[ Deel 1 | Deel 2 | Deel 3 ]
In deel 1 van deze serie heb ik een paar manieren uitgeprobeerd om een 1TB-tafel te comprimeren. Hoewel ik bij mijn eerste poging behoorlijke resultaten behaalde, wilde ik zien of ik de prestaties in deel 2 kon verbeteren. Daar schetste ik een paar van de dingen waarvan ik dacht dat het prestatieproblemen waren, en legde uit hoe ik de bestemmingstabel beter kon partitioneren. voor optimale columnstore-compressie. Ik heb al:
- de tabel gepartitioneerd in 8 partities (één per core);
- zet het gegevensbestand van elke partitie op zijn eigen bestandsgroep; en,
- zet archiefcompressie op alles behalve de "actieve" partitie.
Ik moet het nog steeds zo maken dat elke planner exclusief naar zijn eigen partitie schrijft.
Eerst moet ik wijzigingen aanbrengen in de batchtabel die ik heb gemaakt. Ik heb een kolom nodig om het aantal toegevoegde rijen per batch op te slaan (een soort zelfcontrolerende sanity check), en begin- en eindtijden om de voortgang te meten.
ALTER TABLE dbo.BatchQueue ADD RowsAdded int, StartTime datetime2, EndTime datetime2;
Vervolgens moet ik een tabel maken om affiniteit te bieden - we willen nooit meer dan één proces dat op een planner draait, zelfs als dit betekent dat je wat tijd verliest om logica opnieuw te proberen. We hebben dus een tabel nodig die elke sessie op een specifieke planner bijhoudt en stapelen voorkomt:
CREATE TABLE dbo.OpAffinity ( SchedulerID int NOT NULL, SessionID int NULL, CONSTRAINT PK_OpAffinity PRIMARY KEY CLUSTERED (SchedulerID) );
Het idee is dat ik acht exemplaren van een toepassing (SQLQueryStress) zou hebben die elk op een speciale planner zouden draaien, waarbij alleen de gegevens zouden worden verwerkt die bestemd zijn voor een specifieke partitie / bestandsgroep / gegevensbestand, ~ 100 miljoen rijen tegelijk (klik om te vergroten) :
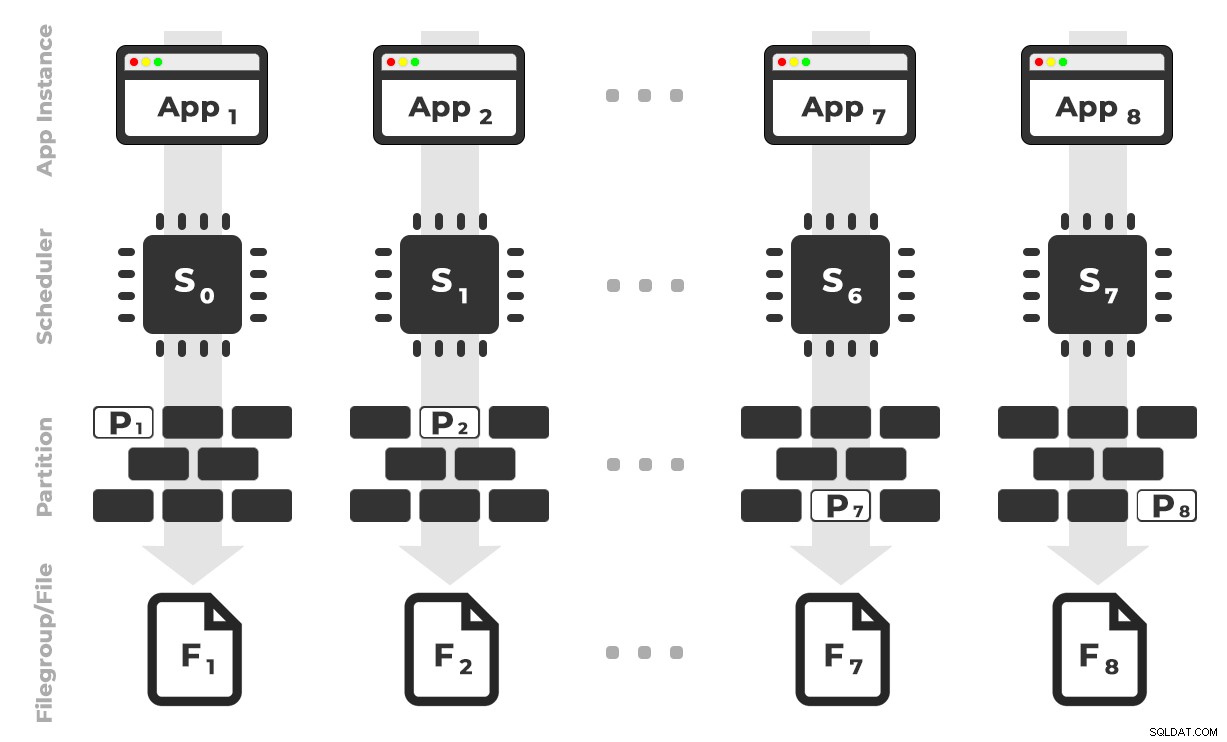 App 1 krijgt planner 0 en schrijft naar partitie 1 in bestandsgroep 1, enzovoort …
App 1 krijgt planner 0 en schrijft naar partitie 1 in bestandsgroep 1, enzovoort …
Vervolgens hebben we een opgeslagen procedure nodig waarmee elk exemplaar van de toepassing tijd kan reserveren voor een enkele planner. Zoals ik in een vorige post al zei, is dit niet mijn oorspronkelijke idee (en ik zou het nooit in die gids hebben gevonden als Joe Obbish er niet was). Hier is de procedure die ik heb gemaakt in Utility :
