Parametersniffing
Het parametriseren van query's bevordert het hergebruik van uitvoeringsplannen in de cache, waardoor onnodige compilaties worden vermeden en het aantal ad-hocquery's in de plancache wordt verminderd.
Dit zijn allemaal goede dingen, mits de query die wordt geparametriseerd, zou eigenlijk hetzelfde uitvoeringsplan in de cache moeten gebruiken voor verschillende parameterwaarden. Een uitvoeringsplan dat efficiënt is voor één parameterwaarde mag niet een goede keuze zijn voor andere mogelijke parameterwaarden.
Wanneer het snuiven van parameters is ingeschakeld (de standaard), kiest SQL Server een uitvoeringsplan op basis van de specifieke parameterwaarden die op het moment van compilatie bestaan. De impliciete veronderstelling is dat geparametriseerde instructies meestal worden uitgevoerd met de meest voorkomende parameterwaarden. Dit klinkt redelijk genoeg (zelfs voor de hand liggend) en het werkt inderdaad vaak goed.
Er kan een probleem optreden wanneer een automatische hercompilatie van het in de cache opgeslagen plan plaatsvindt. Een hercompilatie kan om allerlei redenen worden geactiveerd, bijvoorbeeld omdat een index die door het cacheplan wordt gebruikt, is verwijderd (een juistheid hercompilatie) of omdat statistische informatie is gewijzigd (een optimaliteit opnieuw compileren).
Wat de exacte oorzaak ook is van de hercompilatie van het plan, bestaat de kans dat een atypische waarde wordt doorgegeven als parameter op het moment dat het nieuwe plan wordt gegenereerd. Dit kan resulteren in een nieuw cacheplan (gebaseerd op de gesnoven atypische parameterwaarde) dat niet goed is voor de meeste uitvoeringen waarvoor het opnieuw zal worden gebruikt.
Het is niet eenvoudig om te voorspellen wanneer een bepaald uitvoeringsplan opnieuw wordt gecompileerd (bijvoorbeeld omdat de statistieken voldoende zijn gewijzigd), waardoor een situatie ontstaat waarin een herbruikbaar plan van goede kwaliteit plotseling kan worden vervangen door een heel ander plan dat is geoptimaliseerd voor atypische parameterwaarden.
Een dergelijk scenario doet zich voor wanneer de atypische waarde zeer selectief is, wat resulteert in een plan dat is geoptimaliseerd voor een klein aantal rijen. Dergelijke plannen maken vaak gebruik van single-threaded uitvoering, geneste loops joins en lookups. Er kunnen ernstige prestatieproblemen optreden wanneer dit plan wordt hergebruikt voor verschillende parameterwaarden die een veel groter aantal rijen genereren.
Sniffing van parameters uitschakelen
Het snuiven van parameters kan worden uitgeschakeld met behulp van gedocumenteerde traceringsvlag 4136. De traceringsvlag wordt ook ondersteund voor per-query gebruik via de QUERYTRACEON vraag hint. Beide zijn van toepassing vanaf SQL Server 2005 Service Pack 4 (en iets eerder als u cumulatieve updates toepast op Service Pack 3).
Vanaf SQL Server 2016 kan het snuiven van parameters ook worden uitgeschakeld op databaseniveau , met behulp van de PARAMETER_SNIFFING argument voor ALTER DATABASE SCOPED CONFIGURATION .
Als het snuiven van parameters is uitgeschakeld, gebruikt SQL Server gemiddelde distributie statistieken om een uitvoeringsplan te kiezen.
Dit klinkt ook als een redelijke benadering (en kan helpen voorkomen dat het plan wordt geoptimaliseerd voor een ongebruikelijk selectieve parameterwaarde), maar het is ook geen perfecte strategie:een plan dat is geoptimaliseerd voor een 'gemiddelde' waarde serieus suboptimaal voor de vaak voorkomende parameterwaarden.
Overweeg een uitvoeringsplan met geheugenverslindende operators zoals sorteringen en hashes. Omdat geheugen wordt gereserveerd voordat de uitvoering van de query begint, kan een geparametriseerd plan op basis van gemiddelde distributiewaarden overlopen naar tempdb voor veelvoorkomende parameterwaarden die meer gegevens produceren dan de optimizer had verwacht.
Geheugenreserveringen kunnen gewoonlijk niet groeien tijdens het uitvoeren van query's, ongeacht hoeveel vrij geheugen de server heeft. Bepaalde toepassingen hebben er baat bij het snuiven van parameters uit te schakelen (zie dit archiefbericht van het Dynamics AX Performance Team voor een voorbeeld).
