Dit artikel is de derde aflevering in een serie over NULL-complexiteit. In deel 1 heb ik de betekenis van de NULL-markering behandeld en hoe deze zich gedraagt in vergelijkingen. In deel 2 beschreef ik de inconsistenties van de NULL-behandeling in verschillende taalelementen. Deze maand beschrijf ik krachtige standaard NULL-verwerkingsfuncties die nog T-SQL moeten halen, en de tijdelijke oplossingen die mensen momenteel gebruiken.
Ik zal de voorbeelddatabase TSQLV5 zoals vorige maand in sommige van mijn voorbeelden blijven gebruiken. U vindt het script dat deze database maakt en vult hier, en het ER-diagram hier.
DISTINCT predikaat
In deel 1 van de serie heb ik uitgelegd hoe NULL's zich gedragen in vergelijkingen en de complexiteit rond de driewaardige predikaatlogica die SQL en T-SQL gebruiken. Overweeg het volgende predikaat:
X =YAls een predicand NULL is — ook wanneer beide NULL zijn — is de uitkomst van dit predikaat de logische waarde UNKNOWN. Met uitzondering van de operators IS NULL en IS NOT NULL, geldt hetzelfde voor alle andere operators, inclusief anders dan (<>):
X <> YIn de praktijk wil je vaak dat NULL's zich net zo gedragen als niet-NULL-waarden voor vergelijkingsdoeleinden. Dat is vooral het geval wanneer je ze gebruikt om ontbrekend maar niet van toepassing weer te geven waarden. De standaard heeft een oplossing voor deze behoefte in de vorm van een functie genaamd het DISTINCT-predikaat, dat de volgende vorm gebruikt:
In plaats van gelijkheids- of ongelijkheidssemantiek te gebruiken, gebruikt dit predikaat op onderscheid gebaseerde semantiek bij het vergelijken van predicanden. Als alternatief voor een gelijkheidsoperator (=), zou u het volgende formulier gebruiken om een TRUE te krijgen wanneer de twee predicanden hetzelfde zijn, inclusief wanneer beide NULL's zijn, en een ONWAAR wanneer ze dat niet zijn, inclusief wanneer één NULL is en de andere niet:
X IS NIET ONDERSCHEIDEN VAN YAls alternatief voor een anders dan operator (<>), zou u het volgende formulier gebruiken om een TRUE te krijgen wanneer de twee predicanden verschillend zijn, inclusief wanneer de ene NULL is en de andere niet, en een FALSE wanneer ze hetzelfde zijn, inclusief wanneer beide NULL zijn:
X IS VERSCHILLEND VAN YLaten we het predikaat DISTINCT toepassen op de voorbeelden die we in deel 1 van de serie hebben gebruikt. Bedenk dat u een query moest schrijven die gegeven een invoerparameter @dt bestellingen retourneert die op de invoerdatum zijn verzonden als deze niet-NULL is, of die helemaal niet zijn verzonden als de invoer NULL is. Volgens de norm zou u de volgende code met het predikaat DISTINCT gebruiken om aan deze behoefte te voldoen:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT DISTINCT FROM @dt;
Onthoud voor nu uit deel 1 dat je een combinatie van het EXISTS-predikaat en de INTERSECT-operator kunt gebruiken als een SARGable-oplossing in T-SQL, zoals zo:
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Om bestellingen te retourneren die zijn verzonden op een andere datum dan (anders dan) de invoerdatum @dt, gebruikt u de volgende vraag:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS DISTINCT FROM @dt;
De tijdelijke oplossing die wel werkt in T-SQL gebruikt een combinatie van het EXISTS-predikaat en de EXCEPT-operator, zoals:
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
In deel 1 heb ik ook scenario's besproken waarin je tabellen moet samenvoegen en op onderscheid gebaseerde semantiek moet toepassen in het join-predikaat. In mijn voorbeelden gebruikte ik tabellen genaamd T1 en T2, met NULLable join-kolommen genaamd k1, k2 en k3 aan beide zijden. Volgens de standaard zou je de volgende code gebruiken om zo'n join af te handelen:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON T1.k1 IS NOT DISTINCT FROM T2.k1 AND T1.k2 IS NOT DISTINCT FROM T2.k2 AND T1.k3 IS NOT DISTINCT FROM T2.k3;
Voor nu kun je, net als bij de vorige filtertaken, een combinatie van het EXISTS-predikaat en de INTERSECT-operator in de ON-component van de join gebruiken om het distinct-predikaat in T-SQL te emuleren, zoals:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);
Bij gebruik in een filter is dit formulier SARGable en bij gebruik in joins kan dit formulier mogelijk vertrouwen op indexvolgorde.
