Een databasebeheersysteem is de kluis van de informatie. We zullen proberen het databasebeheersysteem zo te ontwerpen dat de database goed beheerd blijft en voldoet aan de doelstellingen.
In dit artikel gaan we het hebben over het ontwerpen en beheren van grote databasesystemen. We zullen meerdere constituties gebruiken, waaronder databasetechnologieën, opslag, gegevensdistributie, serveractiva, architectuurpatroon en enkele andere.
Bij voorkeur zoeken we naar een grote database in het Telco-domein, eCommerce-platforms, Verzekeringsdomein, Banksysteem, Gezondheidszorg, Energiesysteem, enz. We moeten een paar parameters in gedachten houden voordat we de juiste databasetechnologie kiezen. d.w.z. verkeer, TPS (transacties per seconde), geschatte opslag per dag, HA en DR.
Een grote database ontwerpen
Bij het samenstellen van onze database moeten we aandacht besteden aan verschillende parameters, omdat het vaak erg problematisch is om de database te vervangen door een vervanger. Laten we ze nu eens bekijken.
Databasetechnologie
Databasetechnologie is de belangrijkste factor. Als u het juiste databasebeheersysteem kiest, helpt het uw bedrijf efficiënt en moeiteloos te runnen.
Er zijn verschillende databasetechnologieën met veel functies. Als u echter met open-source databasetechnologieën werkt, krijgt u mogelijk geen toegang tot bepaalde expliciete functies van vooraf gedefinieerde oplossingen. Enterprise-databasetechnologieën zoals Microsoft SQL Server, Oracle, enz. zouden ze kunnen bieden.
Veel enterprise database-technologieën implementeren HA (High Availability), DR (Disaster Recovery), Mirroring, Data Replication, Secondary Read Replica en aanzienlijk handiger en kant-en-klaar configureerbare bedrijfsoplossingen. Ze kunnen al dan niet aanwezig zijn in open-source databases.
Er zijn veel redenen. We merken bijvoorbeeld soms dat de bestaande architectuur wordt verstoord omdat de bovengenoemde factoren niet functioneel zijn omdat we ze nodig hebben.
Opslag
De opslag heeft een drastische invloed op de prestaties van de bedrijfsoplossing. Zakelijke oplossingen vereisen eersteklas opslag of SSD met een bepaalde hoeveelheid IOPS. Is het echter zo? On-premises of in de cloud, de grootte en het type opslag bepalen de infrastructuurkosten.
Bij het overwegen van de opslagprestaties moeten we aandacht besteden aan het type gegevens en het gedrag van de gegevensverwerking. We moeten kiezen voor opslagselectie op basis van de gegevens van de gebruiker en de verwerking ervan. Als de gebruiker meerdere databases gaat gebruiken, moeten we de opslagkeuze over het SAN bieden voor verschillende databases voor de gegevenstypen en het gegevensverwerkingsgedrag.
De database-engineer zal een betere terugblik geven op de verschillende databases die nodig zijn voor IOPS-berekening als de gebruikers helemaal geen premium-opslag nodig hebben.
Gegevensdistributie
De meeste recente databasetechnologieën (SQL of NoSQL) bieden partitionering of Sharding-functies.
- Partitie herdistribueert gegevens in het bestandssysteem op basis van de partitiesleutel.
- Sharding verdeelt informatie over de databaseknooppunten en de gegevens worden op dezelfde of een andere machine opgeslagen.
In wezen heeft elke databaseservice of databasetabel de functies voor gegevenspartitionering/sharding niet nodig. Ze hoeven alleen te worden toegepast op databases die grotere objecten bevatten. Dat zal de prestaties verbeteren.
Servermiddelen
Verschillende machines vereisen verschillende soorten en maten geheugen en CPU. U moet rekening houden met activa op hardwareniveau, zoals geheugen, processor, enz. Een machine die grotere databases of meerdere databases moet verwerken, heeft bijvoorbeeld meer geheugen en CPU's nodig. Daarom is de kwaliteit van geheugen en processor aanzienlijk. Het gaat verschillende soorten processors aan die op de markt verkrijgbaar zijn met verschillende CPU-caches.