Voor de meeste workloads is het volledig uitschakelen van het snuiven van parameters de verkeerde oplossing , en kan zelfs een ramp zijn. Het snuiven van parameters is een heuristische optimalisatie:het werkt meestal beter dan het gebruik van gemiddelde waarden op de meeste systemen.
Query-tips
SQL Server biedt een reeks query-hints en andere opties om het gedrag van het snuiven van parameters af te stemmen:
- De
OPTIMIZE FOR (@parameter = value)query hint bouwt een herbruikbaar plan op basis van een specifieke waarde. OPTIMIZE FOR (@parameter UNKNOWN)gebruikt gemiddelde distributiestatistieken voor een bepaalde parameter.OPTIMIZE FOR UNKNOWNgebruikt gemiddelde verdeling voor alle parameters (zelfde effect als traceringsvlag 4136).- De
WITH RECOMPILEopgeslagen procedure-optie stelt een nieuw procedureplan samen voor elke uitvoering. - De
OPTION (RECOMPILE)vraaghint stelt een nieuw plan samen voor een individuele instructie.
De oude techniek van “parameter verbergen” (procedureparameters toewijzen aan lokale variabelen en in plaats daarvan verwijzen naar de variabelen) heeft hetzelfde effect als het specificeren van OPTIMIZE FOR UNKNOWN . Het kan handig zijn op eerdere instanties dan SQL Server 2008 (de OPTIMIZE FOR hint was nieuw voor 2008).
Men zou kunnen stellen dat elke De geparametriseerde instructie moet worden gecontroleerd op gevoeligheid voor parameterwaarden, en ofwel met rust gelaten worden (als het standaardgedrag goed werkt) of expliciet laten doorschemeren met een van de bovenstaande opties.
Dit wordt in de praktijk zelden gedaan, deels omdat het uitvoeren van een uitgebreide analyse voor alle mogelijke parameterwaarden tijdrovend kan zijn en behoorlijk geavanceerde vaardigheden vereist.
Meestal wordt een dergelijke analyse niet uitgevoerd en worden parametergevoeligheidsproblemen aangepakt als en wanneer ze in productie voorkomen.
Dit gebrek aan voorafgaande analyse is waarschijnlijk een van de belangrijkste redenen waarom het snuiven van parameters een slechte reputatie heeft. Het loont de moeite om je bewust te zijn van de mogelijkheid dat er problemen optreden en om op zijn minst een snelle analyse uit te voeren van uitspraken die waarschijnlijk prestatieproblemen zullen veroorzaken wanneer ze opnieuw worden gecompileerd met een atypische parameterwaarde.
Wat is een parameter?
Sommigen zouden zeggen dat een SELECT instructie die verwijst naar een lokale variabele is een “geparametriseerde instructie” van soorten, maar dat is niet de definitie die SQL Server gebruikt.
Een redelijke indicatie dat een opgave parameters gebruikt kan gevonden worden door te kijken naar de eigenschappen van het plan (zie de Parameters tabblad in Sentry One Plan Explorer. Of klik op het hoofdknooppunt van het queryplan in SSMS, open de Eigenschappen venster en vouw de Parameterlijst uit knooppunt):
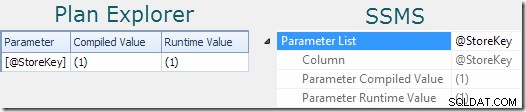
De 'gecompileerde waarde' toont de gesnoven waarde van de parameter die is gebruikt om het gecachte plan te compileren. De 'runtime-waarde' toont de waarde van de parameter voor de specifieke uitvoering die in het plan is vastgelegd.
Een van deze eigenschappen kan in verschillende omstandigheden leeg zijn of ontbreken. Als een zoekopdracht niet is geparametriseerd, zullen de eigenschappen gewoon allemaal ontbreken.
Gewoon omdat niets ooit eenvoudig is in SQL Server, zijn er situaties waarin de parameterlijst kan worden ingevuld, maar de instructie is nog steeds niet geparametriseerd. Dit kan gebeuren wanneer SQL Server eenvoudige parametrering probeert (later besproken) maar besluit dat de poging "onveilig" is. In dat geval zullen parametermarkeringen aanwezig zijn, maar het uitvoeringsplan is in feite niet geparametriseerd.