CREATE PROCEDURE dbo.DoMyBatch
@PartitionID int, -- pass in 1 through 8
@BatchID int -- pass in 1 through 4
AS
BEGIN
DECLARE @BatchSize bigint,
@MinID bigint,
@MaxID bigint,
@rc bigint,
@ThisSchedulerID int =
(
SELECT scheduler_id
FROM sys.dm_exec_requests
WHERE session_id = @@SPID
);
-- try to get the requested scheduler, 0-based
IF @ThisSchedulerID <> @PartitionID - 1
BEGIN
-- surface the scheduler we got to the application, but force a delay
RAISERROR('Got wrong scheduler %d.', 11, 1, @ThisSchedulerID);
WAITFOR DELAY '00:00:05';
RETURN -3;
END
ELSE
BEGIN
-- we are on our scheduler, now serializibly make sure we're exclusive
INSERT Utility.dbo.OpAffinity(SchedulerID, SessionID)
SELECT @ThisSchedulerID, @@SPID
WHERE NOT EXISTS
(
SELECT 1 FROM Utility.dbo.OpAffinity WITH (TABLOCKX)
WHERE SchedulerID = @ThisSchedulerID
);
-- if someone is already using this scheduler, raise roar:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Wrong scheduler %d, try again.',11,1,@ThisSchedulerID) WITH NOWAIT;
RETURN @ThisSchedulerID;
END
-- checkpoint twice to clear log
EXEC OCopy.sys.sp_executesql N'CHECKPOINT; CHECKPOINT;';
-- get our range of rows for the current batch
SELECT @MinID = MinID, @MaxID = MaxID
FROM Utility.dbo.BatchQueue
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID
AND StartTime IS NULL;
-- if we couldn't get a row here, must already be done:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Already done.', 11, 1) WITH NOWAIT;
RETURN -1;
END
-- update the BatchQueue table to indicate we've started:
UPDATE msdb.dbo.BatchQueue
SET StartTime = sysdatetime(), EndTime = NULL
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- do the work - copy from Original to Partitioned
INSERT OCopy.dbo.tblPartitionedCCI
SELECT * FROM OCopy.dbo.tblOriginal AS o
WHERE o.CostID >= @MinID AND o.CostID <= @MaxID
OPTION (MAXDOP 1); -- don't want parallelism here!
/*
You might think, don't I want a TABLOCK hint on the insert,
to benefit from minimal logging? I thought so too, but while
this leads to a BULK UPDATE lock on rowstore tables, it is a
TABLOCKX with columnstore. This isn't going to work well if
we want to have multiple processes inserting into separate
partitions simultaneously. We need a PARTITIONLOCK hint!
