Elk product heeft bugs en SQL Server is geen uitzondering. Productkenmerken op een enigszins ongebruikelijke manier gebruiken (of relatief nieuwe functies combineren) is een geweldige manier om ze te vinden. Bugs kunnen interessant en zelfs leerzaam zijn, maar misschien gaat een deel van de geneugten verloren wanneer de ontdekking ertoe leidt dat uw pieper om 4 uur 's ochtends afgaat, misschien na een bijzonder gezellig avondje uit met vrienden...
De bug die het onderwerp van dit bericht is, is waarschijnlijk redelijk zeldzaam in het wild, maar het is geen klassieke edge-case. Ik ken tenminste één consultant die het is tegengekomen in een productiesysteem. Over een volledig losstaand onderwerp, zou ik van deze gelegenheid gebruik moeten maken om "hallo" te zeggen tegen de Grumpy Old DBA (blog).
Ik zal beginnen met wat relevante achtergrondinformatie over merge joins. Als je zeker weet dat je al alles weet wat er te weten valt over merge join, of als je gewoon door wilt gaan, scroll dan gerust naar het gedeelte met de titel 'The Bug'.
Aanmelden samenvoegen
Samenvoegen is niet erg ingewikkeld en kan onder de juiste omstandigheden zeer efficiënt zijn. Het vereist dat zijn invoer wordt gesorteerd op de samenvoegsleutels en presteert het beste in een-op-veel-modus (waarbij ten minste van zijn invoer uniek is op de samenvoegsleutels). Voor een-op-veel-joins van gemiddelde grootte is seriële samenvoeg-join helemaal geen slechte keuze, op voorwaarde dat aan de vereisten voor het sorteren van invoer kan worden voldaan zonder een expliciete sortering uit te voeren.
Het vermijden van een sortering wordt meestal bereikt door gebruik te maken van de volgorde die door een index wordt geboden. Samenvoegen kan ook profiteren van de bewaarde sorteervolgorde van een eerdere, onvermijdelijke sortering. Een cool ding over merge join is dat het de verwerking van invoerrijen kan stoppen zodra een van beide invoer geen rijen meer heeft. Nog een laatste ding:merge join maakt het niet uit of de invoersorteervolgorde oplopend of aflopend is (hoewel beide invoer hetzelfde moeten zijn). In het volgende voorbeeld wordt een standaard Numbers-tabel gebruikt om de meeste van de bovenstaande punten te illustreren:
CREATE TABLE #T1 (col1 integer CONSTRAINT PK1 PRIMARY KEY (col1 DESC)); CREATE TABLE #T2 (col1 integer CONSTRAINT PK2 PRIMARY KEY (col1 DESC)); INSERT #T1 SELECT n FROM dbo.Numbers WHERE n BETWEEN 10000 AND 19999; INSERT #T2 SELECT n FROM dbo.Numbers WHERE n BETWEEN 18000 AND 21999;
Merk op dat de indexen die de primaire sleutels op die twee tabellen afdwingen, zijn gedefinieerd als aflopend. Het queryplan voor de INSERT heeft een aantal interessante eigenschappen:
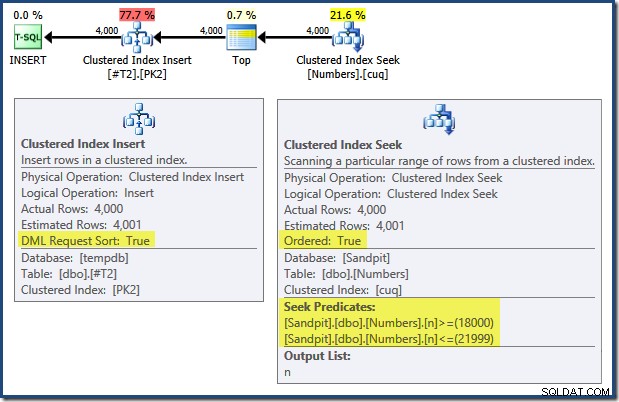
Als u van links naar rechts leest (wat alleen verstandig is!) heeft de geclusterde index-insert de eigenschap "DML Request Sort" ingesteld. Dit betekent dat de operator rijen in de volgorde van de geclusterde indexsleutels nodig heeft. De geclusterde index (die in dit geval de primaire sleutel afdwingt) wordt gedefinieerd als DESC , dus rijen met hogere waarden moeten als eerste aankomen. De geclusterde index op mijn Numbers-tabel is ASC , dus de query-optimizer vermijdt een expliciete sortering door eerst naar de hoogste overeenkomst in de Numbers-tabel (21.999) te zoeken en vervolgens naar de laagste overeenkomst (18.000) in omgekeerde indexvolgorde te scannen. De "Plan Tree"-weergave in SQL Sentry Plan Explorer toont de omgekeerde (achterwaartse) scan duidelijk:
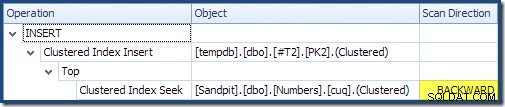
Achterwaarts scannen keert de natuurlijke volgorde van de index om. Een achterwaartse scan van een ASC indexsleutel retourneert rijen in aflopende sleutelvolgorde; een achterwaartse scan van een DESC index key retourneert rijen in oplopende sleutelvolgorde. De "scanrichting" geeft op zichzelf geen geretourneerde sleutelvolgorde aan - u moet weten of de index ASC is of DESC om die beslissing te nemen.