Snuiven is niet alleen voor opgeslagen procedures
Het snuiven van parameters vindt ook plaats wanneer een batch expliciet is geparametriseerd voor hergebruik met behulp van sp_executesql .
Bijvoorbeeld:
EXECUTE sys.sp_executesql
N'
SELECT
P.ProductID,
P.Name,
TotalQty = SUM(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
WHERE
P.Name LIKE @NameLike
GROUP BY
P.ProductID,
P.Name;
',
N'@NameLike nvarchar(50)',
@NameLike = N'K%';
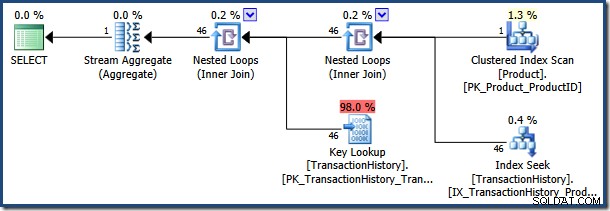
De optimizer kiest een uitvoeringsplan op basis van de gesnoven waarde van de @NameLike parameter. De parameterwaarde "K%" komt naar schatting overeen met zeer weinig rijen in het Product tabel, dus de optimizer kiest een geneste loop join en key lookup-strategie:

Door de instructie opnieuw uit te voeren met een parameterwaarde van "[H-R]%" (die overeenkomt met veel meer rijen) wordt het geparametreerde plan in de cache opnieuw gebruikt:
EXECUTE sys.sp_executesql
N'
SELECT
P.ProductID,
P.Name,
TotalQty = SUM(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
WHERE
P.Name LIKE @NameLike
GROUP BY
P.ProductID,
P.Name;
',
N'@NameLike nvarchar(50)',
@NameLike = N'[H-R]%';
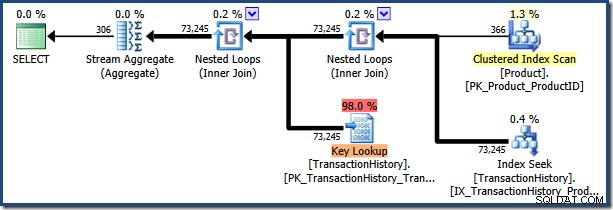

De AdventureWorks voorbeelddatabase is te klein om dit een prestatieramp te maken, maar dit plan is zeker niet optimaal voor de tweede parameterwaarde.
We kunnen het plan zien dat de optimizer zou hebben gekozen door de plancache te wissen en de tweede query opnieuw uit te voeren:
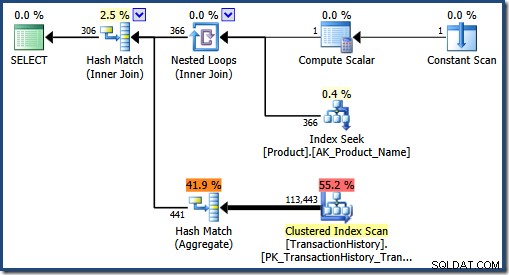

Met een groter aantal verwachte overeenkomsten, bepaalt de optimizer dat een hash-join en hash-aggregatie betere strategieën zijn.
T-SQL-functies
Het snuiven van parameters vindt ook plaats met T-SQL-functies, hoewel de manier waarop uitvoeringsplannen worden gegenereerd dit moeilijker kan maken om te zien.
Er zijn goede redenen om T-SQL scalaire en multi-statement functies in het algemeen te vermijden, dus alleen voor educatieve doeleinden is hier een T-SQL multi-statement table-valued functieversie van onze testquery:
CREATE FUNCTION dbo.F
(@NameLike nvarchar(50))
RETURNS @Result TABLE
(
ProductID integer NOT NULL PRIMARY KEY,
Name nvarchar(50) NOT NULL,
TotalQty integer NOT NULL
)
WITH SCHEMABINDING
AS
BEGIN
INSERT @Result
SELECT
P.ProductID,
P.Name,
TotalQty = SUM(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
WHERE
P.Name LIKE @NameLike
GROUP BY
P.ProductID,
P.Name;
RETURN;
END; De volgende query gebruikt de functie om informatie weer te geven voor productnamen die beginnen met 'K':
SELECT
Result.ProductID,
Result.Name,
Result.TotalQty
FROM dbo.F(N'K%') AS Result; Het is moeilijker om parameters te zien snuiven met een ingesloten functie omdat SQL Server geen afzonderlijk (werkelijk) queryplan na de uitvoering retourneert voor elke functieaanroep. De functie kan binnen een enkele instructie vele malen worden aangeroepen en gebruikers zouden niet onder de indruk zijn als SSMS zou proberen een miljoen functieaanroepplannen voor een enkele query weer te geven.