*/
SET @rc = @@ROWCOUNT;
-- update BatchQueue that we've finished and how many rows:
UPDATE Utility.dbo.BatchQueue
SET EndTime = sysdatetime(), RowsAdded = @rc
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- remove our lock to this scheduler:
DELETE Utility.dbo.OpAffinity
WHERE SchedulerID = @ThisSchedulerID
AND SessionID = @@SPID;
END
END Simpel, toch? Start 8 exemplaren van SQLQueryStress en plaats deze batch in elk ervan:
EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 1; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 2; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 3; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 4;
 Het parallellisme van de arme man
Het parallellisme van de arme man
Alleen is het niet zo eenvoudig, aangezien de toewijzing van een planner een soort doos chocolaatjes is. Het kostte veel pogingen om elk exemplaar van de app op de verwachte planner te krijgen; Ik zou de uitzonderingen op een bepaald exemplaar van de app inspecteren en de PartitionID . wijzigen overeenkomen. Dit is de reden waarom ik meer dan één iteratie heb gebruikt (maar ik wilde nog steeds maar één thread per instantie). Dit exemplaar van de app verwachtte bijvoorbeeld dat het op Scheduler 3 zou staan, maar het kreeg Scheduler 4:
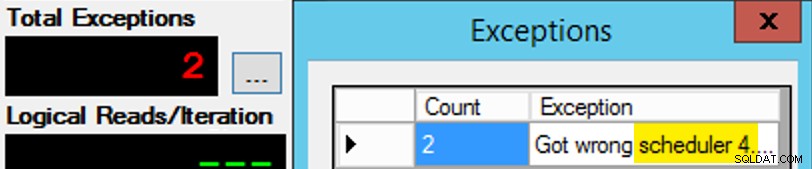 Als het je in eerste instantie niet lukt...
Als het je in eerste instantie niet lukt...
Ik veranderde de 3s in het queryvenster in 4s en probeerde het opnieuw. Als ik snel was, was de taak van de planner "plakkerig" genoeg om het meteen op te pikken en weg te tuffen. Maar ik was niet altijd snel genoeg, dus het was een beetje als een mep om op gang te komen. Ik had waarschijnlijk een betere routine voor opnieuw proberen/loopen kunnen bedenken om het werk hier minder handmatig te maken, en de vertraging verkorten, zodat ik meteen wist of het werkte of niet, maar dit was goed genoeg voor mijn behoeften. Het zorgde ook voor een onbedoelde spreiding van de starttijden voor elk proces, nog een advies van meneer Obbish.
Bewaking
Terwijl de geaffinitiseerde kopie wordt uitgevoerd, kan ik een hint krijgen over de huidige status met de volgende twee vragen:
SELECT r.session_id, r.[status], r.scheduler_id, partition_id = o.SchedulerID + 1,
r.logical_reads, r.total_elapsed_time, r.last_wait_type, longest_wait_type =
(
SELECT TOP (1) wait_type
FROM sys.dm_exec_session_wait_stats
WHERE session_id = r.session_id AND wait_type <> 'WAITFOR'
ORDER BY wait_time_ms - signal_wait_time_ms DESC
)
FROM sys.dm_exec_requests AS r
INNER JOIN Utility.dbo.OpAffinity AS o
ON o.SessionID = r.session_id
WHERE r.command = N'INSERT'
ORDER BY r.scheduler_id;
SELECT SchedulerID = PartitionID - 1, Duration = DATEDIFF(SECOND, StartTime, EndTime), *
FROM Utility.dbo.BatchQueue WITH (NOLOCK)
WHERE StartTime IS NOT NULL -- AND EndTime IS NULL
ORDER BY PartitionID;
Als ik alles goed deed, zouden beide query's 8 rijen retourneren en toenemende logische waarden en duur weergeven. Wachttypes zullen ronddraaien tussen PAGEIOLATCH_SH , SOS_SCHEDULER_YIELD , en af en toe RESERVED_MEMORY_ALLOCATION_EXT. Wanneer een batch klaar was (ik kon deze bekijken door -- AND EndTime IS NULL te verwijderen , zou ik bevestigen dat RowsAdded = RowsInRange .
Nadat alle 8 instanties van SQLQueryStress waren voltooid, kon ik gewoon een SELECT INTO <newtable> FROM dbo.BatchQueue uitvoeren om de definitieve resultaten te loggen voor latere analyse.