Als u het predikaat DISTINCT aan T-SQL wilt toevoegen, kunt u hier op stemmen.
Als je je na het lezen van dit gedeelte nog steeds een beetje ongemakkelijk voelt over het predikaat DISTINCT, ben je niet de enige. Misschien is dit predikaat veel beter dan elke bestaande tijdelijke oplossing die we momenteel hebben in T-SQL, maar het is een beetje uitgebreid en een beetje verwarrend. Het gebruikt een negatieve vorm om toe te passen wat in onze gedachten een positieve vergelijking is, en vice versa. Nou, niemand heeft gezegd dat alle standaardsuggesties perfect zijn. Zoals Charlie opmerkte in een van zijn opmerkingen bij Deel 1, zou de volgende vereenvoudigde vorm beter werken:
Het is beknopt en veel intuïtiever. In plaats van X IS NIET ONDERSCHEIDEN VAN Y, zou je het volgende gebruiken:
X IS YEn in plaats van X IS ONDERSCHEIDEN VAN Y, zou je gebruiken:
X IS NIET JIJDeze voorgestelde operator is feitelijk afgestemd op de reeds bestaande IS NULL- en IS NOT NULL-operatoren.
Toegepast op onze querytaak, om bestellingen te retourneren die op de invoerdatum zijn verzonden (of die niet zijn verzonden als de invoer NULL is), gebruikt u de volgende code:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS @dt;
Om bestellingen te retourneren die zijn verzonden op een andere datum dan de ingevoerde datum, gebruikt u de volgende code:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT @dt;
Als Microsoft ooit besluit om het onderscheidende predikaat toe te voegen, zou het goed zijn als ze zowel de standaard uitgebreide vorm als deze niet-standaard maar beknoptere en intuïtievere vorm zouden ondersteunen. Vreemd genoeg ondersteunt de queryprocessor van SQL Server al een interne vergelijkingsoperator IS, die dezelfde semantiek gebruikt als de gewenste IS-operator die ik hier heb beschreven. U kunt details over deze operator vinden in Paul White's artikel Undocumented Query Plans:Equality Comparisons (zoek "IS in plaats van EQ"). Wat ontbreekt, is het extern blootleggen als onderdeel van T-SQL.
NULL-behandelingsclausule (IGNORE NULLS | RESPECT NULLS)
Wanneer u de offset-vensterfuncties LAG, LEAD, FIRST_VALUE en LAST_VALUE gebruikt, moet u soms het NULL-behandelingsgedrag regelen. Deze functies retourneren standaard het resultaat van de gevraagde expressie op de gevraagde positie, ongeacht of het resultaat van de expressie een werkelijke waarde of een NULL is. Soms wilt u echter doorgaan in de relevante richting (achteruit voor LAG en LAST_VALUE, vooruit voor LEAD en FIRST_VALUE), en de eerste niet-NULL-waarde retourneren, indien aanwezig, en anders NULL. De standaard geeft u controle over dit gedrag met behulp van een NULL-behandelingsclausule met de volgende syntaxis:
offset_function(De standaardinstelling in het geval dat de NULL-behandelingsclausule niet is opgegeven, is de RESPECT NULLS-optie, wat betekent dat alles wordt geretourneerd wat aanwezig is in de gevraagde positie, zelfs als NULL. Helaas is deze clausule nog niet beschikbaar in T-SQL. Ik zal voorbeelden geven voor de standaardsyntaxis met behulp van de LAG- en FIRST_VALUE-functies, evenals tijdelijke oplossingen die wel werken in T-SQL. U kunt vergelijkbare technieken gebruiken als u dergelijke functionaliteit nodig heeft met LEAD en LAST_VALUE.