Als gevolg van deze ontwerpbeslissing is het daadwerkelijke plan dat door SQL Server wordt geretourneerd voor onze testquery niet erg nuttig:
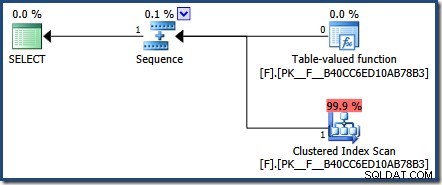
Toch zijn er zijn manieren om parametersniffing in actie te zien met ingebedde functies. De methode die ik hier heb gekozen, is om de plancache te inspecteren:
SELECT
DEQS.plan_generation_num,
DEQS.execution_count,
DEQS.last_logical_reads,
DEQS.last_elapsed_time,
DEQS.last_rows,
DEQP.query_plan
FROM sys.dm_exec_query_stats AS DEQS
CROSS APPLY sys.dm_exec_sql_text(DEQS.plan_handle) AS DEST
CROSS APPLY sys.dm_exec_query_plan(DEQS.plan_handle) AS DEQP
WHERE
DEST.objectid = OBJECT_ID(N'dbo.F', N'TF');
Dit resultaat laat zien dat het functieplan eenmaal is uitgevoerd, tegen een kostprijs van 201 logische uitlezingen met een verstreken tijd van 2891 microseconden, en de meest recente uitvoering heeft één rij geretourneerd. De geretourneerde XML-planweergave laat zien dat de parameterwaarde was gesnoven:
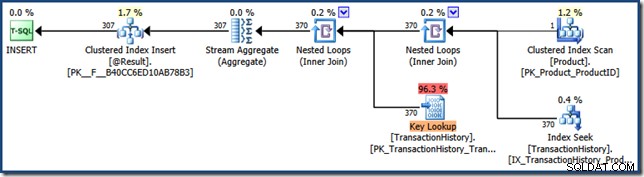

Voer de instructie nu opnieuw uit, met een andere parameter:
SELECT
Result.ProductID,
Result.Name,
Result.TotalQty
FROM dbo.F(N'[H-R]%') AS Result; Het post-uitvoeringsplan laat zien dat 306 rijen zijn geretourneerd door de functie:
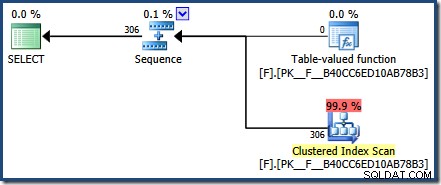
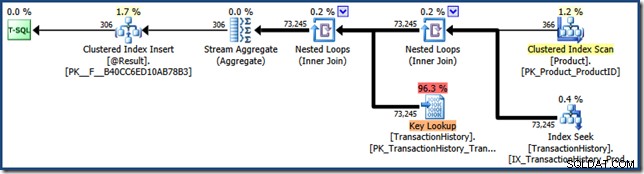
De plancachequery geeft aan dat het uitvoeringsplan in de cache voor de functie opnieuw is gebruikt (execution_count =2):

Het toont ook een veel hoger aantal logische uitlezingen en een langere verstreken tijd in vergelijking met de vorige run. Dit komt overeen met het hergebruiken van een geneste lus en een opzoekplan, maar om helemaal zeker te zijn, kan het functieplan na de uitvoering worden vastgelegd met Extended Events of de SQL Server Profiler hulpmiddel:

Omdat het snuiven van parameters van toepassing is op functies, kunnen deze modules last hebben van dezelfde onverwachte prestatieveranderingen die gewoonlijk worden geassocieerd met opgeslagen procedures.
De eerste keer dat naar een functie wordt verwezen, kan bijvoorbeeld een plan in de cache worden opgeslagen dat geen parallellisme gebruikt. Daaropvolgende uitvoeringen met parameterwaarden die baat zouden hebben bij parallellisme (maar het seriële plan in de cache hergebruiken) zullen onverwacht slechte prestaties vertonen.