Vaak komen we problemen tegen waarvan we ons misschien niet bewust zijn. We hebben geen aandacht besteed aan het gebruik en de rol van de CPU-cache van de hardware. Maar het is cruciaal voor het selecteren en voldoen aan de hardwarevereisten met grotere databasesystemen.
Architectuurpatroon
Bij het ontwerpen van databases heeft het architectuurpatroon altijd een voorbeeldfunctie. Vroeger werden databasesystemen op een uiterst monolithische manier ontworpen. Nu gebruiken we Micro-Service-gebaseerd of Hybrid (Monolithic + Micro).
De prestaties, uitbreidbaarheid en nul downtime zijn sterk afhankelijk van het architectuurpatroon en het databaseontwerp. Elke applicatie zou een aparte database kunnen hebben en alle databases zouden losjes aan elkaar gekoppeld kunnen worden. In het geval dat een applicatie of database uitvalt, zal een ander deel van het product niet worden verstoord. Alle microservices zouden onafhankelijk zijn en losjes gekoppeld.
Micro-service
In het onderstaande diagram wordt uitgelegd hoe alle applicaties worden geïmplementeerd en gecommuniceerd met behulp van hun databases, die tegelijkertijd losjes zijn gekoppeld. We kunnen de gegevens manipuleren met T-SQL. De informatie wordt verzameld of verzameld door verschillende toepassingen en de klant heeft toegang tot de gegevens. Raadpleeg het diagram met het aantal geschaalde applicaties en de geïntegreerde database.
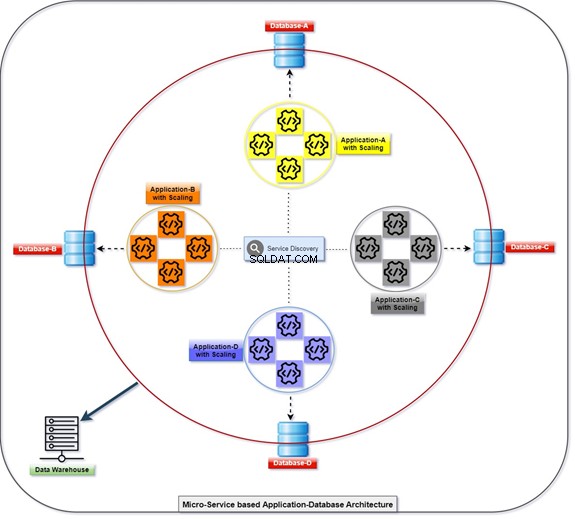
Monolitisch
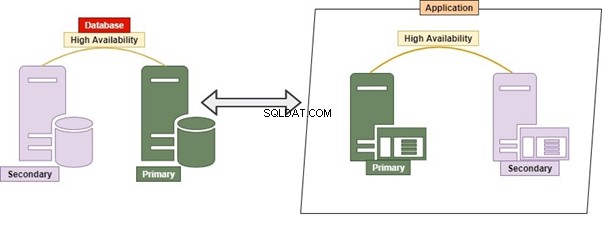
Welk RDBMS moeten we gebruiken? Het kan Oracle, Microsoft SQL Server, Postgres, MySQL, MongoDB of een andere database zijn. De conventionele manier om met alle tabellen of objecten om te gaan die in één of meerdere databases op één server worden beheerd, staat bekend als Monolithic.
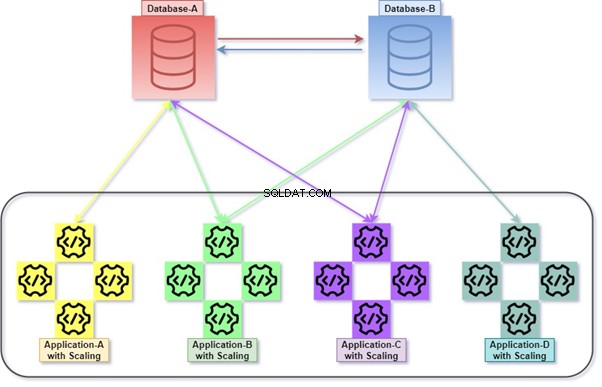
Hybride
Hybride is een permutatie van Monolithic en Micro Service. Het is een vrij gebruikelijke praktijk, omdat het talloze toepassingen, talloze databases en databaseservers mogelijk maakt. Talloze databases en databaseservers kunnen nauw met elkaar worden gekoppeld.