Met behulp van deze testtabellen en gegevens (T1 heeft 10.000 rijen genummerd van 10.000 tot en met 19.999; T2 heeft 4.000 rijen genummerd van 18.000 tot 21.999) de volgende query voegt de twee tabellen samen en geeft resultaten in aflopende volgorde van beide sleutels:
SELECT
T1.col1,
T2.col1
FROM #T1 AS T1
JOIN #T2 AS T2
ON T2.col1 = T1.col1
ORDER BY
T1.col1 DESC,
T2.col1 DESC; De query retourneert de juiste overeenkomende 2.000 rijen zoals u zou verwachten. Het post-uitvoeringsplan is als volgt:
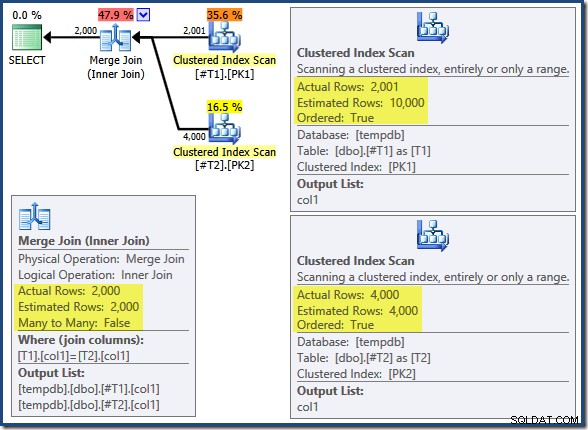
De Merge Join wordt niet uitgevoerd in de veel-op-veel-modus (de bovenste invoer is uniek op de samenvoegtoetsen) en de schatting van de kardinaliteit van 2.000 rijen is precies correct. De geclusterde indexscan van tabel T2 is geordend (hoewel we even moeten wachten om te ontdekken of die volgorde vooruit of achteruit is) en de kardinaliteitsschatting van 4.000 rijen is ook precies goed. De geclusterde indexscan van tabel T1 is ook besteld, maar er werden slechts 2.001 rijen gelezen, terwijl er 10.000 werden geschat. De plattegrond boomweergave laat zien dat beide geclusterde indexscans vooruit zijn besteld:
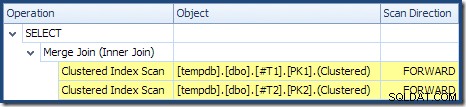
Bedenk dat het lezen van een DESC index FORWARD zal rijen produceren in omgekeerde sleutelvolgorde. Dit is precies wat wordt vereist door de ORDER BY T1.col DESC, T2.col1 DESC clausule, dus er is geen expliciete sortering nodig. Pseudo-code voor een-op-veel Merge Join (overgenomen van Craig Freedman's Merge Join blog) is:

De aflopende volgorde scan van T1 retourneert rijen vanaf 19.999 en werkt naar beneden naar 10.000. De aflopende volgorde scan van T2 retourneert rijen vanaf 21.999 en werkend naar 18.000. Alle 4.000 rijen in T2 worden uiteindelijk gelezen, maar het iteratieve samenvoegproces stopt wanneer sleutelwaarde 17.999 wordt gelezen van T1 , omdat T2 loopt uit de rijen. De samenvoegverwerking wordt daarom voltooid zonder dat T1 volledig is gelezen . Het leest rijen van 19.999 tot en met 17.999; een totaal van 2.001 rijen zoals weergegeven in het uitvoeringsplan hierboven.
