Overzicht
Dit artikel bespreekt twee verschillende benaderingen die beschikbaar zijn om dubbele rijen uit SQL-tabel(len) te verwijderen, wat in de loop van de tijd vaak moeilijk wordt naarmate de gegevens groeien als dit niet op tijd gebeurt.
De aanwezigheid van dubbele rijen is een veelvoorkomend probleem waarmee SQL-ontwikkelaars en testers van tijd tot tijd worden geconfronteerd, maar deze dubbele rijen vallen in een aantal verschillende categorieën die we in dit artikel gaan bespreken.
Dit artikel richt zich op een specifiek scenario, waarbij gegevens die in een databasetabel worden ingevoegd, leiden tot de introductie van dubbele records. Vervolgens zullen we methoden voor het verwijderen van duplicaten nader bekijken en uiteindelijk de duplicaten verwijderen met behulp van deze methoden.
Voorbereiding van voorbeeldgegevens
Voordat we beginnen met het verkennen van de verschillende beschikbare opties om duplicaten te verwijderen, is het op dit punt de moeite waard om een voorbeelddatabase op te zetten die ons zal helpen de situaties te begrijpen waarin dubbele gegevens in het systeem terechtkomen en de benaderingen die moeten worden gebruikt om deze uit te roeien .
Sampledatabase instellen (UniversityV2)
Begin met het maken van een zeer eenvoudige database die alleen uit een Student . bestaat tabel aan het begin.
-- (1) Create UniversityV2 sample database
CREATE DATABASE UniversityV2;
GO
USE UniversityV2
CREATE TABLE [dbo].[Student] (
[StudentId] INT IDENTITY (1, 1) NOT NULL,
[Name] VARCHAR (30) NULL,
[Course] VARCHAR (30) NULL,
[Marks] INT NULL,
[ExamDate] DATETIME2 (7) NULL,
CONSTRAINT [PK_Student] PRIMARY KEY CLUSTERED ([StudentId] ASC)
);
Studententabel vullen
Laten we slechts twee records toevoegen aan de tabel Student:
-- Adding two records to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (1, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (2, N'Peter', N'Database Management System', 85, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Gegevenscontrole
Bekijk de tabel die op dit moment twee verschillende records bevat:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
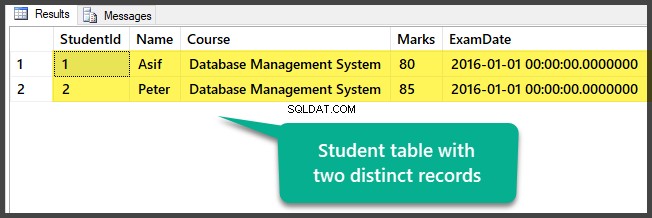
U hebt de voorbeeldgegevens met succes voorbereid door een database op te zetten met één tabel en twee verschillende (verschillende) records.
We gaan nu enkele mogelijke scenario's bespreken waarin duplicaten werden geïntroduceerd en verwijderd, van eenvoudige tot enigszins complexe situaties.
Case 01:Duplicaten toevoegen en verwijderen
Nu gaan we dubbele rij(en) introduceren in de Student-tabel.
Voorwaarden
In dit geval wordt gezegd dat een tabel dubbele records heeft als de Naam . van een leerling , Cursus , Markeringen , en ExamenDatum samenvallen in meer dan één records, zelfs als de student-ID is anders.
We gaan er dus van uit dat geen twee studenten dezelfde naam, cursus, cijfers en examendatum kunnen hebben.