Bijvoorbeeld query's uitvoeren met JOIN's tussen tabellen die behoren tot twee of meer databases in dezelfde databaseserver of een andere. Externe query gebruikt voor het ophalen/manipuleren van gegevens met een andere databaseserver.
Alles draait om SQL Server-architectuur. We hebben het echter over de gegevensmanipulatie tussen verschillende tabellen binnen dezelfde database of verschillende databases die zich op dezelfde server of verschillende servers kunnen bevinden.
In hybride of monolithische architectuur gebruiken we JOIN's tussen verschillende tabellen binnen dezelfde of verschillende databases. Het is behoorlijk ingewikkeld als we de kernstandaarden van Micro-Service volgen, omdat de distributie van tabellen tussen de databaseservices (Dbas) kan zijn.
Onder de Enterprise-databasetechnologieën zoals Microsoft SQL Server, Oracle, enz., kon de gebruiker de tabellen van de gedistribueerde database opvragen met behulp van Linked Server Joins. Maar het is niet beschikbaar in alle open-source databasetechnologieën. Het staat bekend als de Tight-Coupled-aanpak die mogelijk niet werkt als de externe databaseservice niet beschikbaar is.
Laten we het nu hebben over het losgekoppeld maken ervan. Waarom hebben we gegevensmanipulatie nodig tussen externe databases?
Waarom hebben we gegevensmanipulatie nodig tussen externe databases?
Gebruikers zullen vereisen dat de gegevens worden opgehaald uit meer dan één databaseservice wanneer het systeem is ontworpen met behulp van micro- of hybride services. Het hele proces wordt gezien vanaf de backend die de hoeveelheid gegevens kan verwerken die door de applicatie zijn gemanipuleerd.
Als we kijken naar de realtime query's tussen databases, voegen we altijd de hoofdentiteitstabellen toe, niet de metadatatabellen. De hoofdtabellen zullen niet groter zijn dan metagegevenstabellen. Voor rapportagedoeleinden maken we altijd gebruik van het datawarehouse om alle informatie bij elkaar te krijgen. Maar dat is niet voor elk product eenvoudig te beheren en te onderhouden. Als we de bedrijfsoplossing ontwerpen, kunnen we ons het magazijn veroorloven. Maar we kunnen het ons niet veroorloven voor kleine of middelgrote producten.
We hebben bijvoorbeeld een rapport nodig met de gegevens van verschillende tabellen die zich in verschillende databases bevinden. Het is geen gemakkelijke taak om uit te voeren, omdat het de gegevens verzamelt met behulp van verschillende microservices en deze samenvoegt om het rapport te produceren. Daarom moeten de benodigde gegevens worden gesynchroniseerd.
Wat kunnen we gebruiken als standaardoplossing losgekoppelde tabelgegevenssynchronisatie tussen twee databases maken?
Tabelreplicatie moet worden gebruikt voor eenvoudige gegevenssynchronisatie tussen meerdere databases. Het voorbeeld is de transactiereplicatie voor de Simplex-gegevenssynchronisatie en de Merge-replicatie voor de Duplex-gegevenssynchronisatie die wordt geleverd door SQL Server.
Er zijn een paar betaalde open-sourceoplossingen van derden die de gegevens tussen meerdere databases kunnen synchroniseren. Zelfs losgekoppelde oplossingen met behulp van berichtenwachtrijen zoals SQL Server Transaction Replication kunnen door gebruikers zelf worden ontwikkeld.
Conclusie
DBA's ontwerpen databases op hun manier. Bij het ontwerpen van de database en het kiezen van het databasebeheersysteem moeten ze met veel aspecten rekening houden. We hebben de meest essentiële factoren voor het databaseontwerp gepresenteerd, vooral voor de grotere databases. Houd ons in de gaten voor de volgende materialen!