Voel je vrij om de test opnieuw uit te voeren met ASC indexen, waarbij ook de ORDER BY . wordt gewijzigd clausule van DESC naar ASC . Het geproduceerde uitvoeringsplan zal erg op elkaar lijken en er zijn geen sorteringen nodig.
Om de punten samen te vatten die zo meteen belangrijk zullen zijn, vereist Merge Join gesorteerde invoer met join-sleutel, maar het maakt niet uit of de sleutels oplopend of aflopend zijn gesorteerd.
De bug
Om de bug te reproduceren, moet ten minste één van onze tabellen worden gepartitioneerd. Om de resultaten beheersbaar te houden, gebruikt dit voorbeeld slechts een klein aantal rijen, dus de partitioneringsfunctie heeft ook kleine grenzen nodig:
CREATE PARTITION FUNCTION PF (integer) AS RANGE RIGHT FOR VALUES (5, 10, 15); CREATE PARTITION SCHEME PS AS PARTITION PF ALL TO ([PRIMARY]);
De eerste tabel bevat twee kolommen en is gepartitioneerd op de PRIMAIRE SLEUTEL:
CREATE TABLE dbo.T1
(
T1ID integer IDENTITY (1,1) NOT NULL,
SomeID integer NOT NULL,
CONSTRAINT [PK dbo.T1 T1ID]
PRIMARY KEY CLUSTERED (T1ID)
ON PS (T1ID)
);
De tweede tabel is niet gepartitioneerd. Het bevat een primaire sleutel en een kolom die bij de eerste tabel hoort:
CREATE TABLE dbo.T2
(
T2ID integer IDENTITY (1,1) NOT NULL,
T1ID integer NOT NULL,
CONSTRAINT [PK dbo.T2 T2ID]
PRIMARY KEY CLUSTERED (T2ID)
ON [PRIMARY]
); De voorbeeldgegevens
De eerste tabel heeft 14 rijen, allemaal met dezelfde waarde in de SomeID kolom. SQL Server wijst de IDENTITY . toe kolomwaarden, genummerd van 1 tot 14.
INSERT dbo.T1
(SomeID)
VALUES
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123);
De tweede tabel wordt gewoon gevuld met de IDENTITY waarden uit tabel één:
INSERT dbo.T2 (T1ID) SELECT T1ID FROM dbo.T1;
De gegevens in de twee tabellen zien er als volgt uit:
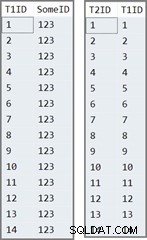
De testquery
De eerste query voegt gewoon beide tabellen samen, waarbij een enkel predikaat van de WHERE-clausule wordt toegepast (wat toevallig overeenkomt met alle rijen in dit sterk vereenvoudigde voorbeeld):
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123; Het resultaat bevat alle 14 rijen, zoals verwacht:

Vanwege het kleine aantal rijen kiest de optimizer een plan voor het samenvoegen van geneste lussen voor deze query:
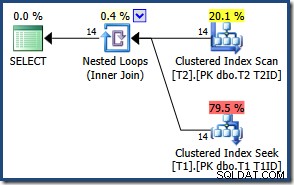
De resultaten zijn hetzelfde (en nog steeds correct) als we een hash- of merge-join forceren:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (HASH JOIN);
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
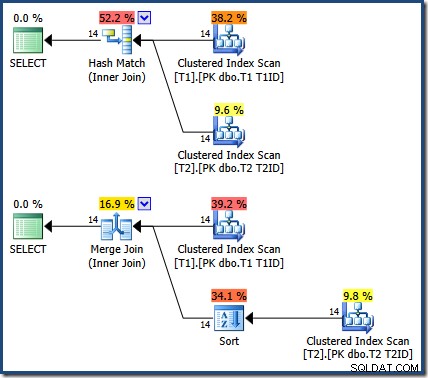
De Merge Join er is één-op-veel, met een expliciete sortering op T1ID vereist voor tabel T2 .
Het aflopende indexprobleem
Alles gaat goed totdat op een dag (om goede redenen die ons hier niet aangaan) een andere beheerder een aflopende index toevoegt aan de SomeID kolom van tabel 1:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC);
Onze query blijft correcte resultaten opleveren wanneer de optimizer een Nested Loops of Hash Join kiest, maar het is een ander verhaal wanneer een Merge Join wordt gebruikt. Het volgende gebruikt nog steeds een query-hint om de samenvoegverbinding af te dwingen, maar dit is slechts een gevolg van het lage aantal rijen in het voorbeeld. De optimizer zou natuurlijk hetzelfde Merge Join-plan kiezen met verschillende tabelgegevens.