Dubbele gegevens toevoegen voor Asif student
Laten we bewust een dubbel record invoegen voor Leerling:Asif aan de Student tabel als volgt:
-- Adding Student Asif duplicate record to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (3, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Dubbele leerlinggegevens bekijken
Bekijk de Student tabel om dubbele records te zien:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
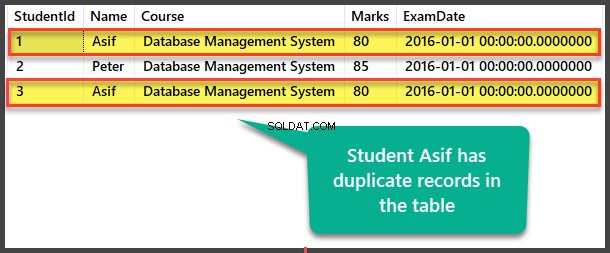
Duplicaten zoeken met zelfverwijzende methode
Wat als er duizenden records in deze tabel staan, dan zal het niet veel helpen om de tabel te bekijken.
Bij de zelfverwijzende methode nemen we twee verwijzingen naar dezelfde tabel en voegen we ze samen met behulp van kolom-voor-kolom toewijzing, met uitzondering van de ID die kleiner of groter is dan de andere.
Laten we eens kijken naar de zelfverwijzende methode om duplicaten te vinden die er als volgt uitziet:
USE UniversityV2
-- Self-Referencing method to finding duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1,[dbo].[Student] S2
WHERE S1.StudentId<S2.StudentId AND
S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
De uitvoer van het bovenstaande script toont ons alleen de dubbele records:

Duplicaten vinden door zelfverwijzende methode-2
Een andere manier om duplicaten te vinden met behulp van zelfreferentie is om INNER JOIN als volgt te gebruiken:
-- Self-Referencing method 2 to find duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
INNER JOIN
[dbo].[Student] S2
ON S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
WHERE S1.StudentId<S2.StudentId

Duplicaten verwijderen door zelfverwijzende methode
We kunnen de duplicaten verwijderen met dezelfde methode die we hebben gebruikt om duplicaten te vinden, met uitzondering van het gebruik van DELETE in overeenstemming met de syntaxis als volgt:
USE UniversityV2
-- Removing duplicates by using Self-Referencing method
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
Gegevenscontrole na verwijdering van duplicaten
Laten we snel de records controleren nadat we de duplicaten hebben verwijderd:
USE UniversityV2
-- View Student data after duplicates have been removed
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
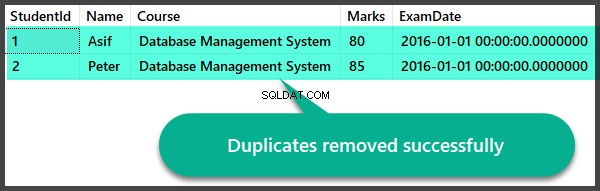
Duplicaat maken Bekijk en verwijder Duplicaten opgeslagen procedure
Nu we weten dat onze scripts met succes dubbele rijen in SQL kunnen vinden en verwijderen, is het voor het gebruiksgemak beter om ze in een view en opgeslagen procedure om te zetten:
USE UniversityV2;
GO
-- Creating view find duplicate students having same name, course, marks, exam date using Self-Referencing method
CREATE VIEW dbo.Duplicates
AS
SELECT
S1.[StudentId] AS S1_StudentId
,S2.StudentId AS S2_StudentID
,S1.Name AS S1_Name
,S2.Name AS S2_Name
,S1.Course AS S1_Course
,S2.Course AS S2_Course
,S1.ExamDate AS S1_ExamDate
,S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
,[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
GO
-- Creating stored procedure to removing duplicates by using Self-Referencing method
CREATE PROCEDURE UspRemoveDuplicates
AS
BEGIN