Dit probleem kan lastig te identificeren zijn, omdat SQL Server geen afzonderlijke plannen na de uitvoering retourneert voor functieaanroepen, zoals we hebben gezien. Uitgebreide evenementen gebruiken of Profiler het routinematig vastleggen van plannen na de uitvoering kan zeer arbeidsintensief zijn, dus is het vaak zinvol om die techniek op een zeer gerichte manier te gebruiken. De problemen bij het debuggen van functieparametergevoeligheidsproblemen betekenen dat het nog meer de moeite waard is om een analyse uit te voeren (en defensief te coderen) voordat de functie in productie gaat.
Het snuiven van parameters werkt op precies dezelfde manier met door de gebruiker gedefinieerde T-SQL scalaire functies (tenzij inline, vanaf SQL Server 2019). In-line functies met tabelwaarde genereren geen afzonderlijk uitvoeringsplan voor elke aanroep, omdat (zoals de naam al zegt) deze inline zijn opgenomen in de aanroepende query vóór compilatie.
Pas op voor gesnoven NULL's
Wis de plancache en vraag een geschatte . aan (pre-uitvoerings)plan voor de testquery:
SELECT
Result.ProductID,
Result.Name,
Result.TotalQty
FROM dbo.F(N'K%') AS Result; U ziet twee uitvoeringsplannen, waarvan de tweede voor de functieaanroep is:
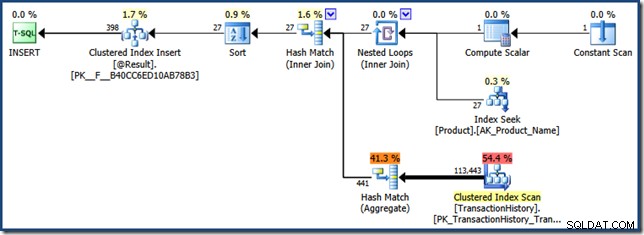
Een beperking van het snuiven van parameters met ingebedde functies in geschatte plannen betekent dat de parameterwaarde wordt gesnoven als NULL (niet “K%”):

In versies van SQL Server vóór 2012, dit plan (geoptimaliseerd voor een NULL parameter) is gecached voor hergebruik . Dit is jammer, want NULL Het is onwaarschijnlijk dat dit een representatieve parameterwaarde is, en het was zeker niet de waarde die in de zoekopdracht werd gespecificeerd.
SQL Server 2012 (en later) slaat geen plannen op die het gevolg zijn van een "geschat plan" -verzoek, hoewel het nog steeds een functieplan weergeeft dat is geoptimaliseerd voor een NULL parameterwaarde tijdens compilatie.
Eenvoudige en geforceerde parametrering
Een ad-hoc T-SQL-instructie die constante letterlijke waarden bevat, kan worden geparametriseerd door SQL Server, hetzij omdat de query in aanmerking komt voor eenvoudige parametrering of omdat de database-optie voor geforceerde parametrering is ingeschakeld (of omdat een plangids voor hetzelfde effect wordt gebruikt).
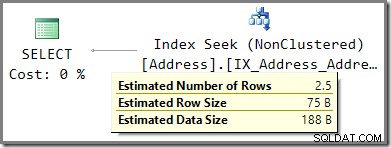
Een op deze manier geparametreerd statement is ook onderhevig aan parameter sniffing. De volgende query komt in aanmerking voor eenvoudige parametrering:
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
A.AddressLine1 = N'Heidestieg Straße 8664'; Het geschatte uitvoeringsplan toont een schatting van 2,5 rijen op basis van de gesnuffelde parameterwaarde:
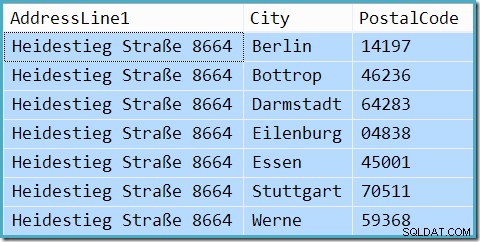
In feite retourneert de query 7 rijen (schatting van de kardinaliteit is niet perfect, zelfs niet wanneer waarden worden gesnoven):
Op dit punt vraag je je misschien af waar het bewijs is dat deze query is geparametriseerd en dat de resulterende parameterwaarde is gesnoven. Voer de query een tweede keer uit met een andere waarde:
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
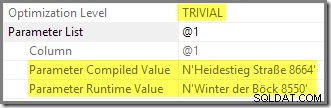
A.AddressLine1 = N'Winter der Böck 8550'; De zoekopdracht retourneert één rij:

Het uitvoeringsplan laat zien dat de tweede uitvoering het geparametriseerde plan heeft hergebruikt dat is samengesteld met behulp van een gesnuffelde waarde:
Parameterisatie en snuiven zijn afzonderlijke activiteiten
Een ad-hoc statement kan worden geparametriseerd door SQL Server zonder parameterwaarden die worden gesnoven.