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN); Het uitvoeringsplan is:
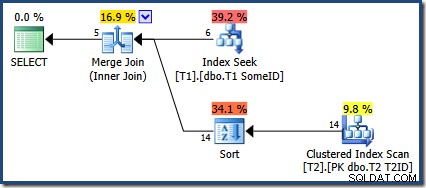
De optimizer heeft ervoor gekozen om de nieuwe index te gebruiken, maar de query produceert nu slechts vijf rijen uitvoer:

Wat is er met de andere 9 rijen gebeurd? Voor alle duidelijkheid:dit resultaat is onjuist. De gegevens zijn niet gewijzigd, dus alle 14 rijen moeten worden geretourneerd (zoals ze nog steeds zijn met een Nested Loops- of Hash Join-abonnement).
Oorzaak en verklaring
De nieuwe niet-geclusterde index op SomeID wordt niet als uniek gedeclareerd, dus de geclusterde indexsleutel wordt stil toegevoegd aan alle niet-geclusterde indexniveaus. SQL Server voegt de T1ID . toe kolom (de geclusterde sleutel) naar de niet-geclusterde index alsof we de index als volgt hebben gemaakt:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID);
Let op het ontbreken van een DESC kwalificatie op de stil toegevoegde T1ID sleutel. Indexsleutels zijn ASC standaard. Dit is op zich geen probleem (hoewel het wel bijdraagt). Het tweede dat automatisch met onze index gebeurt, is dat deze op dezelfde manier is gepartitioneerd als de basistabel. Dus de volledige indexspecificatie, als we het expliciet zouden uitschrijven, zou zijn:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID ASC) ON PS (T1ID);
Dit is nu een behoorlijk complexe structuur, met toetsen in allerlei verschillende volgordes. Het is complex genoeg voor de query-optimizer om het bij het verkeerde eind te hebben bij het redeneren over de sorteervolgorde die door de index wordt geboden. Beschouw ter illustratie de volgende eenvoudige vraag:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;
De extra kolom laat ons alleen zien in welke partitie de huidige rij thuishoort. Anders is het gewoon een simpele zoekopdracht die T1ID retourneert waarden in oplopende volgorde, WHERE SomeID = 123 . Helaas zijn de resultaten niet wat wordt gespecificeerd door de zoekopdracht:
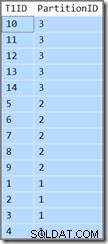
De query vereist dat T1ID waarden moeten in oplopende volgorde worden geretourneerd, maar dat is niet wat we krijgen. We krijgen waarden in oplopende volgorde per partitie , maar de partities zelf worden in omgekeerde volgorde geretourneerd! Als de partities in oplopende volgorde zijn geretourneerd (en de T1ID waarden bleven gesorteerd binnen elke partitie zoals getoond) het resultaat zou correct zijn.
Het queryplan laat zien dat de optimizer in de war was door de leidende DESC sleutel van de index, en dacht dat het nodig was om de partities in omgekeerde volgorde te lezen voor correcte resultaten:
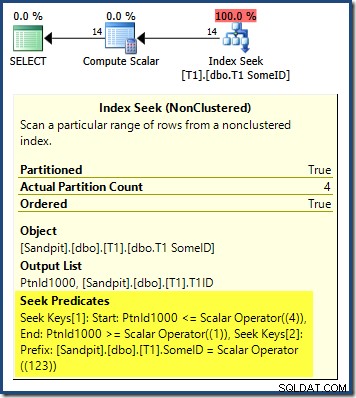
Het zoeken naar partities begint bij de meest rechtse partitie (4) en gaat terug naar partitie 1. Je zou kunnen denken dat we het probleem kunnen oplossen door expliciet te sorteren op partitienummer ASC in de ORDER BY clausule:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
PartitionID ASC, -- New!
T1ID ASC; Deze zoekopdracht geeft dezelfde resultaten (dit is geen drukfout of kopieer-/plakfout):
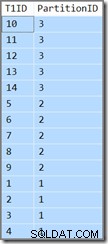
De partitie-ID is nog steeds in aflopend volgorde (niet oplopend, zoals gespecificeerd) en T1ID wordt alleen oplopend gesorteerd binnen elke partitie. Dat is de verwarring van de optimizer, hij denkt echt (haal diep adem nu) dat het scannen van de gepartitioneerde leidende-aflopende-sleutelindex in een voorwaartse richting, maar met omgekeerde partities, zal resulteren in de volgorde gespecificeerd door de query.