Als voorbeeldgegevens gebruik ik een tabel met de naam T4 die u maakt en invult met de volgende code:
DROP TABLE IF EXISTS dbo.T4; GO CREATE TABLE dbo.T4 ( id INT NOT NULL CONSTRAINT PK_T4 PRIMARY KEY, col1 INT NULL ); INSERT INTO dbo.T4(id, col1) VALUES ( 2, NULL), ( 3, 10), ( 5, -1), ( 7, NULL), (11, NULL), (13, -12), (17, NULL), (19, NULL), (23, 1759);
Er is een veelvoorkomende taak waarbij de laatste relevante wordt geretourneerd waarde. Een NULL in col1 geeft geen verandering in de waarde aan, terwijl een niet-NULL-waarde een nieuwe relevante waarde aangeeft. U moet de laatste niet-NULL col1-waarde retourneren op basis van id-bestelling. Als u de standaard NULL-behandelingsclausule gebruikt, zou u de taak als volgt afhandelen:
SELECT id, col1, COALESCE(col1, LAG(col1) IGNORE NULLS OVER(ORDER BY id)) AS lastval FROM dbo.T4;
Dit is de verwachte output van deze zoekopdracht:
id col1 lastval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 -1 7 NULL -1 11 NULL -1 13 -12 -12 17 NULL -12 19 NULL -12 23 1759 1759
Er is een tijdelijke oplossing in T-SQL, maar deze omvat twee lagen vensterfuncties en een tabeluitdrukking.
In de eerste stap gebruikt u de MAX-vensterfunctie om een kolom met de naam grp te berekenen die de maximale id-waarde tot nu toe bevat wanneer col1 niet NULL is, zoals:
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; Deze code genereert de volgende uitvoer:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 5 7 NULL 5 11 NULL 5 13 -12 13 17 NULL 13 19 NULL 13 23 1759 23
Zoals je kunt zien, wordt er een unieke grp-waarde gemaakt wanneer er een wijziging is in de col1-waarde.
In de tweede stap definieert u een CTE op basis van de query uit de eerste stap. Vervolgens retourneert u in de buitenste query de maximale col1-waarde tot nu toe, binnen elke partitie gedefinieerd door grp. Dat is de laatste niet-NULL col1 waarde. Hier is de volledige oplossingscode:
WITH C AS
(
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
MAX(col1) OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS lastval
FROM C; Dat is duidelijk veel meer code en werk vergeleken met alleen maar IGNORE_NULLS zeggen.
Een andere veel voorkomende behoefte is om de eerste relevante waarde te retourneren. Stel in ons geval dat u de eerste niet-NULL col1-waarde tot nu toe moet retourneren op basis van id-bestelling. Als u de standaard NULL-behandelingsclausule gebruikt, zou u de taak afhandelen met de FIRST_VALUE-functie en de IGNORE NULLS-optie, zoals:
SELECT id, col1,
FIRST_VALUE(col1) IGNORE NULLS
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM dbo.T4; Dit is de verwachte output van deze zoekopdracht:
id col1 firstval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 10 7 NULL 10 11 NULL 10 13 -12 10 17 NULL 10 19 NULL 10 23 1759 10
De tijdelijke oplossing in T-SQL gebruikt een vergelijkbare techniek als de techniek die werd gebruikt voor de laatste niet-NULL-waarde, alleen in plaats van een dubbele MAX-benadering, gebruikt u de FIRST_VALUE-functie bovenop een MIN-functie.
In de eerste stap gebruikt u de MIN-vensterfunctie om een kolom met de naam grp te berekenen die de minimale id-waarde tot nu toe bevat wanneer col1 niet NULL is, zoals:
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; Deze code genereert de volgende uitvoer:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 3 7 NULL 3 11 NULL 3 13 -12 3 17 NULL 3 19 NULL 3 23 1759 3
Als er NULL's aanwezig zijn voorafgaand aan de eerste relevante waarde, krijg je twee groepen:de eerste met de NULL als de grp-waarde en de tweede met de eerste niet-NULL-id als de grp-waarde.
In de tweede stap plaatst u de code van de eerste stap in een tabeluitdrukking. Dan gebruik je in de buitenste query de FIRST_VALUE-functie, gepartitioneerd door grp, om de eerste relevante (niet-NULL) waarde te verzamelen, indien aanwezig, en anders NULL, zoals zo:
WITH C AS
(
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
FIRST_VALUE(col1)
OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM C; Nogmaals, dat is veel code en werk vergeleken met het gebruik van de optie IGNORE_NULLS.