Andere testen
Naast het kopiëren van de gegevens naar de gepartitioneerde geclusterde columnstore-index die al bestond, met behulp van affiniteit, wilde ik ook een aantal andere dingen proberen:
- De gegevens kopiëren naar de nieuwe tabel zonder te proberen de affiniteit te controleren. Ik haalde de affiniteitslogica uit de procedure en liet het hele "hoop-je-de-juiste-planner"-gedoe aan het toeval over. Dit duurde langer omdat, inderdaad, het stapelen van de planner deed voorkomen. Op dit specifieke punt voerde planner 3 bijvoorbeeld twee processen uit, terwijl planner 0 een lunchpauze nam:
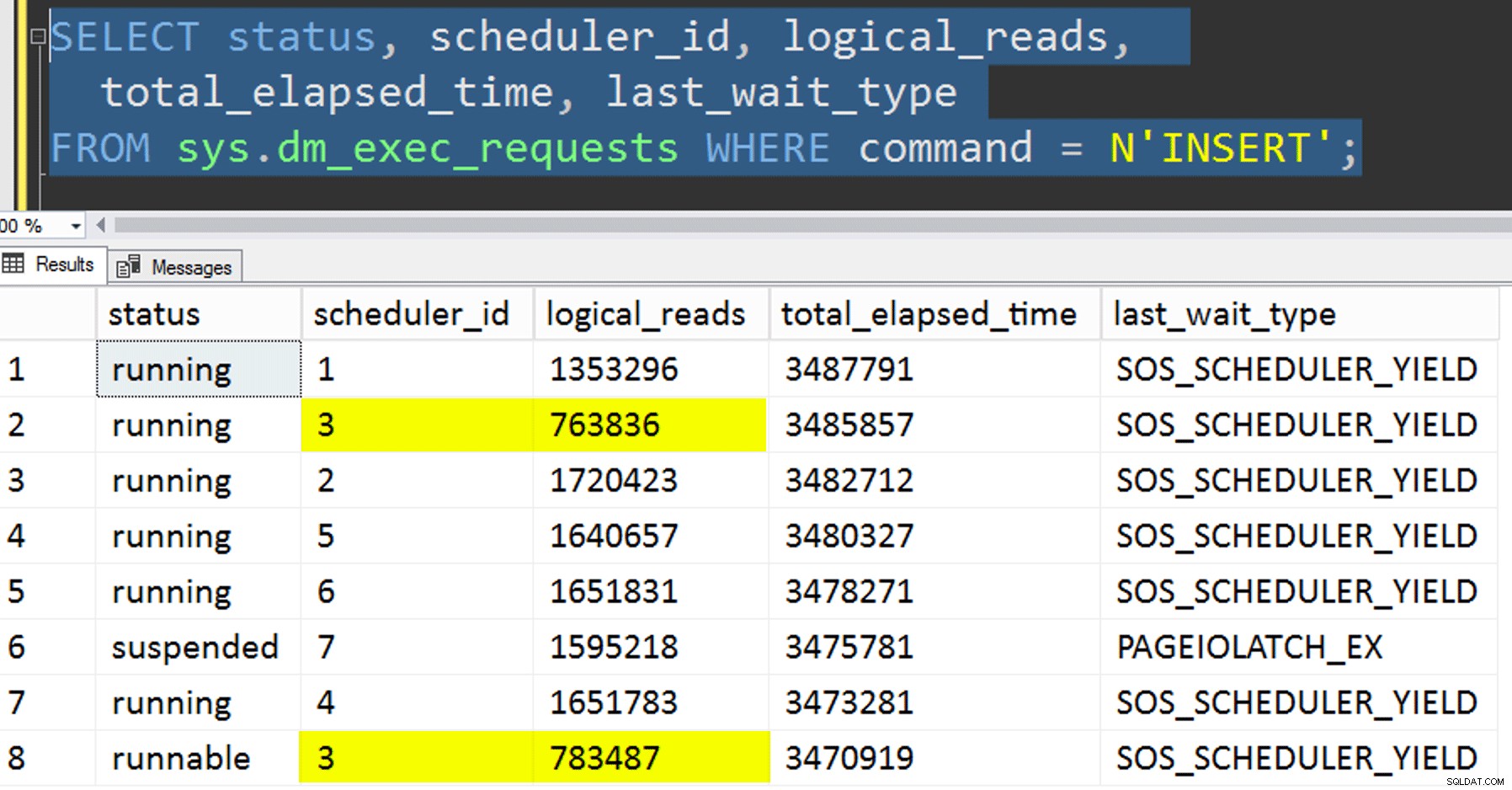 Waar ben je, planner nummer 0?