Ik neem het het eerlijk gezegd niet kwalijk, de verschillende sorteervolgorde-overwegingen doen ook pijn aan mijn hoofd.
Overweeg als laatste voorbeeld:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID DESC; De resultaten zijn:

Nogmaals, de T1ID sorteervolgorde binnen elke partitie is correct aflopend, maar de partities zelf worden achterstevoren weergegeven (ze gaan van 1 naar 3 in de rijen). Als de partities in omgekeerde volgorde zouden worden geretourneerd, zouden de resultaten correct zijn 14, 13, 12, 11, 10, 9, … 5, 4, 3, 2, 1 .
Terug naar de samenvoeging
De oorzaak van de onjuiste resultaten met de Merge Join-query is nu duidelijk:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
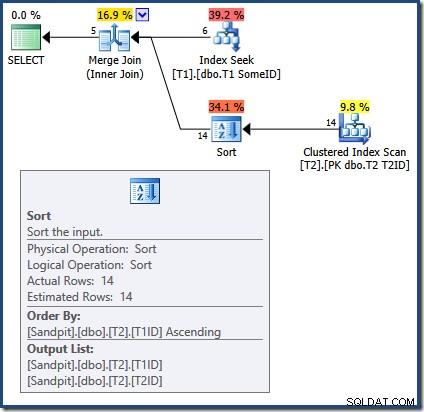
De Merge Join vereist gesorteerde invoer. De invoer van T2 wordt expliciet gesorteerd op T1TD dus dat is oké. De optimizer redeneert ten onrechte dat de index op T1 kan rijen leveren in T1ID volgorde. Zoals we hebben gezien, is dit niet het geval. De Index Seek produceert dezelfde uitvoer als een zoekopdracht die we al hebben gezien:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;

Alleen de eerste 5 rijen staan in T1ID volgorde. De volgende waarde (5) is zeker niet in oplopende volgorde, en de Merge Join interpreteert dit als end-of-stream in plaats van een fout te produceren (persoonlijk verwachtte ik hier een retail-bewering). Hoe dan ook, het effect is dat de Merge Join de verwerking voortijdig ten onrechte beëindigt. Ter herinnering, de (onvolledige) resultaten zijn:

Conclusie
Dit is naar mijn mening een zeer ernstige bug. Een eenvoudige zoekactie naar de index kan resultaten opleveren die niet voldoen aan de ORDER BY clausule. Sterker nog, de interne redenering van de optimizer is volledig verbroken voor gepartitioneerde niet-unieke niet-geclusterde indexen met een aflopende sleutel.
Ja, dit is een enigszins ongebruikelijke regeling. Maar zoals we hebben gezien, kunnen correcte resultaten plotseling worden vervangen door onjuiste resultaten, alleen maar omdat iemand een dalende index heeft toegevoegd. Onthoud dat de toegevoegde index er onschuldig genoeg uitzag:geen expliciete ASC/DESC sleutel komt niet overeen, en geen expliciete partitionering.
De bug is niet beperkt tot Merge Joins. Mogelijk wordt elke query die een gepartitioneerde tabel betreft en die afhankelijk is van de sorteervolgorde van de index (expliciet of impliciet) het slachtoffer. Deze bug bestaat in alle versies van SQL Server van 2008 tot en met 2014 CTP 1. Windows SQL Azure Database ondersteunt geen partitionering, dus het probleem doet zich niet voor. SQL Server 2005 gebruikte een ander implementatiemodel voor partitionering (gebaseerd op APPLY ) en heeft ook geen last van dit probleem.
Als je even de tijd hebt, overweeg dan om op mijn Connect-item te stemmen voor deze bug.
Resolutie
De oplossing voor dit probleem is nu beschikbaar en gedocumenteerd in een Knowledge Base-artikel. Let op:de fix vereist een code-update en traceervlag 4199 , die een reeks andere wijzigingen in de queryprocessor mogelijk maakt. Het is ongebruikelijk dat een fout met onjuiste resultaten wordt opgelost onder 4199. Ik vroeg om opheldering hierover en het antwoord was:
Hoewel dit probleem betrekking heeft op onjuiste resultaten, zoals andere hotfixes met betrekking tot de queryprocessor, hebben we deze correctie alleen ingeschakeld onder traceringsvlag 4199 voor SQL Server 2008, 2008 R2 en 2012. Deze correctie is echter "aan" door standaard zonder de traceringsvlag in SQL Server 2014 RTM.