen opslaan.
Punt nummer 3: Uw model moet voldoende informatie hebben zodat de applicatie de gegevens goed kan gebruiken.
3. Telefoonnummers
Ik heb vaak systemen gezien die alleen een Noord-Amerikaans tiencijferig telefoonnummer ondersteunen met een driecijferig netnummer, een driecijferige telefooncentrale en een viercijferig abonneenummer (d.w.z. 012-345-6789). Deze vooringenomenheid is tot op zekere hoogte begrijpelijk; mensen creëren systemen die hun lokale gebruikers ondersteunen. Gegevensmodellering mag echter niet voorbijgaan aan de mogelijkheid dat wereldwijde gebruikers toegang krijgen tot uw systeem. (Opmerking:de lengte van tien cijfers kan ook worden gebruikt voor andere nummers, zoals Franse mobiele telefoons, maar het formaat is anders (bijv. 06 12 34 56 78).)
Laten we dit als voorbeeld nemen:stel dat ik net buiten de Franse grens woon, maar in Frankrijk werk. Daarom, hoewel ik mogelijk Franse applicaties en serviceproviders moet gebruiken, is mijn mobiele telefoonnummer geen Frans nummer. Systemen die een tiencijferig mobiel nummer nodig hebben dat begint met 06 of 07 werken niet voor mij. Om Franse treinkaartjes te krijgen, kaartjes te kopen voor een concert in Frankrijk (enz., enz.), zou ik genoodzaakt zijn om een Frans telefoonnummer te krijgen. Op zijn zachtst gezegd hinderlijk.
Dit is het punt: Wanneer telefoonnummerbeperkingen in het datamodel zijn ingebouwd, zijn aanpassingen aan het datamodel nodig om niet-lokale gebruikers te ondersteunen. Idealiter zou er voldoende flexibiliteit in het model moeten worden ingebouwd om alle eventualiteiten aan te kunnen.
Een logischer gegevensmodel zou telefoonnummers van verschillende lengtes ondersteunen (tot 16 cijfers in sommige gebieden) en niet-numerieke tekens (zoals het universele "+"-symbool voor een internationaal telefoonnummer). Zeker, sommige applicaties kunnen meer validatie uitvoeren door "lokale regels" te implementeren waar lokale ontwikkelaars meer vertrouwd mee zouden zijn. Andere apps kunnen lokale telefoonnummers gebruiken om toegang te krijgen tot andere gegevensbronnen, zoals het verifiëren of ophalen van een adres op basis van een telefoonnummer.
Het datamodel moet flexibiliteit ondersteunen bij het opslaan van informatie. De applicatie of de gebruikersinterface kan restrictiever zijn of aanvullende validatie uitvoeren.
4. Adressen
Als Amerikaan die in het buitenland woont, vind ik vaak voorbeelden van datamodellen en patronen die te Amero-centrisch zijn. Een niet-Amerikaan begrijpt bijvoorbeeld misschien niet wat een Zip+4 is en zou daarom niet begrijpen waarom een auteur stelt dat dit domein een NOT NULL-kenmerk moet hebben.
Deze op Amero gerichte visie is zelfs aanwezig in boeken. Neem bijvoorbeeld het vrij uitgebreide boek “Data Model Patterns. Gedachtenconventies” door David C. Hay. De zeer complexe uitleg van de heer Hay van adressen, locaties, geografische locaties, percelen en geografische structuurelementen bevatte voorbeelden uit Canada, maar toch is deze informatie misschien niet voor iedereen even duidelijk.
Volgens de patronen van de heer Hay zullen de adreskenmerken het volgende omvatten:
De "tekst" van het adres, plus ten minste "stad", "staat" en "postcode".
Nu legt meneer Hay snel uit in een voetnoot dat:
De context van het model bepaalt of dit attribuut "ZIP-code" of "postcode" is. Als de klantorganisatie binnen afzienbare tijd volledig binnen de Verenigde Staten zal opereren, kan worden aangenomen dat er een negencijferige, tweedelige numerieke "postcode" is. Zo niet, dan moet "ZIP-code" "postcode" worden en zijn er geen opmaakaannames mogelijk.
Hij vermeldt echter niet dat "staat" een staat in de VS, een provincie in Canada of een nullable-attribuut voor bijna elk ander land kan zijn, aangezien "staten" in landen zelden bestaan buiten de VS, Canada (waar ze worden provincies genoemd maar functioneren op dezelfde manier) en Australië. Zeker, andere landen hebben provincies en regio's, maar deze worden zelden gebruikt als onderdeel van een adres.
Om te illustreren hoe ernstig dit adresprobleem kan zijn, heb ik een datamodel gemaakt voor zowel Amerikaanse als niet-Amerikaanse adressen. (Opmerking:dit is niet het volledige model.)
De PrimaryPhone van de US_Customer tabel slaat alleen telefoonnummers op met tien of minder tekens. Het internationale ontwerp van de Customer tabel's PrimaryPhone kenmerk staat een telefoonnummer toe van 15 cijfers plus “+”, het maximum gespecificeerd door E.164.
De TimeOffset attribuut in de US_Customer tabel staat slechts vier tijdzones toe:Eastern Time, Central Time, Mountain Time en Pacific Time (opgeslagen in het gegevensmodel als:0 =Eastern, 1 =Central, 2 =Mountain, 3 =Pacific). Overigens dekt dit niet eens alle tijdzones in de VS en zijn territoria. Daarentegen is de Timezone attribuut in de Customer table slaat de internationale code op voor de tijdzone van de klant, ongeacht waar deze zich bevindt.