Waar ben je, planner nummer 0? - pagina toepassen of rij compressie (zowel online als offline) naar de bron voor de geaffinitiseerde kopie (offline), om te zien of het eerst comprimeren van de gegevens de bestemming zou kunnen versnellen. Merk op dat de kopie ook online kan worden gedaan, maar, zoals Andy Mallon's
intnaarbigintconversie, het vereist wat gymnastiek. Merk op dat we in dit geval geen voordeel kunnen halen uit de CPU-affiniteit (hoewel we dat wel zouden kunnen als de brontabel al gepartitioneerd was). Ik was slim en nam een back-up van de originele bron en creëerde een procedure om de database terug te zetten naar de oorspronkelijke staat. Veel sneller en gemakkelijker dan handmatig proberen terug te keren naar een specifieke status.-- refresh source, then do page online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do page offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = OFF); -- then run SQLQueryStress -- refresh source, then do row online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do row offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = OFF); -- then run SQLQueryStress
- En tot slot, eerst de geclusterde index opnieuw opbouwen op het partitieschema en daarbovenop de geclusterde columnstore-index bouwen. Het nadeel van de laatste is dat je dit in SQL Server 2017 niet online kunt uitvoeren ... maar in 2019 wel.
Hier moeten we eerst de PK-beperking laten vallen; je kunt
Msg 1907, niveau 16, staat 1DROP_EXISTINGniet gebruiken , aangezien de oorspronkelijke unieke beperking niet kan worden afgedwongen door de geclusterde columnstore-index, en u een unieke geclusterde index niet kunt vervangen door een niet-unieke geclusterde index.
Kan index 'pk_tblOriginal' niet opnieuw maken. De nieuwe indexdefinitie komt niet overeen met de beperking die wordt opgelegd door de bestaande index.Al deze details maken dit een proces in drie stappen, alleen de tweede stap online. De eerste stap heb ik alleen expliciet