Als u denkt dat deze functie nuttig voor u kan zijn, kunt u hier stemmen voor opname in T-SQL.
BESTEL EERST OP NULLEN | NULLEN LAATSTE
Wanneer u gegevens bestelt, of het nu voor presentatiedoeleinden, windowing, TOP/OFFSET-FETCH-filtering of enig ander doel is, is er de vraag hoe NULL's zich in deze context zouden moeten gedragen? De SQL-standaard zegt dat NULL's voor of na niet-NULL's moeten worden gesorteerd, en ze laten het aan de implementatie over om op de een of andere manier te bepalen. Wat de leverancier echter ook kiest, het moet consistent zijn. In T-SQL worden NULL's eerst geordend (vóór niet-NULL's) bij gebruik van oplopende volgorde. Beschouw de volgende vraag als voorbeeld:
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate, orderid;
Deze query genereert de volgende uitvoer:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06
De uitvoer laat zien dat niet-verzonden bestellingen, die een NULL-verzenddatum hebben, bestellen vóór verzonden bestellingen, die een bestaande toepasselijke verzenddatum hebben.
Maar wat als u NULL's nodig hebt om als laatste te bestellen bij gebruik van oplopende volgorde? De ISO/IEC SQL-standaard ondersteunt een clausule die u toepast op een bestelexpressie die bepaalt of NULL's als eerste of als laatste worden gerangschikt. De syntaxis van deze clausule is:
Om aan onze behoefte te voldoen, moet u de bestellingen retourneren, gesorteerd op hun verzenddatum, oplopend, maar met niet-verzonden bestellingen die als laatste zijn geretourneerd, en vervolgens op hun bestellings-ID's als een tiebreaker, zou u de volgende code gebruiken:
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate NULLS LAST, orderid;
Helaas is deze NULLS-bestellingsclausule niet beschikbaar in T-SQL.
Een veelvoorkomende tijdelijke oplossing die mensen gebruiken in T-SQL is om de volgorde-expressie vooraf te laten gaan door een CASE-expressie die een constante retourneert met een lagere bestelwaarde voor niet-NULL-waarden dan voor NULL's, zoals (we noemen deze oplossing Query 1):
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY CASE WHEN shippeddate IS NOT NULL THEN 0 ELSE 1 END, shippeddate, orderid;
Deze query genereert de gewenste uitvoer waarbij NULL's als laatste worden weergegeven:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 11008 NULL 11019 NULL 11039 NULL ...
Er is een dekkingsindex gedefinieerd in de tabel Sales.Orders, met de kolom met de verzenddatum als sleutel. Net zoals een gemanipuleerde filterkolom de SARG-baarheid van het filter en de mogelijkheid om een zoekindex toe te passen verhindert, verhindert een gemanipuleerde bestelkolom echter de mogelijkheid om te vertrouwen op indexvolgorde om de ORDER BY-clausule van de query te ondersteunen. Daarom genereert SQL Server een plan voor Query 1 met een expliciete Sort-operator, zoals weergegeven in Afbeelding 1.
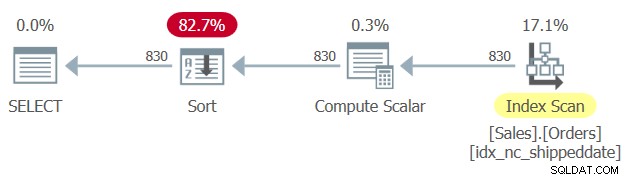 Figuur 1:Plan voor Query 1
Figuur 1:Plan voor Query 1
Soms is de omvang van de gegevens niet zo groot dat de expliciete sortering een probleem is. Maar soms is het dat wel. Met expliciete sortering wordt de schaalbaarheid van de query extra-lineair (je betaalt meer per rij, hoe meer rijen je hebt), en de reactietijd (tijd die nodig is om de eerste rij te retourneren) wordt vertraagd.