Om te demonstreren kunnen we traceringsvlag 4136 gebruiken om het snuiven van parameters uit te schakelen voor een batch die door de server wordt geparametriseerd:
DBCC FREEPROCCACHE;
DBCC TRACEON (4136);
GO
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
A.AddressLine1 = N'Heidestieg Straße 8664';
GO
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
A.AddressLine1 = N'Winter der Böck 8550';
GO
DBCC TRACEOFF (4136); Het script resulteert in instructies die zijn geparametriseerd, maar de parameterwaarde wordt niet gesnuffeld voor kardinaliteitsschattingen. Om dit te zien, kunnen we de plancache inspecteren:
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
DECP.cacheobjtype,
DECP.objtype,
DECP.usecounts,
DECP.plan_handle,
parameterized_plan_handle =
DEQP.query_plan.value
(
'(//StmtSimple)[1]/@ParameterizedPlanHandle',
'NVARCHAR(100)'
)
FROM sys.dm_exec_cached_plans AS DECP
CROSS APPLY sys.dm_exec_sql_text(DECP.plan_handle) AS DEST
CROSS APPLY sys.dm_exec_query_plan(DECP.plan_handle) AS DEQP
WHERE
DEST.[text] LIKE N'%AddressLine1%'
AND DEST.[text] NOT LIKE N'%XMLNAMESPACES%'; De resultaten tonen twee cache-items voor de ad-hocquery's, gekoppeld aan het geparametriseerde (voorbereide) queryplan door de geparametriseerde planhandle.
Het geparametriseerde plan wordt twee keer gebruikt:

Het uitvoeringsplan toont een andere schatting van de kardinaliteit nu het snuiven van parameters is uitgeschakeld:
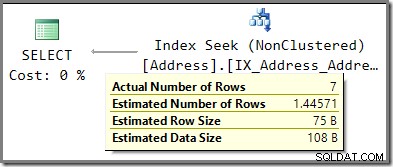
Vergelijk de schatting van 1.44571 rijen met de schatting van 2,5 rijen die werd gebruikt toen parametersniffen was ingeschakeld.
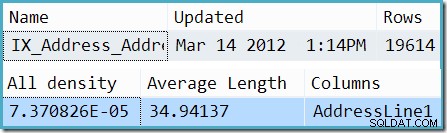
Als snuiven is uitgeschakeld, is de schatting afkomstig van informatie over de gemiddelde frequentie over de AddressLine1 kolom. Een uittreksel van de DBCC SHOW_STATISTICS output voor de index in kwestie laat zien hoe dit aantal werd berekend:vermenigvuldiging van het aantal rijen in de tabel (19.614) met de dichtheid (7.370826e-5) geeft de 1.44571 rijschatting.
Kanttekening: Er wordt algemeen aangenomen dat alleen vergelijkingen met gehele getallen die een unieke index gebruiken, in aanmerking kunnen komen voor eenvoudige parametrering. Ik heb bewust dit voorbeeld gekozen (een stringvergelijking met een niet-unieke index) om dat te weerleggen.
MET RECOMPILE en OPTIE (RECOMPILE)
Wanneer zich een parametergevoeligheidsprobleem voordoet, is een algemeen advies op forums en Q&A-sites om "hercompileren te gebruiken" (ervan uitgaande dat de andere eerder gepresenteerde afstemmingsopties niet geschikt zijn). Helaas wordt dat advies vaak verkeerd geïnterpreteerd als het toevoegen van WITH RECOMPILE optie naar de opgeslagen procedure.
WITH RECOMPILE gebruiken brengt ons effectief terug naar het gedrag van SQL Server 2000, waar de volledige opgeslagen procedure wordt bij elke uitvoering opnieuw gecompileerd.
Een beter alternatief , op SQL Server 2005 en later, is het gebruik van de OPTION (RECOMPILE) vraag hint op alleen de instructie die lijdt aan het parameter-snuiven probleem. Deze vraaghint resulteert in een hercompilatie van de problematische instructie enkel en alleen. Uitvoeringsplannen voor andere instructies binnen de opgeslagen procedure worden in de cache opgeslagen en normaal opnieuw gebruikt.