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
END
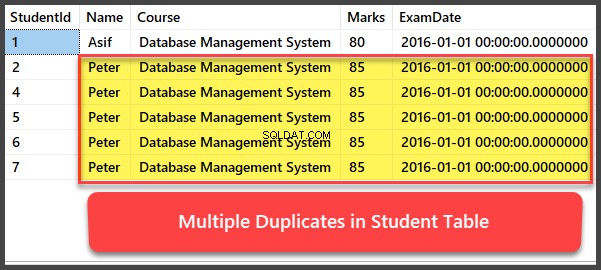
Meerdere dubbele records toevoegen en bekijken
Laten we nu nog vier records toevoegen aan de Student tabel en alle records zijn zodanig dubbel dat ze dezelfde naam, cursus, cijfers en examendatum hebben:
--Adding multiple duplicates to Student table
INSERT INTO Student (Name,
Course,
Marks,
ExamDate)
VALUES ('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01');
-- Viewing Student table after multiple records have been added to Student table
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Duplicaten verwijderen met behulp van de UspRemoveDuplicates-procedure
USE UniversityV2
-- Removing multiple duplicates
EXEC UspRemoveDuplicates
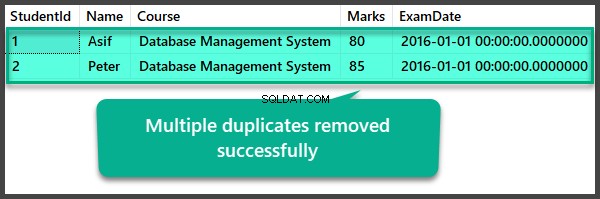
Gegevenscontrole na verwijdering van meerdere duplicaten
USE UniversityV2
--View Student table after multiple duplicates removal
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Case 02:Duplicaten met dezelfde ID's toevoegen en verwijderen
Tot nu toe hebben we dubbele records geïdentificeerd met verschillende ID's, maar wat als de ID's hetzelfde zijn.
Denk bijvoorbeeld aan het scenario waarin onlangs een tabel is geïmporteerd uit een tekst- of Excel-bestand dat geen primaire sleutel heeft.
Voorwaarden
In dit geval wordt gezegd dat een tabel dubbele records heeft als alle kolomwaarden exact hetzelfde zijn, inclusief een ID-kolom en de primaire sleutel ontbreekt, waardoor het gemakkelijker werd om de dubbele records in te voeren.
Cursustabel maken zonder primaire sleutel
Om het scenario te reproduceren waarin dubbele records bij afwezigheid van een primaire sleutel in een tabel vallen, laten we eerst een nieuwe Cursus maken tabel zonder enige primaire sleutel in de University2-database als volgt:
USE UniversityV2
-- Creating Course table without primary key
CREATE TABLE [dbo].[Course] (
[CourseId] INT NOT NULL,
[Name] VARCHAR (30) NOT NULL,
[Detail] VARCHAR (200) NULL,
);
Cursustabel invullen
-- Populating Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (2, N'Tabular Data Modeling', N'This is about Tabular Data Modeling')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (3, N'Analysis Services Fundamentals', N'This is about Analysis Services Fundamentals')
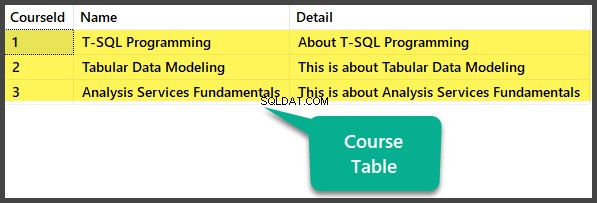
Gegevenscontrole
Bekijk de Cursus tafel:
USE UniversityV2
-- Viewing Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course
Dubbele gegevens toevoegen aan cursustabel
Voeg nu duplicaten toe aan de Cursus tafel:
USE UniversityV2
-- Inserting duplicate records in Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
Dubbele cursusgegevens bekijken
Selecteer alle kolommen om de tabel te bekijken:
USE UniversityV2
-- Viewing duplicate data in Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course

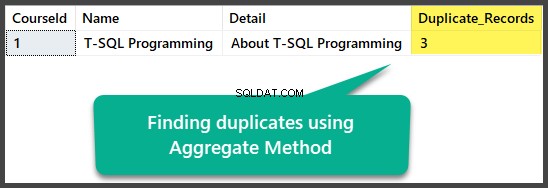
Duplicaten zoeken via de geaggregeerde methode
We kunnen exacte duplicaten vinden door de aggregatiemethode te gebruiken door alle kolommen te groeperen met een totaal van meer dan één na het selecteren van alle kolommen en het tellen van alle rijen met behulp van de aggregatietelling(*)functie:
-- Finding duplicates using Aggregate method
SELECT <column1>,<column2>,<column3>…
,COUNT(*) AS Total_Records
FROM <Table>
GROUP BY <column1>,<column2>,<column3>…
HAVING COUNT(*)>1
Dit kan als volgt worden toegepast:
USE UniversityV2
-- Finding duplicates using Aggregate method
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
Duplicaten verwijderen via de geaggregeerde methode
Laten we de duplicaten als volgt verwijderen met behulp van de aggregatiemethode:
USE UniversityV2
-- Removing duplicates using Aggregate method
-- (1) Finding duplicates and put them into a new table (CourseNew) as a single row
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records INTO CourseNew
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
-- (2) Rename Course (which contains duplicates) as Course_OLD
EXEC sys.sp_rename @objname = N'Course'
,@newname = N'Course_OLD'
-- (3) Rename CourseNew (which contains no duplicates) as Course
EXEC sys.sp_rename @objname = N'CourseNew'
,@newname = N'Course'
-- (4) Insert original distinct records into Course table from Course_OLD table
INSERT INTO Course (CourseId, Name, Detail)
SELECT
co.CourseId
,co.Name
,co.Detail
FROM Course_OLD co
WHERE co.CourseId <> (SELECT
c.CourseId
FROM Course c)
ORDER BY CO.CourseId
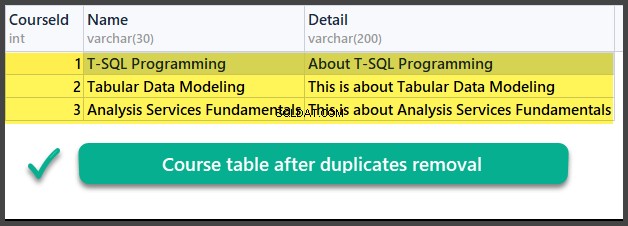
-- (4) Data check
SELECT
cn.CourseId
,cn.Name
,cn.Detail
FROM Course cn
-- Clean up
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
Gegevenscontrole
GEBRUIK UniversityV2
We hebben dus met succes geleerd hoe we duplicaten uit een databasetabel kunnen verwijderen met behulp van twee verschillende methoden op basis van twee verschillende scenario's.
Dingen om te doen
U kunt nu gemakkelijk een databasetabel identificeren en ontdoen van dubbele waarde.
1. Probeer de UspRemoveDuplicatesByAggregate . te maken opgeslagen procedure op basis van de hierboven genoemde methode en verwijder duplicaten door de opgeslagen procedure aan te roepen
2. Probeer de opgeslagen procedure die hierboven is gemaakt (UspRemoveDuplicatesByAggregates) aan te passen en implementeer opruimtips die in dit artikel worden genoemd.
DROP TABLE CourseNew
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
3. Kunt u er zeker van zijn dat de UspRemoveDuplicatesByAggregate opgeslagen procedure zo vaak mogelijk kan worden uitgevoerd, zelfs na het verwijderen van de duplicaten, om aan te tonen dat de procedure in de eerste plaats consistent blijft?
4. Raadpleeg mijn vorige artikel Jump to Start Test-Driven Database Development (TDDD) - Part 1 en probeer duplicaten in de SQLDevBlog-databasetabellen in te voegen, probeer daarna de duplicaten te verwijderen met behulp van beide methoden die in deze tip worden genoemd.
5. Probeer een andere voorbeelddatabase aan te maken EmployeesSample verwijs naar mijn vorige artikel Kunst van het isoleren van afhankelijkheden en gegevens in het testen van database-eenheden en voeg duplicaten in de tabellen in en probeer ze te verwijderen met behulp van beide methoden die u uit deze tip hebt geleerd.
Handig hulpmiddel:
dbForge Data Compare voor SQL Server - krachtige SQL-vergelijkingstool die met big data kan werken.