Er is een truc die u kunt gebruiken om expliciete sortering in een dergelijk geval te voorkomen met een oplossing die wordt geoptimaliseerd met behulp van een orderbehoudende Merge Join Concatenation-operator. U vindt een gedetailleerde beschrijving van deze techniek die in verschillende scenario's wordt gebruikt in SQL Server:Een sortering vermijden met samenvoegen Samenvoegen van samenvoegen. De eerste stap in de oplossing verenigt de resultaten van twee query's:één query die de rijen retourneert waar de volgordekolom niet NULL is met een resultaatkolom (we noemen het sortcol) op basis van een constante met een bestelwaarde, zeg 0, en een andere query die de rijen retourneert met de NULL's, met sortcol ingesteld op een constante met een hogere bestelwaarde dan in de eerste query, zeg 1. In de tweede stap definieert u vervolgens een tabeluitdrukking op basis van de code uit de eerste stap, en vervolgens in de buitenste query ordent u de rijen uit de tabeluitdrukking eerst op sortcol en vervolgens op de resterende volgorde-elementen. Hier is de code van de volledige oplossing die deze techniek implementeert (we noemen deze oplossing Query 2):
WITH C AS ( SELECT orderid, shippeddate, 0 AS sortcol FROM Sales.Orders WHERE shippeddate IS NOT NULL UNION ALL SELECT orderid, shippeddate, 1 AS sortcol FROM Sales.Orders WHERE shippeddate IS NULL ) SELECT orderid, shippeddate FROM C ORDER BY sortcol, shippeddate, orderid;
Het plan voor deze zoekopdracht wordt getoond in figuur 2.
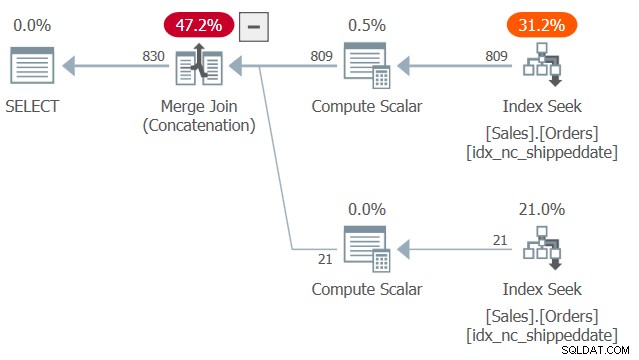 Figuur 2:Plan voor Query 2
Figuur 2:Plan voor Query 2
Merk op dat er twee zoek- en geordende bereikscans zijn in de dekkende index idx_nc_shippeddate:de ene trekt de rijen waar de verzenddatum niet NULL is en de andere trekt de rijen waar de verzenddatum NULL is. Vervolgens, vergelijkbaar met de manier waarop het Merge Join-algoritme in een join werkt, verenigt het Merge Join (Concatenation)-algoritme de rijen van de twee geordende zijden op een ritssluiting-achtige manier, en behoudt de opgenomen volgorde om de presentatie-ordeningsbehoeften van de query te ondersteunen. Ik zeg niet dat deze techniek altijd sneller is dan de meer typische oplossing met de CASE-expressie, die expliciete sortering gebruikt. De eerste heeft echter lineaire schaling en de laatste heeft n log n schaling. Dus de eerste zal het beter doen met grote aantallen rijen en de laatste met kleine aantallen.
Het is natuurlijk goed om een oplossing te hebben voor deze veelvoorkomende behoefte, maar het zal veel beter zijn als T-SQL in de toekomst ondersteuning toevoegt voor de standaard NULL-bestellingsclausule.
Conclusie
De ISO/IEC SQL-standaard heeft nogal wat NULL-verwerkingsfuncties die de T-SQL nog moeten bereiken. In dit artikel heb ik er een aantal behandeld:het predikaat DISTINCT, de NULL-behandelingsclausule en het bepalen of NULL's als eerste of als laatste worden besteld. Ik heb ook tijdelijke oplossingen gegeven voor deze functies die worden ondersteund in T-SQL, maar ze zijn duidelijk omslachtig. Volgende maand ga ik verder met de discussie door de standaard unieke beperking te bespreken, hoe deze verschilt van de T-SQL-implementatie en de tijdelijke oplossingen die in T-SQL kunnen worden geïmplementeerd.