OFFLINEgetest; dat liep in drie minuten, terwijlONLINEIk stopte na 15 minuten. Een van die dingen die in beide gevallen misschien geen data-omvang-operatie zouden moeten zijn, maar dat laat ik voor een andere dag.ALTER TABLE dbo.tblOriginal DROP CONSTRAINT PK_tblOriginal WITH (ONLINE = OFF); GO CREATE CLUSTERED INDEX CCI_tblOriginal -- yes, a bad name, but only temporarily ON dbo.tblOriginal(OID) WITH (ONLINE = ON) ON PS_OID (OID); -- this moves the data CREATE CLUSTERED COLUMNSTORE INDEX CCI_tblOriginal ON dbo.tblOriginal WITH ( DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) -- in 2019, CCI can be ONLINE = ON as well ) ON PS_OID (OID); GO
Resultaten
Timings en compressiesnelheden:
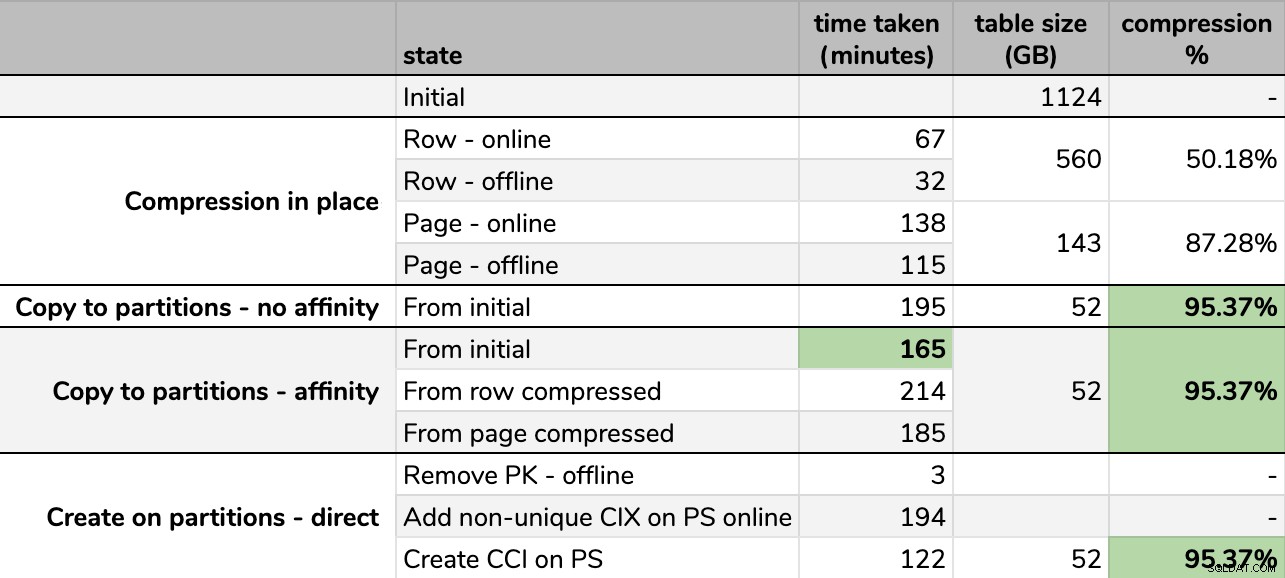 Sommige opties zijn beter dan andere
Sommige opties zijn beter dan andere
Merk op dat ik naar GB heb afgerond omdat er na elke run kleine verschillen in de uiteindelijke grootte zouden zijn, zelfs met dezelfde techniek. Ook waren de timings voor de affiniteitsmethoden gebaseerd op het gemiddelde individuele planner/batch-runtime, aangezien sommige planners sneller klaar zijn dan andere.
Het is moeilijk om je een exacte afbeelding voor te stellen van de spreadsheet zoals weergegeven, omdat sommige taken afhankelijkheden hebben, dus ik zal proberen de informatie weer te geven als een tijdlijn en te laten zien hoeveel compressie je krijgt in vergelijking met de tijd die je eraan besteedt:
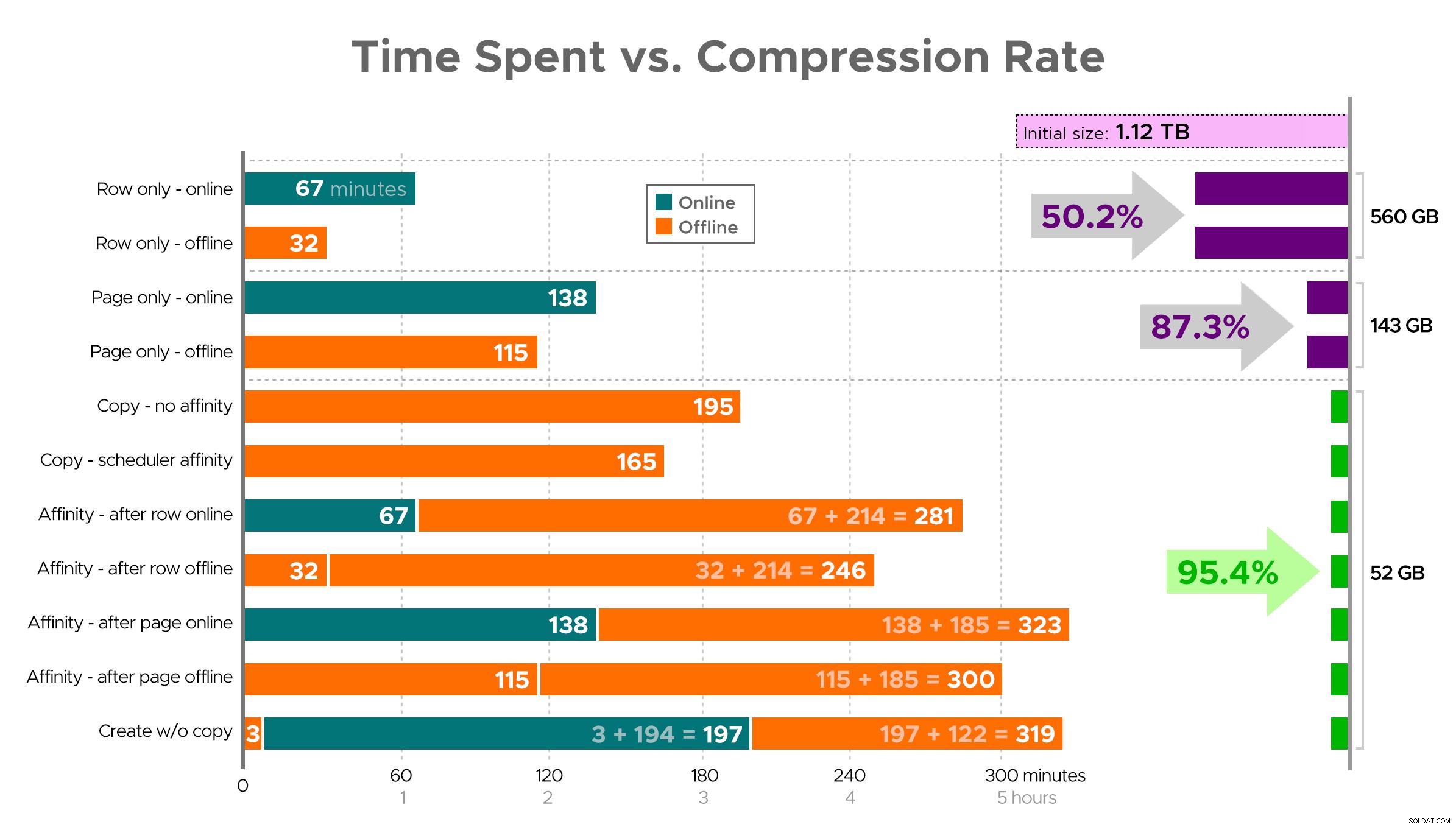 Bestede tijd (minuten) versus compressiesnelheid
Bestede tijd (minuten) versus compressiesnelheid
Een paar observaties uit de resultaten, met het voorbehoud dat uw gegevens anders kunnen worden gecomprimeerd (en dat online bewerkingen alleen op u van toepassing zijn als u Enterprise Edition gebruikt):