Laten we vervolgens eens kijken naar de postcode. De VS vereist een 5-cijferige postcode (Zip van het US_Address tabel) plus de optionele ZIP+4 (Zip4 van het US_Address tafel). Het Address tabel heeft een flexibelere PostCode veld. Afgezien van de lengte, is er geen beperking op de informatie die kan worden opgeslagen in PostCode; natuurlijk kan de applicatie postcodecontroles uitvoeren.
Merk ook op dat de Amerikaanse en de niet-Amerikaanse ontwerpen beide een veld hebben voor regio's binnen een land (State in het US_Address tabel en Region in het Address tabel), maar het Amerikaanse ontwerp vereist dat een staatsafkorting van 2 tekens wordt opgenomen. Merk ook op dat het Amerikaanse ontwerp geen internationale adressen accepteert, terwijl de versie met internationale adressen dat wel doet (vandaar de 2-cijferige ISO-landcode Land van het Address tafel).
Dit is het punt: Beperk uw datamodel van adressen niet tot één plaats; laat genoeg ruimte over voor verschillende stijlen.
5. Datum- en tijdnotatie
Gegevensmodellen zouden zich niet bezig moeten houden met meerdere datum- en tijdformaten; de applicatie handelt de daadwerkelijke weergave af. Dit kan op verschillende manieren:
- De maand-eerste stijl, gebruikelijk in Noord-Amerika en elders:mm-dd-yyyy
- De day-first stijl, die in Europa vaker voorkomt:dd-mm-yyyy
- De stijl van het eerste jaar, gebruikt als de ISO 8601-datumnotatie:jjjj-mm-dd
Dit is het punt: Dit is misschien repetitief, maar we zeggen het nog een keer:kies je datatypes correct bij het modelleren. Dit maakt het voor de applicatiecode gemakkelijker om opgeslagen waarden te interpreteren en weer te geven.
Een ander item in deze categorie is misschien een beetje onverwacht:op welke dag de week begint. Voor sommigen is dit zondag; voor anderen is het maandag (en dan is er de Perzische kalender, die de week op zaterdag begint).
Tijden moeten ook op een gebruiksvriendelijke manier worden weergegeven. Onthoud dat hoewel uw gegevensmodel niet meerdere tijdnotaties nodig heeft, u misschien de tijdvoorkeur van de gebruiker opslaat , d.w.z. het 12- of 24-uursformaat.
Dit leidt ons naar tijdzones.
6. Tijdzones
Het is niet ongebruikelijk om apps te vinden die gebruikers slechts een paar tijdzonekeuzes toestaan:Eastern Time, Central Time, Mountain Time en Pacific Time. Als ik dat zie, weet ik dat ik te maken heb met een op Amero gerichte applicatieontwerper. Sommige ontwerpers staan toe dat een tijdzone wordt uitgedrukt als een afwijking van (meestal) GMT of UTC. Velen maken echter de fout om alleen verschuivingen van gehele getallen toe te staan, zich niet realiserend dat sommige landen (India, Iran, Pakistan, Afghanistan en andere) geen verschuiving van gehele getallen zijn. Ze zijn fractioneel verschillend:India Standard Time is UTC+5:30. Sommige locaties hebben zelfs een kleinere fractionele offset, zoals Nepal Standard Time – het is UTC+05:45.
Enige tijd geleden schreef ik over een model voor een online enquêtedatabase. Hier heb ik een tijdzone toegevoegd aan de gebruikerstabel zodat we datums/tijden kunnen weergeven in de lokale tijden van de gebruikers.
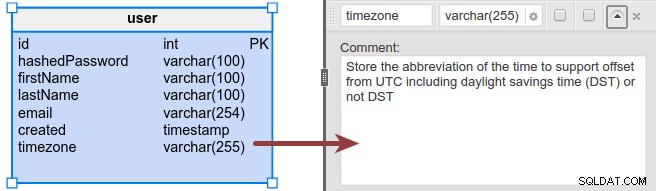
Voor meer informatie over datums, tijden en tijdzones kunt u de ISO 8601-standaardweergave van datums en tijden of dit Wikipedia-artikel raadplegen.
Dit is het punt: Leer globaal te denken, niet alleen lokaal.
7. Meertalige ondersteuning
Het kan voorkomen dat uw toepassing meertalige ondersteuning nodig heeft. Vanuit het perspectief van een datamodel moet u mogelijk informatie in meerdere talen hebben opgeslagen; het grootste deel van de taalkundige behandeling moet echter in uw aanvraag worden behandeld. De implementatie van meertalige ondersteuning valt buiten het bestek van dit artikel, maar we hebben het al besproken in deze blog.
Lokalisatie is erg belangrijk en moet goed worden afgehandeld. Zoals we al hebben opgemerkt, betekent dit meer dan alleen het ondersteunen van verschillende talen; het gaat ook over de voorkeursindelingen voor datums, tijden, valuta en zelfs decimale indicatoren.
Gegevensmodellering? Denk globaal
Houd bij het maken van uw gegevensmodel rekening met het mogelijke internationale gebruik van uw toepassing en de bijbehorende database. Denk globaal tijdens de ontwerpfase en je zult later wat problemen voorkomen - een telefoonnummerveld dat alleen 3-cijfers + 3-cijfers + 4-cijfers accepteert, werkt prima in de VS, maar niet zo goed in China of India.
Zijn uw databases voorbereid om wereldwijd te gaan? Je doel moet zijn om flexibiliteit mogelijk te maken zonder overweldigende complexiteit te creëren.