WITH RECOMPILE gebruiken betekent ook dat het gecompileerde plan voor de opgeslagen procedure niet in de cache wordt opgeslagen. Als gevolg hiervan wordt er geen prestatie-informatie bijgehouden in DMV's zoals sys.dm_exec_query_stats .
Als u in plaats daarvan de queryhint gebruikt, betekent dit dat een gecompileerd plan in de cache kan worden opgeslagen en dat prestatie-informatie beschikbaar is in de DMV's (hoewel deze beperkt is tot de meest recente uitvoering, alleen voor de betreffende instructie).
Voor instanties met ten minste SQL Server 2008 build 2746 (Service Pack 1 met cumulatieve update 5), met behulp van OPTION (RECOMPILE) heeft nog een aanzienlijk voordeel over WITH RECOMPILE :Alleen OPTION (RECOMPILE) activeert de Parameter Embedding Optimization .
De optimalisatie van het inbedden van parameters
Door parameterwaarden te snuiven, kan de optimizer de parameterwaarde gebruiken om kardinaliteitsschattingen af te leiden. Beide WITH RECOMPILE en OPTION (RECOMPILE) resulteren in queryplannen met schattingen berekend op basis van de werkelijke parameterwaarden bij elke uitvoering.
De Parameter Embedding Optimization gaat een stap verder in dit proces. Queryparameters zijn vervangen met letterlijke constante waarden tijdens het parseren van query's.
De parser is in staat tot verrassend complexe vereenvoudigingen, en daaropvolgende query-optimalisatie kan de zaken nog verder verfijnen. Overweeg de volgende opgeslagen procedure, die de WITH RECOMPILE . bevat optie:
CREATE PROCEDURE dbo.P
@NameLike nvarchar(50),
@Sort tinyint
WITH RECOMPILE
AS
BEGIN
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
@NameLike IS NULL
OR Name LIKE @NameLike
ORDER BY
CASE WHEN @Sort = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN @Sort = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN @Sort = 3 THEN Name ELSE NULL END ASC,
CASE WHEN @Sort = 4 THEN Name ELSE NULL END DESC;
END; De procedure wordt twee keer uitgevoerd, met de volgende parameterwaarden:
EXECUTE dbo.P @NameLike = N'K%', @Sort = 1; GO EXECUTE dbo.P @NameLike = N'[H-R]%', @Sort = 4;
Omdat WITH RECOMPILE wordt gebruikt, wordt de procedure bij elke uitvoering volledig opnieuw gecompileerd. De parameterwaarden zijn gesnoven elke keer, en gebruikt door de optimizer om kardinaliteitsschattingen te berekenen.
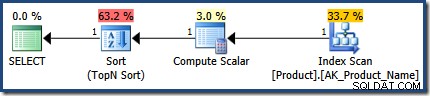
Het plan voor de eerste procedure-uitvoering is precies correct, met een schatting van 1 rij:
De tweede uitvoering schat 360 rijen, zeer dicht bij de 366 die tijdens runtime worden gezien:
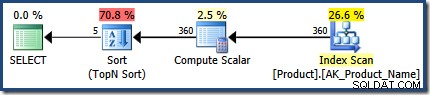
Beide plannen gebruiken dezelfde algemene uitvoeringsstrategie:scan alle rijen in een index, met de WHERE clausule predikaat als een residu; bereken de CASE uitdrukking gebruikt in de ORDER BY clausule; en voer een Top N Sort uit op het resultaat van de CASE uitdrukking.
OPTIE (HERCOMPILEREN)
Maak nu de opgeslagen procedure opnieuw met behulp van een OPTION (RECOMPILE) vraaghint in plaats van WITH RECOMPILE :
CREATE PROCEDURE dbo.P
@NameLike nvarchar(50),
@Sort tinyint
AS
BEGIN
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
@NameLike IS NULL
OR Name LIKE @NameLike
ORDER BY
CASE WHEN @Sort = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN @Sort = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN @Sort = 3 THEN Name ELSE NULL END ASC,
CASE WHEN @Sort = 4 THEN Name ELSE NULL END DESC
OPTION (RECOMPILE);
END; Het tweemaal uitvoeren van de opgeslagen procedure met dezelfde parameterwaarden als voorheen levert dramatisch verschillende op uitvoeringsplannen.