- Als uw prioriteit is om zo snel mogelijk wat ruimte te besparen , kunt u het beste op zijn plaats rijcompressie toepassen. Als u de hinder tot een minimum wilt beperken, gebruik dan online; als je de snelheid wilt optimaliseren, gebruik dan offline.
- Als u de compressie wilt maximaliseren zonder onderbreking , kunt u een opslagreductie van 90% bereiken zonder enige onderbreking door online paginacompressie te gebruiken.
- Als je de compressie wilt maximaliseren en onderbreking is oké , kopieert u de gegevens naar een nieuwe, gepartitioneerde versie van de tabel, met een geclusterde columnstore-index, en gebruikt u het hierboven beschreven affiniteitsproces om de gegevens te migreren. (En nogmaals, je kunt deze verstoring elimineren als je een betere planner bent dan ik.)
De laatste optie werkte het beste voor mijn scenario, hoewel we nog steeds de banden op de werklast moeten schoppen (ja, meervoud). Houd er ook rekening mee dat deze techniek in SQL Server 2019 misschien niet zo goed werkt, maar je kunt daar online geclusterde columnstore-indexen bouwen, dus het maakt misschien niet zoveel uit.
Sommige van deze benaderingen kunnen voor u min of meer acceptabel zijn, omdat u de voorkeur geeft aan "beschikbaar blijven" boven "zo snel mogelijk klaar zijn", of "het minimaliseren van schijfgebruik" boven "beschikbaar blijven", of gewoon de leesprestaties en schrijfoverhead in evenwicht houden .
Als je meer details wilt over een aspect hiervan, vraag het dan gewoon. Ik heb een deel van het vet bijgesneden om details en verteerbaarheid in evenwicht te brengen, en ik heb me eerder vergist in die balans. Een afscheidsgedachte is dat ik benieuwd ben hoe lineair dit is - we hebben een andere tafel met een vergelijkbare structuur van meer dan 25 TB, en ik ben benieuwd of we daar een vergelijkbare impact kunnen hebben. Tot dan, veel plezier met comprimeren!
[ Deel 1 | Deel 2 | Deel 3 ]