Dit is het eerste uitvoeringsplan (met parameters die om namen vragen die beginnen met "K", geordend op ProductID oplopend):
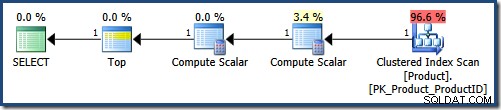
De parser ingesloten de parameterwaarden in de vraagtekst, resulterend in de volgende tussenvorm:
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
'K%' IS NULL
OR Name LIKE 'K%'
ORDER BY
CASE WHEN 1 = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN 1 = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN 1 = 3 THEN Name ELSE NULL END ASC,
CASE WHEN 1 = 4 THEN Name ELSE NULL END DESC;
De parser gaat dan verder, verwijdert tegenstrijdigheden en evalueert de CASE volledig uitdrukkingen. Dit resulteert in:
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
Name LIKE 'K%'
ORDER BY
ProductID ASC,
NULL DESC,
NULL ASC,
NULL DESC; U krijgt een foutmelding als u die query rechtstreeks naar SQL Server probeert te verzenden, omdat bestellen op een constante waarde niet is toegestaan. Niettemin is dit de vorm die door de parser wordt geproduceerd. Het is intern toegestaan omdat het is ontstaan als gevolg van het toepassen van de parameter embedding optimalisatie . De vereenvoudigde query maakt het leven van de query-optimizer een stuk eenvoudiger:
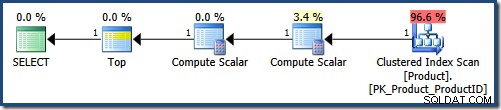
De geclusterde indexscan past de LIKE . toe predikaat als een residu. De Compute Scalar levert de constante NULL waarden. De Top geeft de eerste 5 rijen terug in de volgorde die wordt gegeven door de geclusterde index (een soort vermijden). In een perfecte wereld zou de query-optimizer ook de Compute Scalar . verwijderen die de NULLs definieert , omdat ze niet worden gebruikt tijdens het uitvoeren van query's.
De tweede uitvoering volgt exact hetzelfde proces, wat resulteert in een queryplan (voor namen die beginnen met de letters "H" tot "R", gerangschikt op Name aflopend) als volgt:

Dit plan heeft een Niet-geclusterde Index Zoeken die betrekking heeft op de LIKE bereik, een resterende LIKE predikaat, de constante NULLs zoals voorheen, en een Top (5). De query-optimizer kiest voor het uitvoeren van een BACKWARD bereikscan in de Index Seek om opnieuw sorteren te vermijden.
Vergelijk het bovenstaande plan met het plan dat is gemaakt met WITH RECOMPILE , die geen gebruik kan maken van de optimalisatie voor inbedding van parameters :
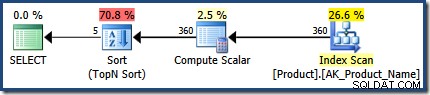
Dit demo-voorbeeld was misschien beter geïmplementeerd als een reeks van IF instructies in de procedure (één voor elke combinatie van parameterwaarden). Dit zou vergelijkbare voordelen voor het queryplan kunnen bieden, zonder dat er elke keer een compilatie van een instructie moet worden gemaakt. In meer complexe scenario's, hercompileren op instructieniveau met inbedding van parameters geleverd door OPTION (RECOMPILE) kan een uiterst nuttige optimalisatietechniek zijn.
Een insluitingsbeperking
Er is één scenario waarbij OPTION (RECOMPILE) zal er niet toe leiden dat de optimalisatie van de inbedding van parameters wordt toegepast. Als de instructie wordt toegewezen aan een variabele, worden parameterwaarden niet ingesloten:
CREATE PROCEDURE dbo.P
@NameLike nvarchar(50),
@Sort tinyint
AS
BEGIN
DECLARE
@ProductID integer,
@Name nvarchar(50);
SELECT TOP (1)
@ProductID = ProductID,
@Name = Name
FROM Production.Product
WHERE
@NameLike IS NULL
OR Name LIKE @NameLike
ORDER BY
CASE WHEN @Sort = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN @Sort = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN @Sort = 3 THEN Name ELSE NULL END ASC,
CASE WHEN @Sort = 4 THEN Name ELSE NULL END DESC
OPTION (RECOMPILE);
END;
Omdat de SELECT statement nu toewijst aan een variabele, zijn de geproduceerde queryplannen hetzelfde als wanneer WITH RECOMPILE was gebruikt. Parameterwaarden worden nog steeds gesnuffeld en gebruikt door de query-optimizer voor kardinaliteitsschatting en OPTION (RECOMPILE) compileert nog steeds alleen de enkele instructie, alleen het voordeel van inbedding van parameters is verloren.